
使用二进制方式部署夜莺
使用二进制方式部署夜莺( Nightingale ),适合生产环境部署,本文讲解中心化部署方式,对于边缘机房部署模式会在后续文档中介绍
部署夜莺
可以去两个地方下载夜莺发布包,完事自行解压缩:
- github releases:更新会更频繁,国外地址,下载可能会慢一些
- flashcat 下载中心:更新会慢一些,国内地址,下载更快
注意:amd64.tar.gz 是 x86_64 架构的,arm64.tar.gz 是 arm64 架构的。根据自己的服务器架构选择下载。如果下载错了,启动的时候会报错:无法执行二进制文件。
准备依赖
根据「项目介绍」中的架构介绍,夜莺依赖 MySQL、Redis,需要各位提前准备好。这里也提供一个小脚本来安装这两个组件,大家可以参考。
# install mysql
yum -y install mariadb*
systemctl enable mariadb
systemctl restart mariadb
mysql -e "SET PASSWORD FOR 'root'@'localhost' = PASSWORD('1234');"
# install redis
yum install -y redis
systemctl enable redis
systemctl restart redis
上例中 mysql 的 root 密码设置为了 1234,测试阶段建议维持这个不变,后续就省去了修改配置文件的麻烦,等熟悉了上生产了再改为强密码。如果你想修改默认用户名和密码,就要对应的修改配置文件中的 mysql 连接信息,配置文件的哪个地方配置了 mysql 的密码呢?通过下面的命令可以找到:
# 夜莺的主配置文件是 etc/config.toml
grep "1234" etc/config.toml
夜莺配置文件中的 Redis 默认是配置的单机版,且无密码,如果想做调整,根据配置文件中的注释来修改即可。
导入数据库表结构
解压缩夜莺的 tar.gz 之后,可以看到 n9e.sql,这是数据库初始化 sql,需要导入到 mysql 中。
mysql -uroot -p1234 < n9e.sql
启动夜莺
解压缩夜莺的 tar.gz 之后,可以看到三个二进制:
- n9e:这是夜莺的服务端二进制
- n9e-edge:这是边缘机房部署模式时使用,后面会讲,现在不用管
- n9e-cli:这是 v5 升级 v6 版本时使用的命令行迁移工具,新用户也无需关心
另外可以看到几个目录:
- cli:v5 升级 v6 的时候用的,新用户无需关心
- etc:配置文件目录
- docker:docker 部署的时候用的,相关配置文件,相关 compose.yaml 文件都在这里,二进制部署无需关心
- integrations:集成目录。存放内置告警规则、内置仪表盘
启动夜莺很简单,直接执行 n9e 二进制即可:
./n9e
如果启动失败,会在控制台打印错误日志,根据错误日志来排查问题即可。
当然了,上面的启动方式,一旦关闭终端,夜莺就停止了,Ctrl + C 夜莺进程也会停止。如果想让夜莺在后台运行,可以使用 systemd 来管理。这里我仅做演示用 nohup 快速启动:
nohup ./n9e &> n9e.log &
如果启动成功,夜莺默认会监听在 17000 端口,通过下面的命令可以查看端口是否正常在监听:
ss -tlnp|grep 17000
通过下面的命令可以查看进程是否正常在运行:
ps -ef|grep n9e
查看日志
如果是 nohup 方式启动,在 n9e.log 中可以查看夜莺的日志。如果是 systemd 方式启动,可以通过 journalctl 来查看日志(假设 service 名字是 n9e):
journalctl -fu n9e
journalctl 具体如何使用请自行 Google。
把日志输出到指定目录(选做)
默认情况下夜莺的日志打印到 stdout,如果想把日志输出到指定目录,可以通过修改 config.toml 中的 [Log] 部分达成目的,比如:
[Log]
Dir = "logs"
Level = "INFO"
Output = "file"
KeepHours = 24
上面的配置表示,把日志输出到 logs 目录下,日志级别是 INFO,日志文件保留 24 小时。也可以根据大小来配置,比如:
[Log]
Dir = "logs"
Level = "INFO"
Output = "file"
RotateNum = 3
RotateSize = 256
上面的配置表示,把日志输出到 logs 目录下,日志级别是 INFO,日志文件大小超过 256M 时,会自动切割,保留 3 个日志文件。
访问夜莺
浏览器访问夜莺的端口,即 17000,默认用户是 root,密码是 root.2020
接入数据源
根据「项目介绍」中的架构介绍,上面的方式搭建的夜莺,只是作为一个告警引擎使用,此时你可以在页面(注意,这里是页面)上添加数据源(菜单路径:系统配置-数据源),看图、配置告警规则。如果想要用夜莺来接收监控数据并转存到时序库,那就得通过配置文件(注意,这里是配置文件)告诉夜莺时序库的地址在哪里。还记得之前的架构图不?
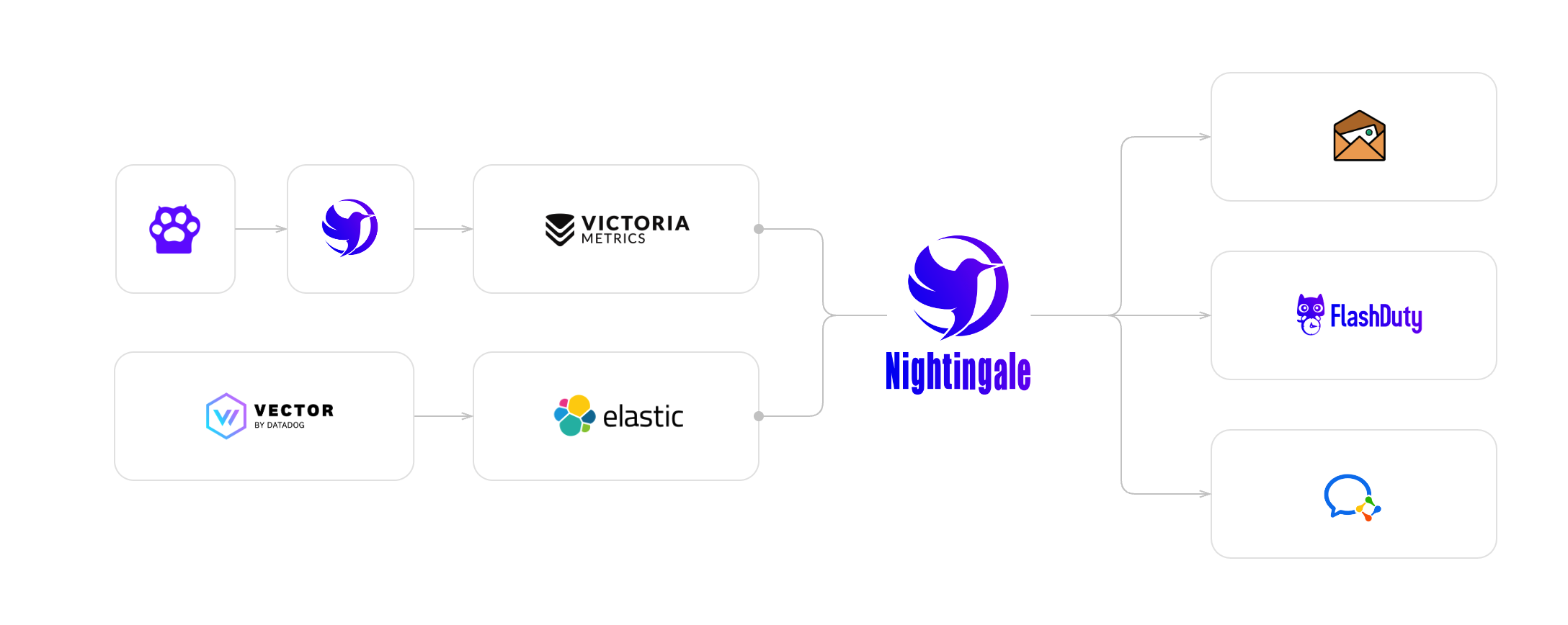
在这个架构下,夜莺进程有两个角色,一个是作为告警引擎,一个是作为数据转发的 pushgateway,这里首先需要一个时序库,可以使用 Prometheus 或 VictoriaMetrics(推荐)。夜莺接收到数据之后会通过 remote write 方式转发给时序库。
部署时序库
Prometheus
Prometheus 的搭建,这里不再赘述,网上资料很多,比如可以参考 这里。唯一要注意的时候,启动 Prometheus 的时候需要传入一个参数:--web.enable-remote-write-receiver,只有开了这个参数(老版本的参数是 --enable-feature=remote-write-receiver,可以通过 ./prometheus --help 查看你的 Prometheus 的配置方式),Prometheus 才能通过 remote write 方式接收监控数据,否则后面跟夜莺对接的话会报接口 404。
如果你之前已经有 Prometheus 了,可以直接使用(记得检查是否开启了 --web.enable-remote-write-receiver),如果之前没有 Prometheus,那就不用安装了,直接使用 VictoriaMetrics。
VictoriaMetrics
VictoriaMetrics 的搭建,更为简单,从 VictoriaMetrics github releases 下载对应平台的发布包,解压缩里边只有一个二进制,执行 ./victoria-metrics-prod 即可启动,生产环境建议使用 systemd 托管,这里提供一个 systemd 的 service 文件供大家参考:
# /etc/systemd/system/victoriametrics.service
[Unit]
Description="victoriametrics"
After=network.target
[Service]
Type=simple
ExecStart=/opt/victoriametrics/victoria-metrics-prod
Restart=on-failure
SuccessExitStatus=0
LimitNOFILE=65536
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=victoriametrics
[Install]
WantedBy=multi-user.target
VictoriaMetrics 默认会监听在 8428 端口,可以通过 http://IP:8428 访问 VictoriaMetrics 的 web 界面。
修改夜莺配置文件对接时序库
夜莺作为 pushgateway,需要告诉夜莺时序库的地址在哪里。夜莺的配置文件是 etc/config.toml,修改 [[Pushgw.Writers]] 部分即可,核心是 Url 部分,夜莺接收到指标数据之后,会通过 Prometheus remote write 协议写入 Url 指向的时序库(任何支持 Prometheus remote write 的存储都可以用),比如对接 VictoriaMetrics 单机版:
[[Pushgw.Writers]]
Url = "http://127.0.0.1:8428/api/v1/write"
注意上面的 IP 改成你自己环境的 VictoriaMetrics 的 IP,如果对接的是 Prometheus,则配置就是:
[[Pushgw.Writers]]
Url = "http://127.0.0.1:9090/api/v1/write"
注意上面的 IP 改成你自己环境的的 Prometheus 的 IP,如果对接的是集群版本的 VictoriaMetrics,则配置就是:
[[Pushgw.Writers]]
Url = "http://127.0.0.1:8480/insert/0/prometheus/api/v1/write"
注意上面的 IP 改成你自己环境的 vminsert 的 IP。[[Pushgw.Writers]] 这个部分是双中括号扩起来的,在 toml 配置中,表示数组,即 [[Pushgw.Writers]] 配置段可以有多个,这样夜莺接收到数据之后,就会把数据同时写到多个后端时序库。比如:
[[Pushgw.Writers]]
Url = "http://127.0.0.1:9090/api/v1/write"
BasicAuthUser = ""
BasicAuthPass = ""
[[Pushgw.Writers]]
Url = "http://127.0.0.1:8428/api/v1/write"
BasicAuthUser = ""
BasicAuthPass = ""
上例中就是配置了两个时序库。
最后,重启夜莺进程,就完成了夜莺和时序库的对接。
在页面添加数据源
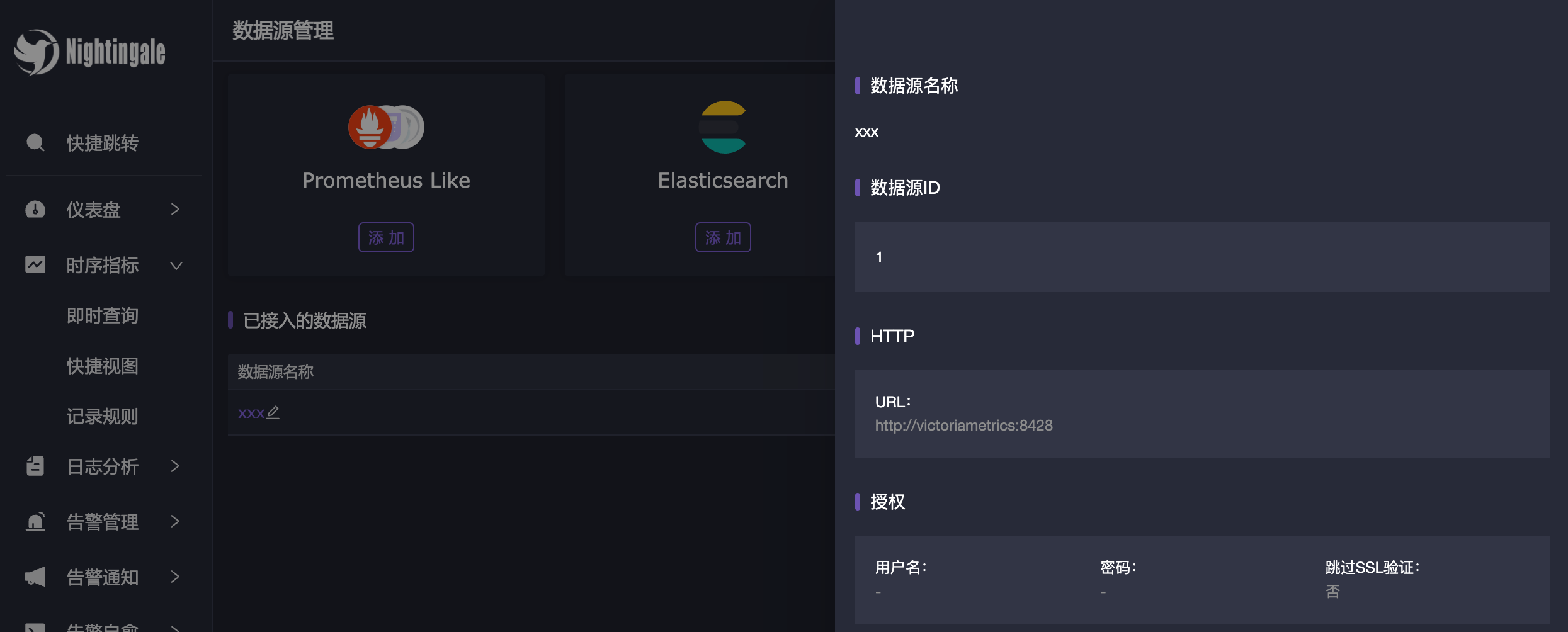
菜单操作入口:数据源。以 Prometheus Like 类型的数据源举例,创建页面填写的关键信息如下:
- 数据源名称:自定义的数据源名称
- URL:数据源的地址,页面上已经给了例子
- 超时时间:默认 10 秒,有的时候查询重量级 promql 10 秒可能不够,可以调大这个值,比如改成 30000 毫秒,即 30 秒
- 授权:用户名密码指的是数据源的 Basic auth 认证信息
- Remote write URL:如果用到了记录规则,记录规则产生的新指标会通过该地址回写时序库。比如 VictoriaMetrics 单机版的 remote write 地址是
http://IP:8428/api/v1/write,Prometheus 的 remote write 地址是http://IP:9090/api/v1/write,如果没有用到记录规则,这个字段可以忽略 - 时序库内网地址:通常用于边缘机房下沉部署告警引擎的场景,如果该字段不为空,n9e-edge 会使用该地址访问时序库,如果该字段为空,n9e-edge 会使用上面的 URL 访问时序库
- 关联告警引擎集群:如果只是部署了中心夜莺,这里就默认选择 default 即可,如果你当前添加的数据源是某个边缘机房的数据源,并且该边缘机房有专门的 n9e-edge 告警引擎,那么这里就选择对应的告警引擎集群,何为边缘机房部署模式?请参考前面的文档《附:边缘机房部署》
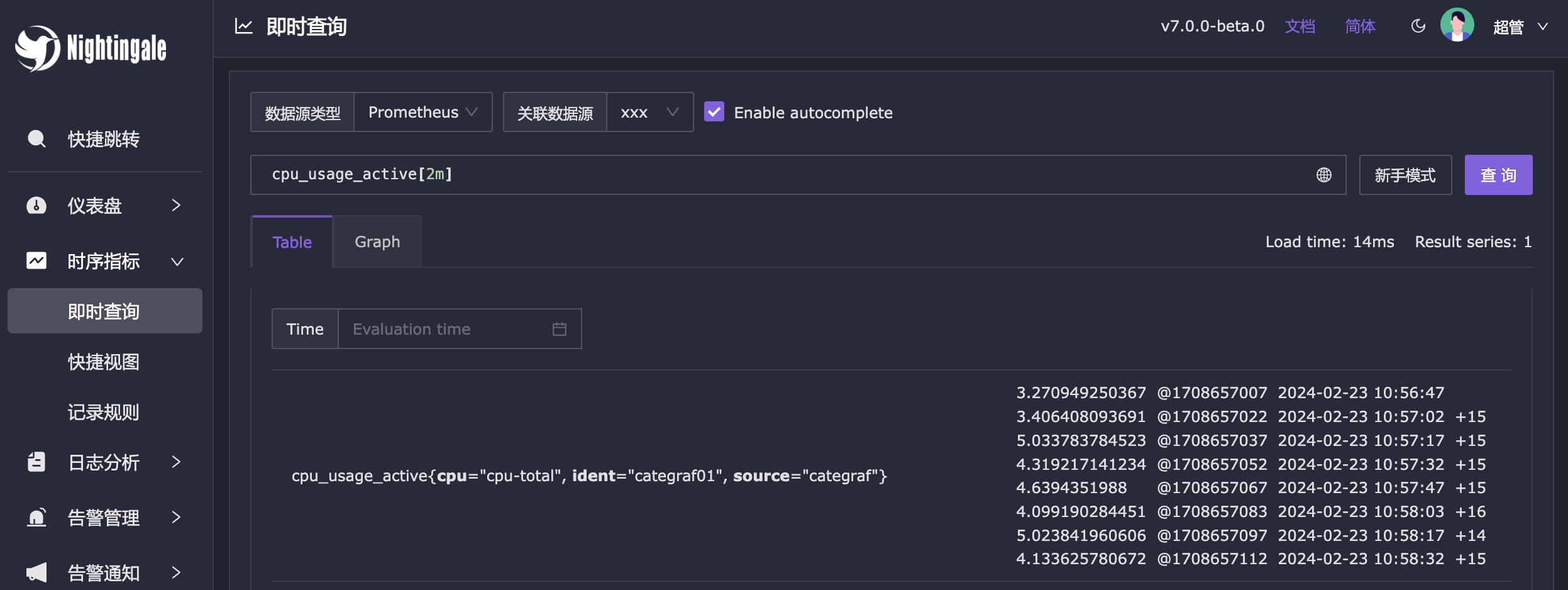
点击【测试并保存】,如果测试通过,就可以对这个数据源的数据看图、配告警规则了。比如我使用 docker compose bridge 部署的,时序库是 VictoriaMetrics,那么数据源 URL 就是 http://victoriametrics:8428,compose 中自动启动了 categraf 采集数据,配置完了数据源就可以立马去查看数据:
部署采集器
通过 Categraf 采集数据
对于要监控的目标机器,需要在每个机器上安装 Categraf,Categraf 是夜莺的数据采集器,相关资料:
Categraf 的主配置在 conf/config.toml,注意里边有两处 127.0.0.1:17000 就是夜莺的地址,需要改成你自己环境的夜莺地址。
Categraf 要安装在所有要监控的目标机器上,建议使用 ansible 之类的批量管理工具来安装。


