
夜莺中心汇聚式部署的数据流图是怎样的?
夜莺监控Nightingale中心汇聚式部署的数据流图是怎样的?夜莺监控Nightingale架构图是什么样的?
详细可以参考安装部署详解。 简单来说,中心汇聚式部署方案的数据流图如下所示。
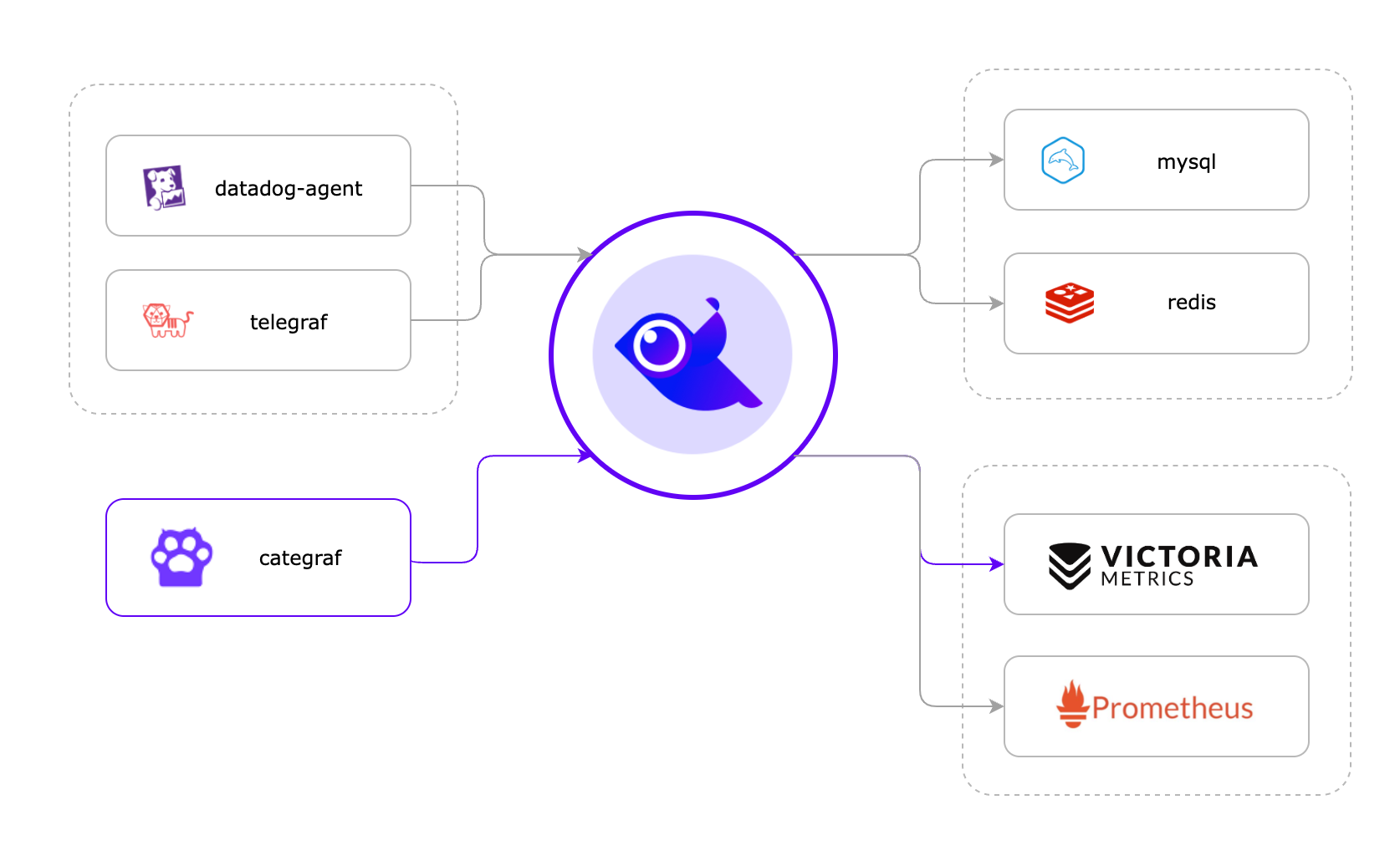
- Nightingale 可以接收各类 agent 作为采集器上报的监控数据,比如 datadog-agent、grafana-agent、telegraf、categraf
- Nightingale 往 mysql(也可以使用pg)的 target 表存储机器列表和心跳信息,并且通过这个信息判断机器是 UP 还是 DOWN
- Nightingale 把机器列表中操作系统、CPU 架构信息、CPU 利用率、内存利用率、时间偏移等元数据存储在 Redis 里
- Nightingale 把接收到的监控数据(时序数据)转发给后端时序库,时序库可以并行写入多个,比如 VictoriaMetrics、Prometheus、M3DB、Thanos、Mimir 等
💡 虽然不同 agent 采集的上报的数据中机器标识信息各不相同,但是都会被夜莺服务端统一处理,rename 为 ident 标签并写入时序库。比如 categraf 和 grafana-agent,原始的机器标识使用的是 agent_hostname 标签,telegraf 使用的是 host 标签,open-falcon 使用的 endpoint 字段,datadog-agent 使用的是 host 字段,但是在夜莺服务端都会被统一处理为 ident 标签。


