
MySQL 监控、MySQL 集群监控、使用 Categraf 和 夜莺监控 MySQL
说明如何用 Categraf 监控 MySQL,包括创建只读账号、插件配置、仪表盘导入、单机与集中采集两种模式,以及自定义 SQL 与标签筛选思路。
MySQL 监控概述
MySQL、Redis、MongoDB 等各类数据库的监控数据采集,原理类似,就是为 Categraf 创建一个 DB 账号,Categraf 用此账号连到数据库实例上,执行一些命令获取监控数据,比如连到 MySQL 上执行 show global status、show global variables 等命令。
创建 DB 账号
为了安全起见,建议为 Categraf 创建一个只读权限的 DB 账号:
CREATE USER 'categraf'@'127.0.0.1' IDENTIFIED BY 'XXXXXXXX' WITH MAX_USER_CONNECTIONS 3;
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'categraf'@'127.0.0.1';
当然,测试期间也可以使用 root 账号,但是生产环境不建议使用 root 账号。
快速入门
Categraf 内置各类监控插件,也内置了 MySQL 的监控插件,其配置文件在 Categraf 的 conf/input.mysql/mysql.toml,下面是一个极简配置内容:
[[instances]]
address = "127.0.0.1:3306"
username = "categraf"
password = "XXXXXXXX"
然后通过 Categraf 的 --test 命令可以测试配置是否正确:
./categraf --test --inputs mysql
输出如下:
ulric@ulric-flashcat categraf % ./categraf --test --inputs mysql
2024/11/20 14:23:35 main.go:149: I! runner.binarydir: /Users/ulric/works/gopath/src/categraf
2024/11/20 14:23:35 main.go:150: I! runner.hostname: ulric-flashcat.local
2024/11/20 14:23:35 main.go:151: I! runner.fd_limits: (soft=61440, hard=unlimited)
2024/11/20 14:23:35 main.go:152: I! runner.vm_limits: (soft=unlimited, hard=unlimited)
...
1732083816 14:23:36 mysql_up address=127.0.0.1:3306 agent_hostname=mac-ulric-flashcat 1
1732083816 14:23:36 mysql_global_status_aborted_clients address=127.0.0.1:3306 agent_hostname=mac-ulric-flashcat 0
1732083816 14:23:36 mysql_global_status_aborted_connects address=127.0.0.1:3306 agent_hostname=mac-ulric-flashcat 1
...
篇幅所限,上面只贴了 3 个指标,实际会采集更多指标。
然后重启 Categraf:
systemctl restart categraf
上例是假设您使用 systemd 托管 categraf,如果您使用 supervisor 等其他进程管理工具,请自行搞定。或者不重启 categraf,只是给 categraf 发送一个 SIGHUP 信号,categraf 会自动 reload 配置。
kill -HUP `pidof categraf`
最后,在夜莺里导入仪表盘就可以看到 MySQL 的监控数据了。如下是截取的夜莺 7.7.1 版本。
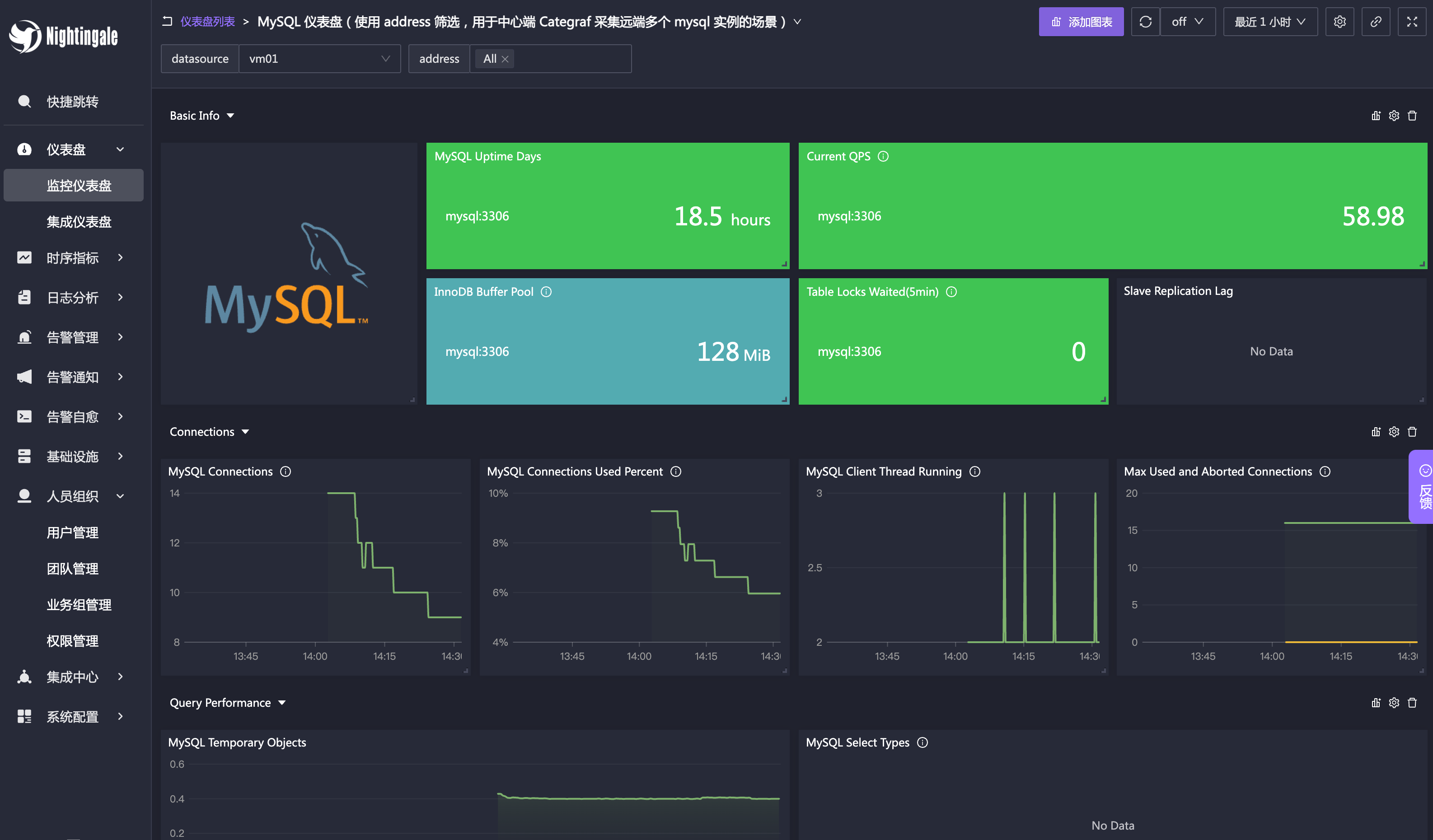
可以打开这个仪表盘:“MySQL 仪表盘(使用 address 筛选,用于中心端 Categraf 采集远端多个 mysql 实例的场景)”,看到的效果如下:
MySQL 监控的两种模式
使用 Categraf 监控 MySQL,有两种模式:
- 模式一:MySQL 使用本机的 Categraf 采集监控数据。比如你有 10 台机器,每个机器上都有一个 MySQL 实例,那就部署 10 个 Categraf,每个 Categraf 采集自己所在机器的 MySQL 实例。
- 模式二:只部署一个 Categraf 专门用来采集 MySQL,即便你有 10 个 MySQL 实例,仍然使用一个 Categraf 来采集。比如云上的 RDS,就只能使用这种模式。
两个模式各有优劣。
模式一,Categraf 采集本机的 MySQL,网络请求走回环网卡,性能更好,网络链路更稳定。这种模式下,MySQL 的地址大概率都是配置的 127.0.0.1:3306,如果你有 10 套 MySQL,通过 address 标签就无法区分这些 MySQL 的监控数据了。因为 address 都是一样的,都是 127.0.0.1:3306。这种模式,在仪表盘中,可以使用机器名作为筛选过滤条件,即大盘里要看哪个机器的 MySQL 数据,就选哪个机器的机器名。“MySQL 仪表盘,适用于 Categraf 采集本机 MySQL 的场景” 这个仪表盘就是应对这种场景的。这种模式无法监控云上的 RDS。因为云上的 RDS 所在的机器普通用户登录不了,自然无法部署 Categraf。
另外,模式一这种模式,由于无法使用 address 标签来区分不同的 MySQL 实例,我们还可以给每个 MySQL 实例附一个标签,比如 labels = { instance="n9e-mysql-01" },这样一来,这个 MySQL 的所有监控数据都会附加这个 instance="n9e-mysql-01" 标签,这样在仪表盘中就可以使用 instance 标签来筛选过滤了。您可以使用这个仪表盘: “MySQL 仪表盘(使用 instance 筛选,需要采集时自行打上 instance 标签)”。如何给实例附加标签?在 Categraf 的配置文件中,给 [[instances]] 配置段加上 labels = { instance="n9e-mysql-01" } 即可:
[[instances]]
address = "10.1.2.3:3306"
username = "categraf"
password = "XXXXXXXX"
labels = { instance="n9e-mysql-01" }
模式二,用一个 Categraf 采集所有 MySQL 实例,可以应对云上 RDS 的场景,Categraf 的配置样例如下:
[[instances]]
address = "10.1.2.3:3306"
username = "categraf"
password = "XXXXXXXX"
labels = { instance="n9e-mysql-01" }
[[instances]]
address = "10.1.2.4:3306"
username = "categraf"
password = "XXXXXXXX"
labels = { instance="n9e-mysql-02" }
上例是监控了两个 MySQL 实例,所以配置了两个 [[instances]] 配置段。这个配置文件是 toml 格式,在 toml 中双中括号表示数组。想要监控多个 MySQL 实例,就复制多份 [[instances]] 配置段就可以了。
这个模式下,不同实例的 address 显然是不同的,所以可以不用附加额外的 instance 标签。在仪表盘中,可以使用 address 标签来筛选过滤。
使用自定义 SQL 监控 MySQL
Categraf 的 MySQL 插件,会执行一些 SQL 来获取 MySQL 的性能指标数据。但有时您可能觉得不够用,想要自定义一些 SQL 来采集监控数据,尤其是一些业务监控数据。此时,您可以自定义 SQL,配置到 Categraf 的 MySQL 插件中。比如我想监控夜莺的数据库中的用户总量,把用户总量作为监控数据采集并上报,配置方式如下:
[[instances]]
address = "10.1.2.3:3306"
username = "categraf"
password = "XXXXXXXX"
labels = { instance="n9e-mysql-01" }
[[instances.queries]]
mesurement = "users"
metric_fields = [ "total" ]
label_fields = [ "service" ]
timeout = "3s"
request = '''
select 'n9e' as service, count(*) as total from n9e_v6.users
'''
上面配置了一条自定义 SQL:select 'n9e' as service, count(*) as total from n9e_v6.users。这个 SQL 的查询结果如下:
+---------+-------+
| service | total |
+---------+-------+
| n9e | 1 |
+---------+-------+
任何一个 SQL 语句,返回的内容都是这么一个二维表格。表格里有很多列,有的列是数值,希望作为监控指标,有的列是字符串,希望作为指标的标签,那我们就需要通过配置告知 Categraf,应该如何解析这个二维表格。所以,就有了上例中的 mesurement、metric_fields、label_fields 这些配置项。这些配置项的作用如下:
mesurement:哪个列作为监控指标名称前缀metric_fields:数组,哪些列作为监控指标的值label_fields:数组,哪些列作为监控指标的标签field_to_append:哪个列作为监控指标名称的后缀,上例中没用到timeout:超时时间request:SQL 语句
如果想定义多个自定义 SQL,就把上面的内容复制多份就可以了,比如:
[[instances]]
address = "10.1.2.3:3306"
username = "categraf"
password = "XXXXXXXX"
labels = { instance="n9e-mysql-01" }
[[instances.queries]]
mesurement = "users"
metric_fields = [ "total" ]
label_fields = [ "service" ]
timeout = "3s"
request = '''
select 'n9e' as service, count(*) as total from n9e_v6.users
'''
[[instances.queries]]
mesurement = "user_groups"
metric_fields = [ "total" ]
label_fields = [ "service" ]
timeout = "3s"
request = '''
select 'n9e' as service, count(*) as total from n9e_v6.user_groups
'''
MySQL 插件配置详解
下面我们把 Categraf 的 MySQL 插件的所有配置贴到下面,并逐一解释。
# 定义mysql采集周期,单位是秒
interval = 15
# 定义全局要执行的自定义SQL,每个instance都会执行
# 注意这里是 [[queries]],而不是 [[instances.queries]],[[queries]]是全局的,[[instances.queries]]是针对某个instance的
[[queries]]
mesurement = "lock_wait"
metric_fields = [ "total" ]
timeout = "3s"
request = '''
SELECT count(*) as total FROM information_schema.innodb_trx WHERE trx_state='LOCK WAIT'
'''
# 定义instance, 一个instance对应一个mysql实例
# 指定mysql的地址,用户名,密码
[[instances]]
address = "127.0.0.1:3306"
username = "categraf"
password = "xxxxxxxx"
# 是否使用 tls 等定制参数
parameters = "tls=false"
# 通过 show global status 监控 mysql,默认抓取一些基础指标,
# 如果想抓取更多 global status 的指标,把下面的配置设置为 true
extra_status_metrics = true
# 通过show global variables 监控 mysql 的全局变量,默认抓取一些常规的
# 常规的基本够用了,扩展的部分如果也想采集,下面的配置设置为 true
extra_innodb_metrics = true
# 监控 processlist,关注较少,默认不采集
gather_processlist_processes_by_state = false
gather_processlist_processes_by_user = false
# 监控各个数据库的磁盘占用大小,如果你的 DB 很大,可能会很耗时,不建议采集,用处不大
gather_schema_size = false
# 监控所有的 table 的磁盘占用大小,如果你的 DB 很大,可能会很耗时,不建议采集,用处不大
gather_table_size = false
# 是否采集系统表的大小,通常不用,所以默认设置为false
gather_system_table_size = false
# 通过 show slave status 监控 slave 的情况,比较关键,所以默认采集
gather_slave_status = true
# 超时时间
timeout_seconds = 3
# 采集周期的倍数,比如设置为2,那么采集周期就是 interval * 2
interval_times = 1
# 为 mysql 实例附加一些标签,比如上面的例子中提到的 instance 标签
labels = { instance="n9e-mysql-01" }
# tls 相关配置,可选配置
use_tls = false
tls_min_version = "1.2"
tls_ca = "/etc/categraf/ca.pem"
tls_cert = "/etc/categraf/cert.pem"
tls_key = "/etc/categraf/key.pem"
# Use TLS but skip chain & host verification
insecure_skip_verify = true
# 定义只针对当前 mysql 实例的自定义 sql
[[instances.queries]]
mesurement = "lock_wait"
metric_fields = [ "total" ]
timeout = "3s"
request = '''
SELECT count(*) as total FROM information_schema.innodb_trx WHERE trx_state='LOCK WAIT'
'''
如何监控 MySQL 集群
MySQL 集群通常是一主多从,显然主节点有自己的连接数、TPS 指标,从节点也有自己的连接数、TPS 等指标,所以,我们要同时监控主从节点,即把主从节点的连接地址都配置到 Categraf 的 MySQL 插件中。比如:
[[instances]]
address = "10.1.2.3:3306"
username = "categraf"
password = "XXXXXXXX"
labels = { cluster="n9e" }
[[instances]]
address = "10.1.2.4:3306"
username = "categraf"
password = "XXXXXXXX"
labels = { cluster="n9e" }
如上例,由于这里的主从节点是有关系的,都是属于某个集群的,那我们就给他们都打上一个 cluster 标签,用来和其他集群区分开。
只想采集自定义 SQL,不想采集 MySQL 的基础指标
有时,你只想用某个特定的 Categraf 实例采集 MySQL 的自定义 SQL,不想采集 MySQL 的基础指标,那么可以这样配置:
[[instances]]
address = "127.0.0.1:3306"
username = "categraf"
password = "xxxxxxxx"
# 关闭各类扩展采集开关
extra_status_metrics = false
extra_innodb_metrics = false
gather_processlist_processes_by_state = false
gather_processlist_processes_by_user = false
gather_schema_size = false
gather_table_size = false
gather_system_table_size = false
gather_slave_status = false
# 注意下面这几个 disable 的配置,都设置为 true,即 disable 掉基础采集
disable_global_status = true
disable_global_variables = true
disable_innodb_status = true
disable_extra_innodb_status = true
disable_binlogs = true
[[instances.queries]]
# 各类自定义 SQL 写到这个位置
总结
本文详细描述了 MySQL 监控插件的配置,当然,上面的工作完成,也只是采集了监控指标,具体各个指标是什么含义,解释起来篇幅就长了,就不在这里展开了。希望上面的内容可以帮到您。


