
快速配置告警规则体验夜莺告警功能
带你在完成夜莺部署和数据接入后,快速创建一条告警规则,理解告警条件、持续时长、通知配置、内置规则导入和活跃告警入口。
根据前面的文档,已经完成了夜莺的部署,并且采集到了数据、配置了数据源,现在我们就快速配置一个告警规则,体验一下夜莺的告警功能。
夜莺的告警规则和 Prometheus 类似,核心就是配置 promql,然后夜莺拿着这个 promql 周期性去查询时序库,如果查到了,就产生告警事件(查到几条生成几条事件),如果查不到了,就说明不再达到阈值,就产生恢复事件。我用 system_load_norm_1 这个指标来举例,先去即时查询里查一下这个指标的值:
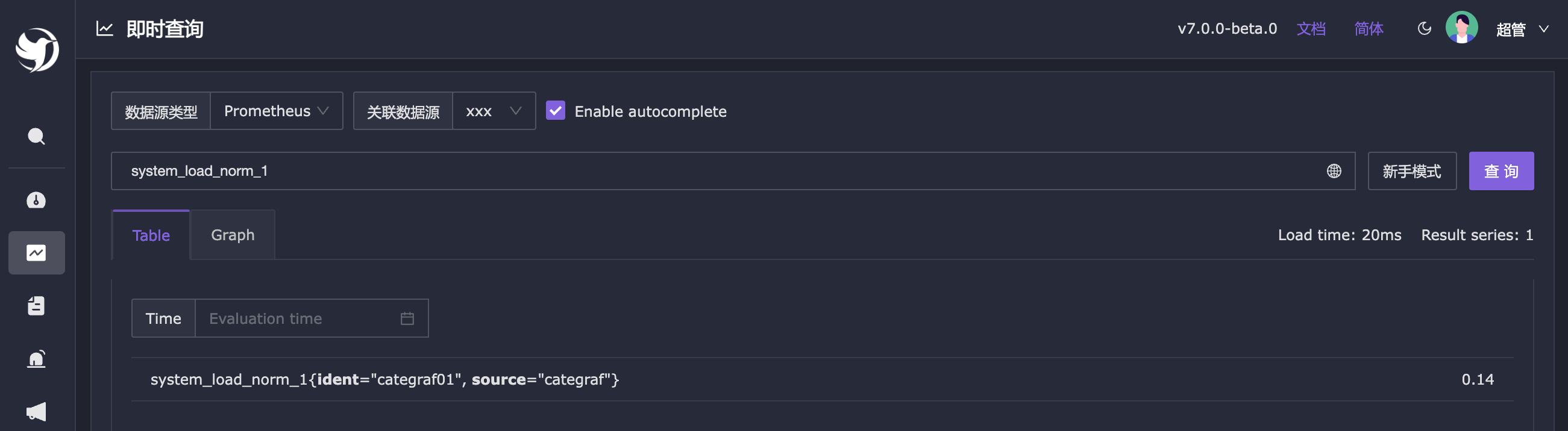
system_load_norm_1 表示平均每个 cpu core 的负载,当前值是 0.14,为了快速生成告警事件,我会把阈值设置为 0,只要大于 0 就算触发阈值。执行频率设置为 15 秒,即每 15 秒查询一次时序库,持续时长设置为 0,相当于只要有一次触发阈值就产生告警,这两个字段上面都有说明,鼠标放上去就会看到提示。
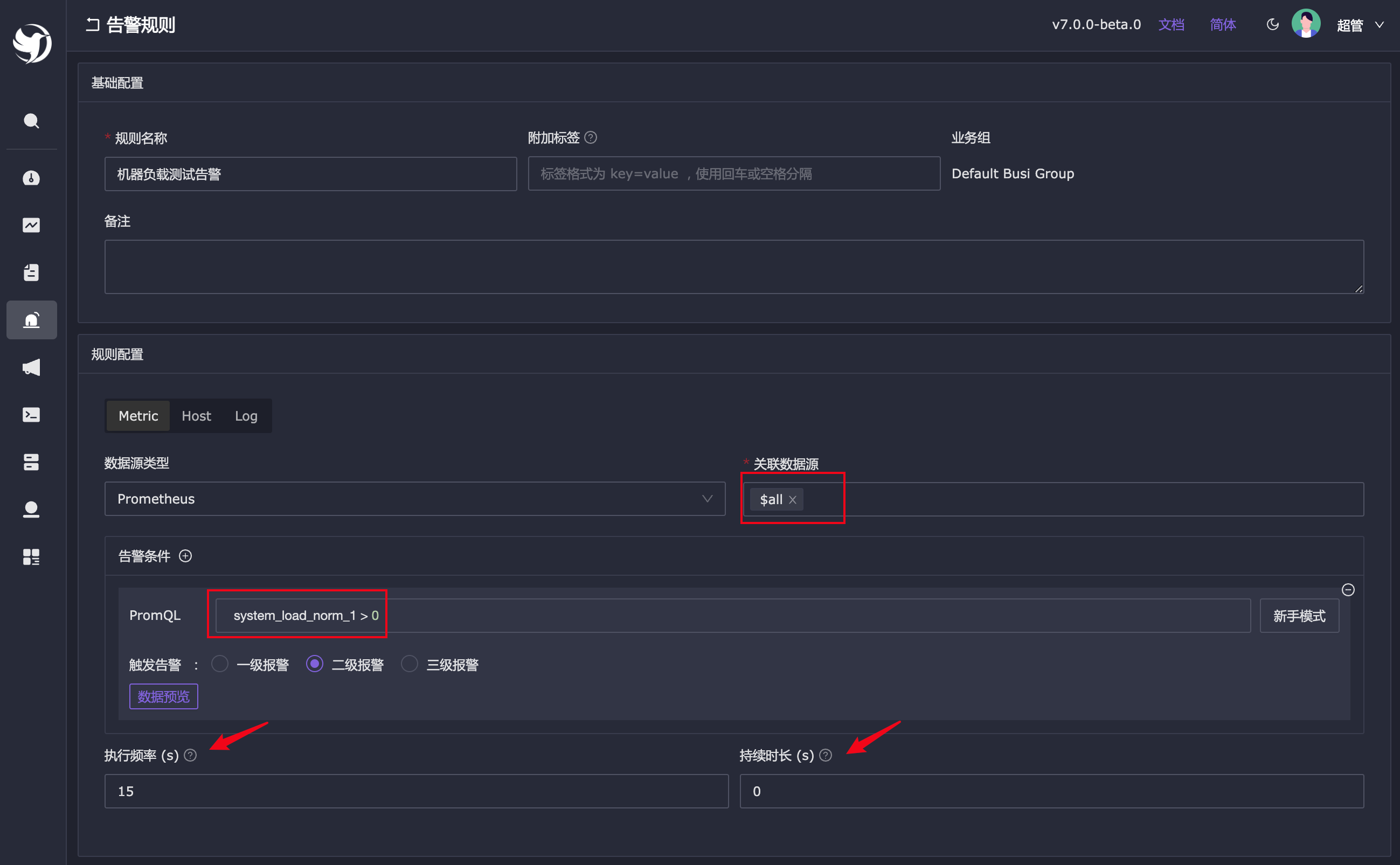
保存告警规则,很快就会生成告警事件了,菜单入口:告警管理 - 活跃告警,如图所示:

告警事件成功生成!红框里两个按钮可以选择展示模式,当前展示的是列表模式,也可以使用卡片模式,卡片模式可以做事件聚合展示。
导入内置规则
夜莺已经内置了一些告警规则,可以导入到自己的业务组使用。菜单入口:告警管理 - 告警规则,选中左侧业务组,点击右上角【更多操作】-【导入告警规则】,如图所示:
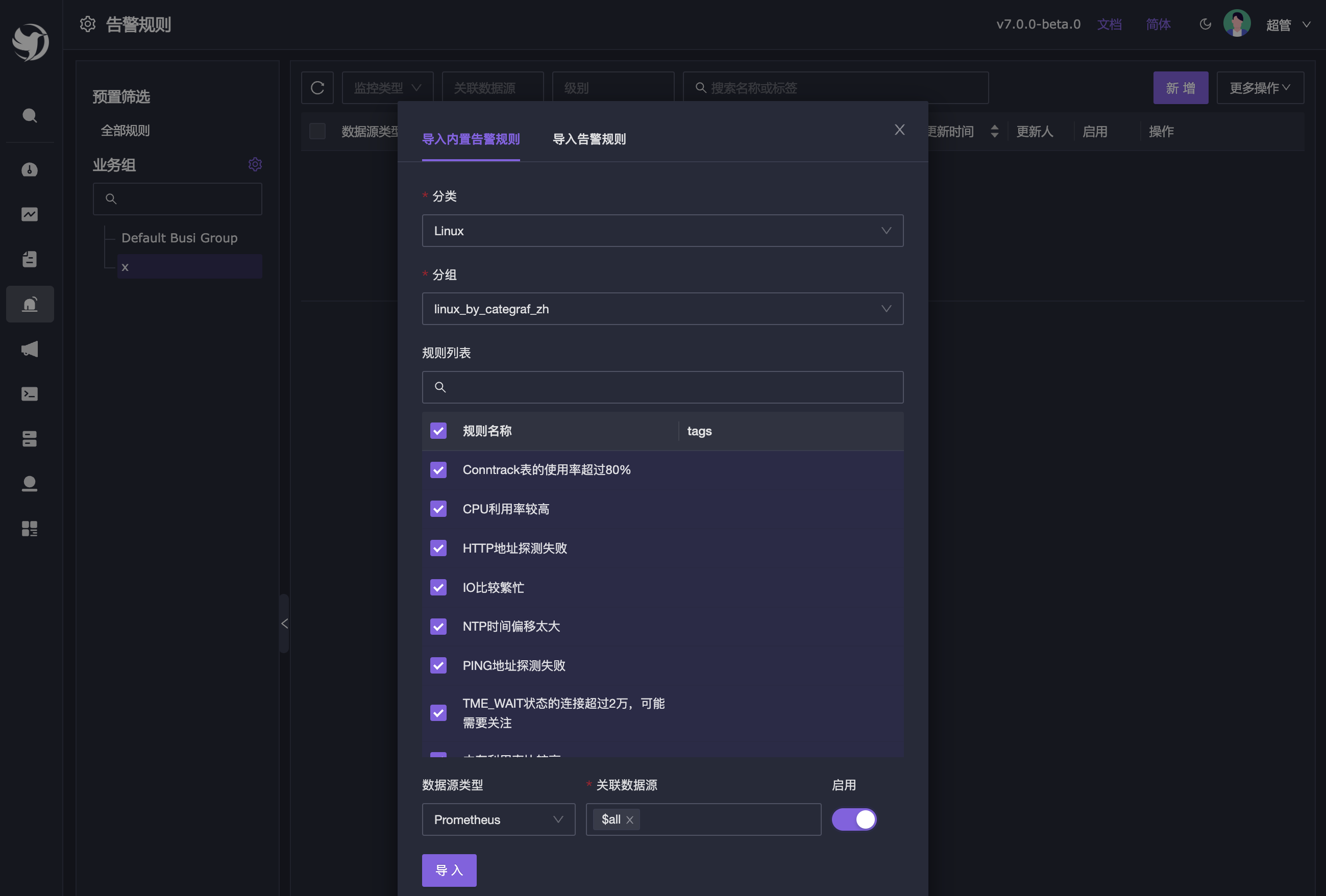
Linux 分类下的 linux_by_categraf_zh 这个分组下的告警规则,既适用于 Linux 也适用 Windows。你可以基于这些规则做调整,比如批量修改告警接收人、批量启用/禁用告警规则等。
如果内置的告警规则不够用,推荐从下面这些地方获取:
- https://promcat.io/:这是 sysdig 公司维护的
- https://samber.github.io/awesome-prometheus-alerts/rules.html:开源规则仓库,也可以参考
不过,上面这些规则都是基于 Prometheus 的,没法直接导入夜莺中,不过有社区小伙伴写过转换脚本,可以把 Prometheus 的告警规则转换成夜莺的告警规则,脚本位置在 这里,Python 写的(大家应该都看得懂吧),可以自行下载、修改、使用。
告警规则关键字段说明
基础配置
- 规则名称:告警规则的名称,比如
CPU 使用率过高 - 附加标签:附加到该规则产生的所有告警事件上,未来可以使用这些标签做事件筛选,比如
team=cloud这样的格式 - 备注:告警规则的备注,可以写一些规则的说明,可以引用事件变量,比如
{{ $labels.instance }}这样的格式
规则配置
夜莺支持时序指标告警、日志告警、机器失联告警,根据自己的需求选用。最常用的是指标告警,比如 Prometheus 数据源类型,需要配置以下字段:
- 关联数据源:表示这个告警规则生效到哪些数据源,如果写
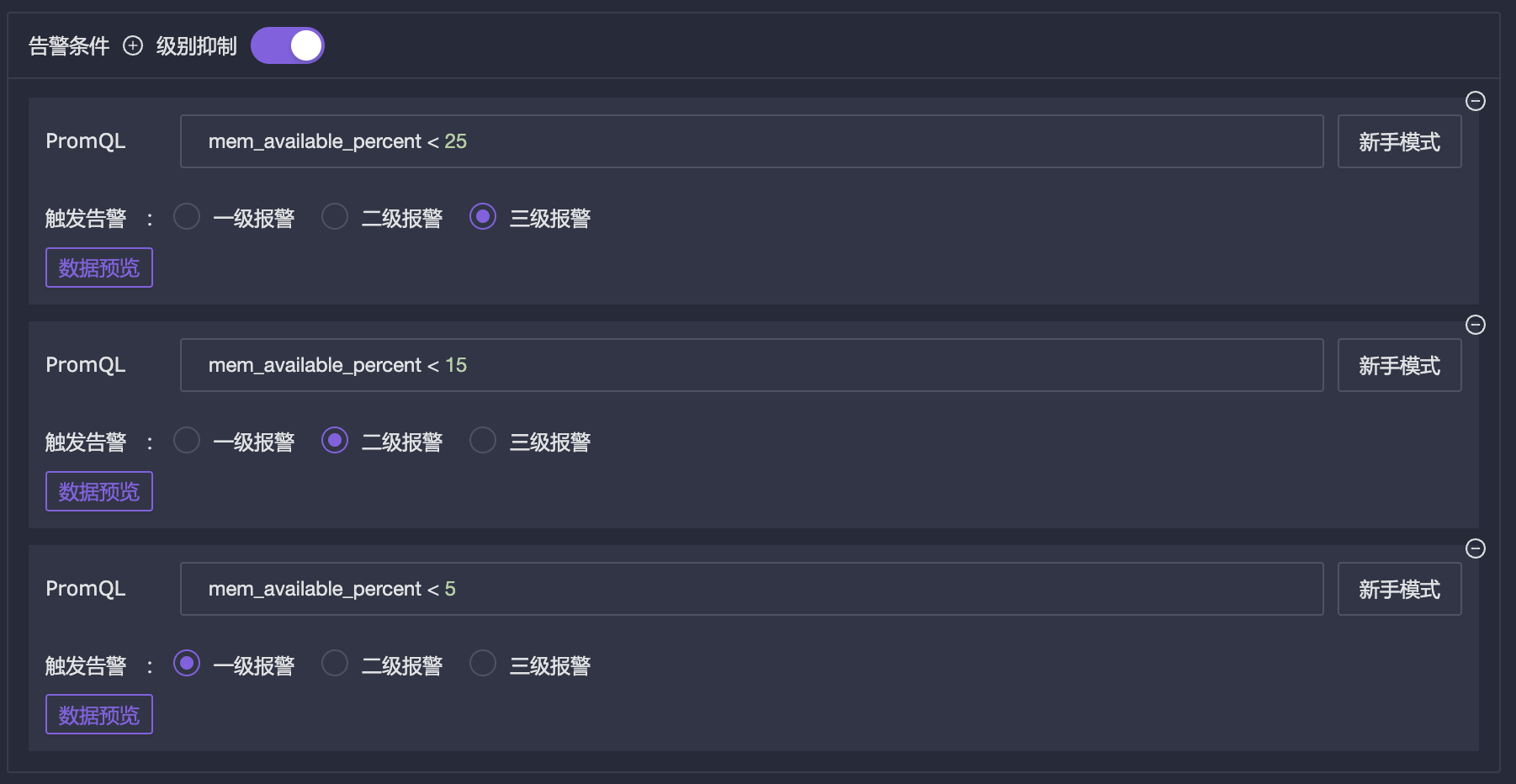
$all表示生效到该类型下所有数据源,很多公司可能有多个 Prometheus 或 VictoriaMetrics,可以用一个规则生效到多个时序库上 - 告警条件:promql 表达式,可以写多个,并启用级别抑制,比如内存可用率,如果过低就告警,小于 25% 是三级告警,小于 15% 是二级告警,小于 5% 是一级告警。则可以如下配置:
- 执行频率:夜莺作为告警引擎,会周期性查询时序库,这个字段配置执行频率
- 持续时长:相当于 Prometheus 告警规则中的 for 字段。通常持续时长大于执行频率,在持续时长内按照执行频率多次执行查询,每次都触发才生成告警;如果持续时长置为0,表示只要有一次查询的数据满足告警条件,就生成告警
生效配置
比如白天一个阈值规则,晚上是另一个,或者工作日是一个,周末是另一个,则可以通过生效配置来实现。
仅在本业务组生效
需求场景,比如有 A、B 两个业务组,每个业务组下面都有 10 台机器,此时在 A 业务组下配置告警规则:system_load_norm_1 > 0,则会对所有的 20 台机器生效。如果只想对 A 业务组下的 10 台机器生效,可以勾选【仅在本业务组生效】。
勾选该项之后,夜莺告警引擎的处理逻辑就变成了:拿着 system_load_norm_1 > 0 这个 promql 去查询时序库,时序库根本不知道哪些机器属于哪些业务组,会返回所有触发阈值的机器,在夜莺里机器标识是使用 ident 标签,告警引擎拿着 ident 标签与本业务组下的机器做比对,如果当前这个告警事件的 ident 标签指代的机器恰好在这个业务组下,才生成告警事件。
注意:如果 promql 查询结果中没有 ident 标签,则这个机制就没有办法跑通了。
通知配置
- 告警接收组:告警事件产生后,通知哪些人。为了防止人员变动导致大面积告警规则调整,这里需要配置团队,告警之后,会发给这些团队中的所有的人。当然,规则里也可以不配置告警接收组,后面使用订阅规则和接收人做关联即可
- 留观时长、重复通知间隔、最大发送次数,每个字段都有 tooltip 提示,自行阅读即可。一般来讲,重复通知间隔一般设置为 60 分钟,最大发送次数设置为 0,避免漏掉一些告警
- 回调地址:告警事件产生后,可以通过回调地址通知外部系统,这里配置的回调地址自然是针对这个规则产生的告警事件,如果想让所有的告警事件都做回调,可以配置全局的回调地址,菜单入口:
告警通知-通知设置-回调地址 - 附加信息:相当于自定义字段,可以在备注里或通知模板里引用,假设我配置了一个 RunbookURL 字段

引用方式:{{ .AnnotationsJSON.RunbookURL }}。附加信息的字段是可以完全自定义的,直接手输就可以,虽然页面上有 runbook_url、dashboard_url、summary 等提示信息,那也只是 suggestion,你还是可以输入任何你想输入的字段名称。
告警降噪、认领升级
通常来讲,监控系统的侧重点是数据采集、存储、查询分析、告警,一旦产生告警事件就算完活了,但是告警事件的后续处理也是很重要的,比如告警降噪、排班认领升级、灵活分发、IM 协同等。这些功能是通用功能,夜莺需要,Zabbix、Prometheus、ElastAlert、蓝鲸、Open-Falcon、各类云监控等都需要,但是如果放到监控系统中来实现,势必就会和监控系统深度耦合,没法让其他监控系统享受到这个便利功能,所以夜莺并没有实现这些功能,而是单独拎出一个产品来实现,即 Flashduty。
Flashduty 可以对接各类监控系统,统一收集告警事件,做后续处理,是一个一站式告警响应平台:降噪、值班、分派、升级、触达。Flashduty 有免费套餐,也有商业套餐(包含较多电话、短信、邮件配额),欢迎大家试用。


