快捷视图设计逻辑、功能详解
夜莺监控Nightingale快捷视图设计逻辑、功能详解
快捷视图的设计初衷是提供一个偏运维视角的指标视图,以实例维度进行展示,鼠标点点,即可看到监控数据。
那么快捷视图的快捷视图列表是如何做到从海量数据数据拿到实例列表呢?也很简单,编辑任意一个快捷视图可以看到,它会有一个前置过滤条件,通过这个条件过滤后得到少量的监控数据,再从这些数据中提取展开维度标签的值,从而得到实例列表(如机器视图,前置过滤条件为__name__ = mem_free,展开维度标签为ident,Mysql实例视图,前置过滤条件为__name__ = mysql_up,展开维度标签为address)。
比如我想拿到所有机器的实例列表,机器的实例标识即 ident 标签的值,那我们就从时序库中获取所有 ident 标签的值就可以了。但是,带有 ident 的 series (监控数据时间线)何止千万,从所有 series 中提取 ident 标签的值就太慢了。所以,我们就先做一些过滤,比如:我们知道 mem_free 这个 metric 表示机器的内存余量,每个机器都有这个指标,那我们只查询这个指标相关的 series,就可以得到所有机器的 mem_free 相关的 series,再从中提取 ident 标签的值,就可以大幅降低查询的数据量了。这就是前置过滤条件的作用。
如果时序数据打上了丰富的标签,我们还可以使用动态过滤条件做一些二次筛选。比如我有100台机器,通过 __name__ = mem_free 做了筛选,拿到了 100 个机器名,快捷视图里就会有 100 个机器列表展示,这里 100 台机器假设分成两个 region,mem_free 指标里都带有 region 标签,那我们就可以把 region 设置为该视图的动态过滤条件,最终渲染这个快捷视图的时候,就会在这 100 台机器列表上面出现 region 下拉框,选择 region 后,就可以筛选出该 region 下的机器了。
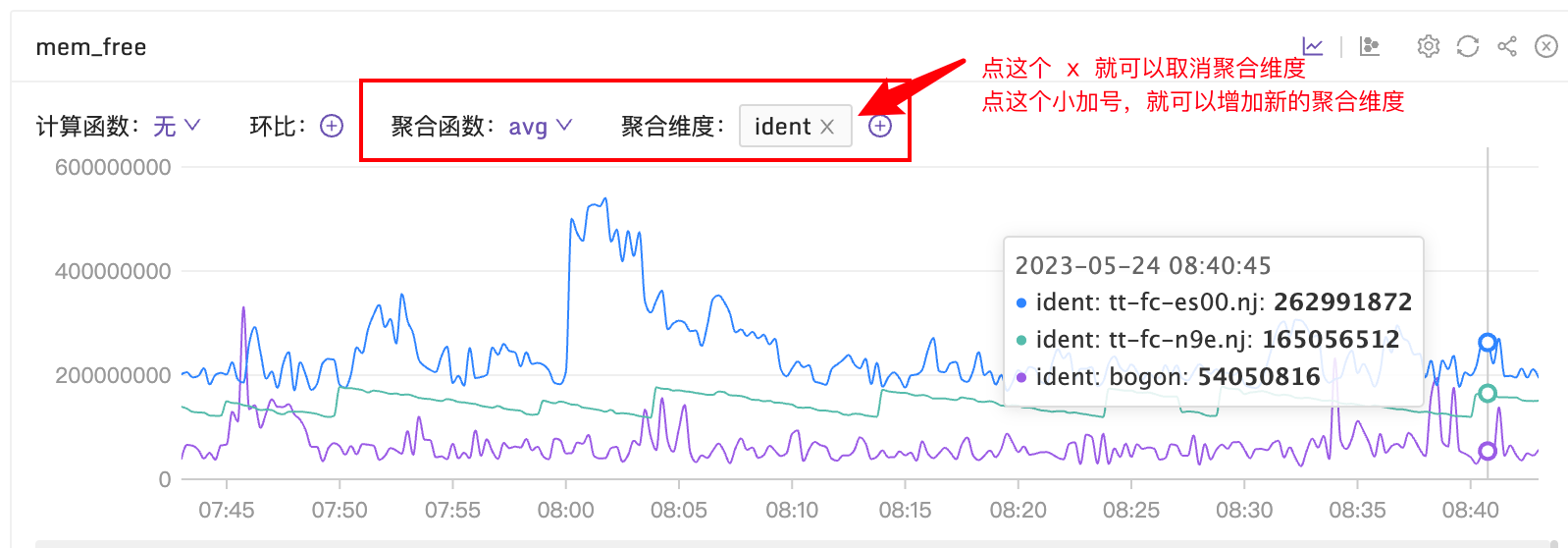
不过需要注意这里展示的是图表默认进行了聚合操作,如果想要取消聚合看到单个的 series,可以手工做调整,如下图: