日誌采集&存儲
ES 存儲部署和日誌采集上報,可以參考此文檔。
Elasticsearch 數據源配置
數據源名稱-名稱:Elasticsearch 數據源標識名稱;
HTTP - URL :Elasticsearch 服務地址;示例:http://server-ip:9200
HTTP -超時(單位:ms ):連接服務超時時間;
授權-用戶名 & 密碼:Elasticsearch 授權用戶名和密碼;

Elasticsearch 通過 your_path/bin/elasticsearch-users list|useradd 創建和查詢用戶,可以通過 GET /_security/user 或者在 Kibana 的管理界面中查看和管理用戶。
自定義 HTTP 標頭- Header & Value :配置請求 Elasticsearch 接口的校驗參數;
ES 詳情- 版本&最大並發分片請求數
如果集群中的分片數量非常高,未配置的最大並發分片請求數可能會導致高內存使用、CPU 負載增加、延遲增加等問題。那麼這種情況下設置最大並發分片請求書就顯得十分有必要了。通過 Elasticsearch 的查詢命令 curl -X GET http://server_ip:port/_cat/shards?v 可以查詢到設置的最大並發分片請求數。
最小時間間隔(s) :按時間間隔自動分組的下限。建議設置為寫入頻率,例如,如果數據每分鐘寫入一次,則為 1m。
寫配置- 允許寫入(商業版功能)
這個功能和 Prometheus 數據源中的 Remote Write 類似,開啟後就可以將日誌提取數據回寫到 ES 節點中;
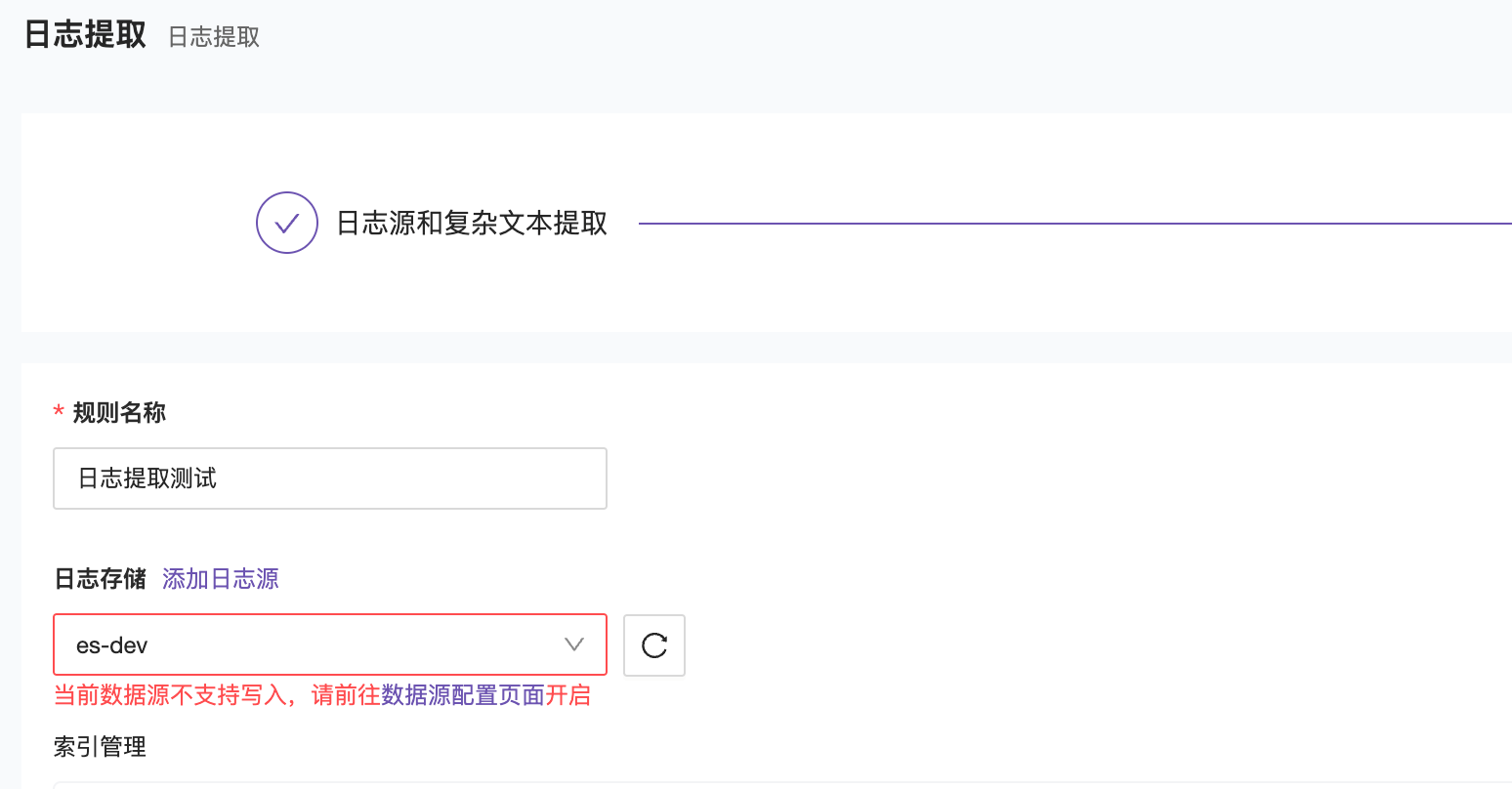
開啟允許寫入後,就可以正常寫入數據了。
關聯告警引擎集群:配置綁定指定告警引擎的數據源;
如何查詢數據
- 日誌查詢-即時查詢—> 2. 選擇對應 ES 數據源—> 3. 選擇查詢語法—> 4. 輸入查詢語句
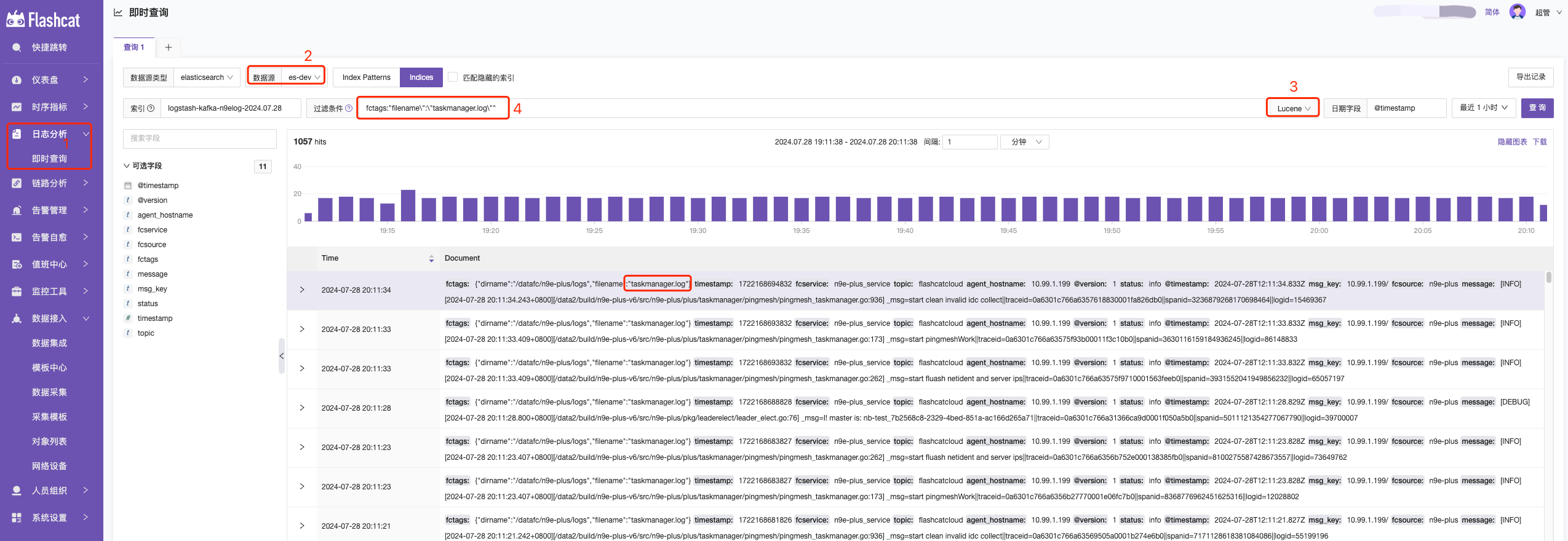
- KQL :一種用於過濾數據的簡單基於文本的查詢語言,KQL 僅過濾數據,並且不具有聚合、轉換或排序數據的作用。KQL 官方語法介紹
- Lucene :查詢語法的主要原因是使用高級 Lucene 功能,例如正則表達式或模糊術語匹配。但是,Lucene 語法無法搜索嵌套對象或腳本字段。Lucene 官方語法介紹
如何配置 ES 日誌告警
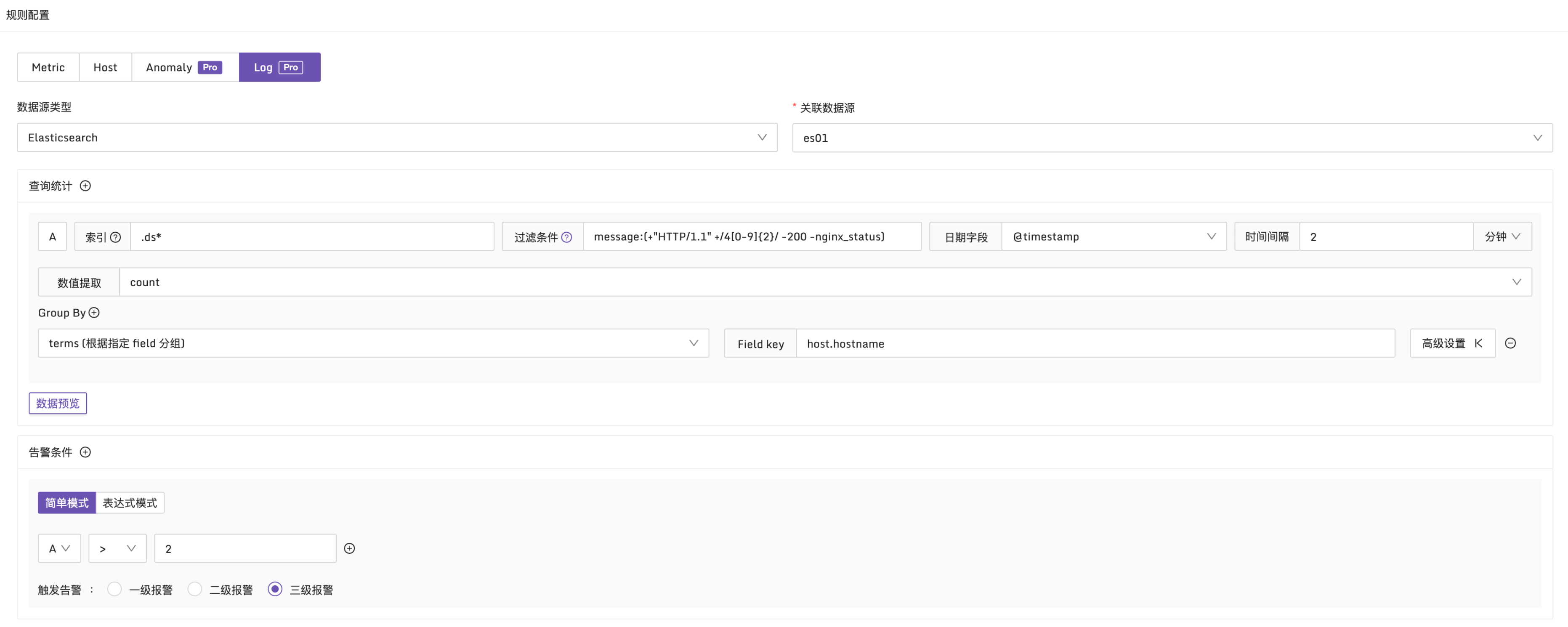
日誌類型和常規的指標告警規則非常相似,其唯一的區別在於告警條件的設置。指標告警規則使用 PromQL 作為查詢條件,而日誌類型的告警規則則使用布爾表達式作為查詢條件。這些告警條件(如 A、B 等)需要通過查詢統計來獲取。
在配置查詢統計時,會發現它和 ES 日誌即時查詢 類似,先選擇索引和查詢條件以及日期字段,還有兩個額外的數據字段組:數值提取和 Group By。
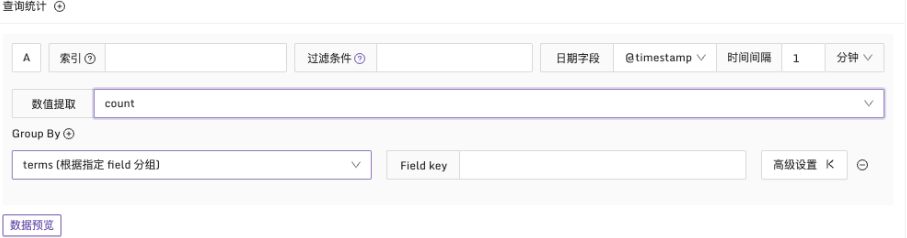
為了獲得數值類型的結果,需要使用數值提取,選擇適當的統計函數。除了常見的 count、sum、avg、min、max 等函數外,還支持一些百分位值函數,如 p90、p95、p99。
此外,通過配置 Group By,可以根據特定字段對結果進行分組。這將生成多個時間序列,並在滿足告警條件的情況下產生多個異常點,從而生成多條告警事件。
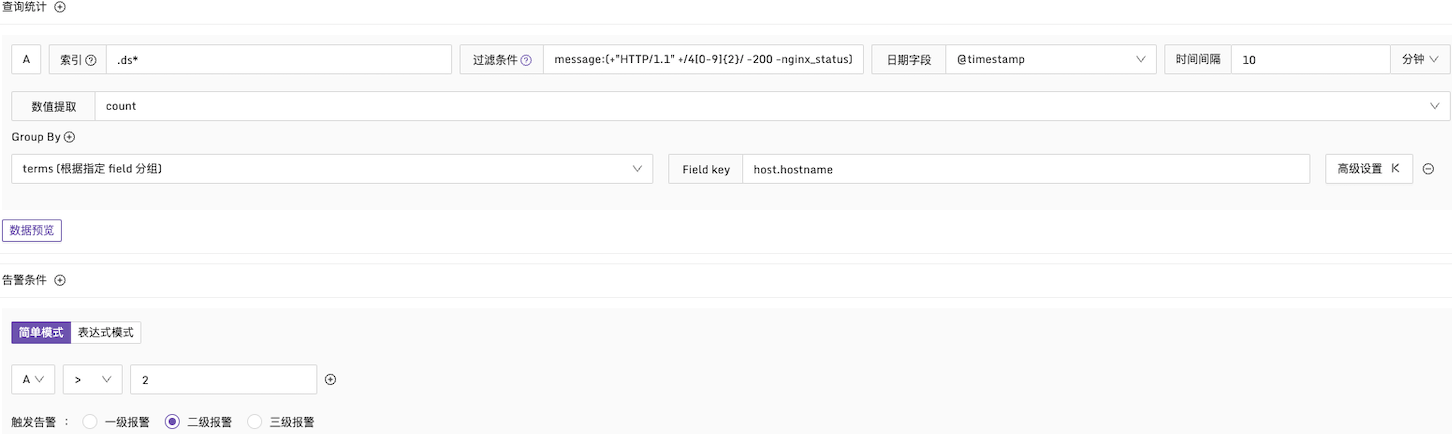
例子1:HTTP CODE 為4xx的告警條件
說明:在每10分鐘的時間段內,檢查日誌中的 message 字段。如果4xx的日誌數量超過2次,產生告警,並且按照 host.hostname 字段進行分組統計,配置方式如下:
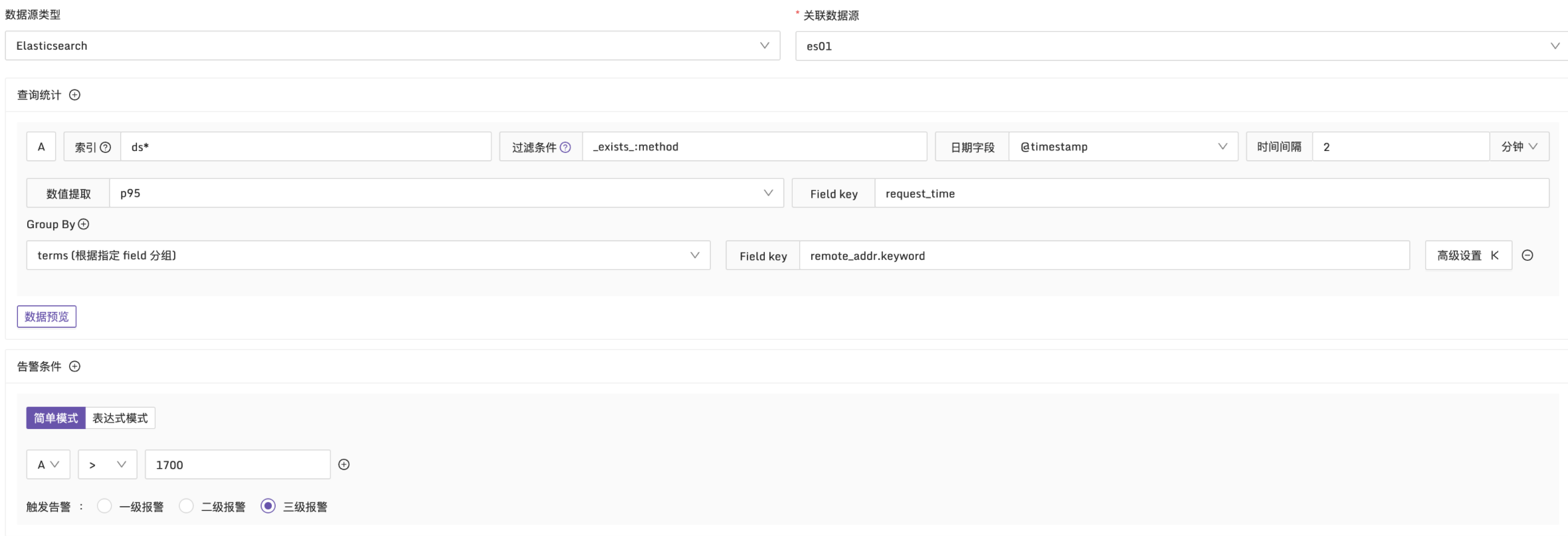
例子2:接口的請求耗時95分位值超過 1700ms 時觸發告警
說明:在每2分鐘的時間段內,使用 p95 函數統計日誌中的 request_time 。按 remote_addr 維度進行分組,檢查是否有超過1700ms 的請求耗時,配置方式如下:
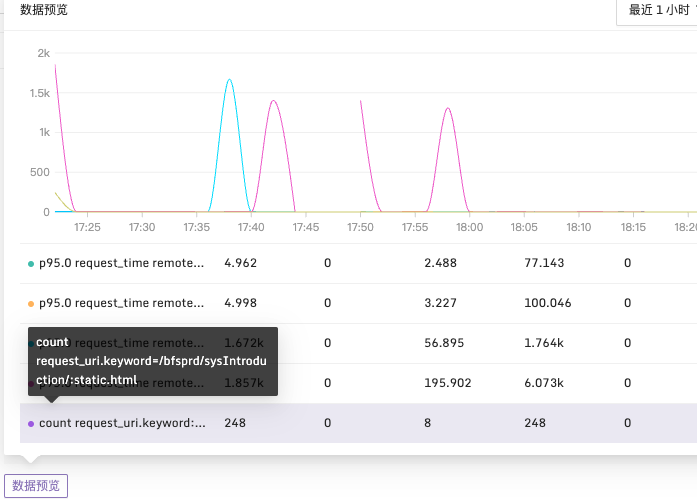
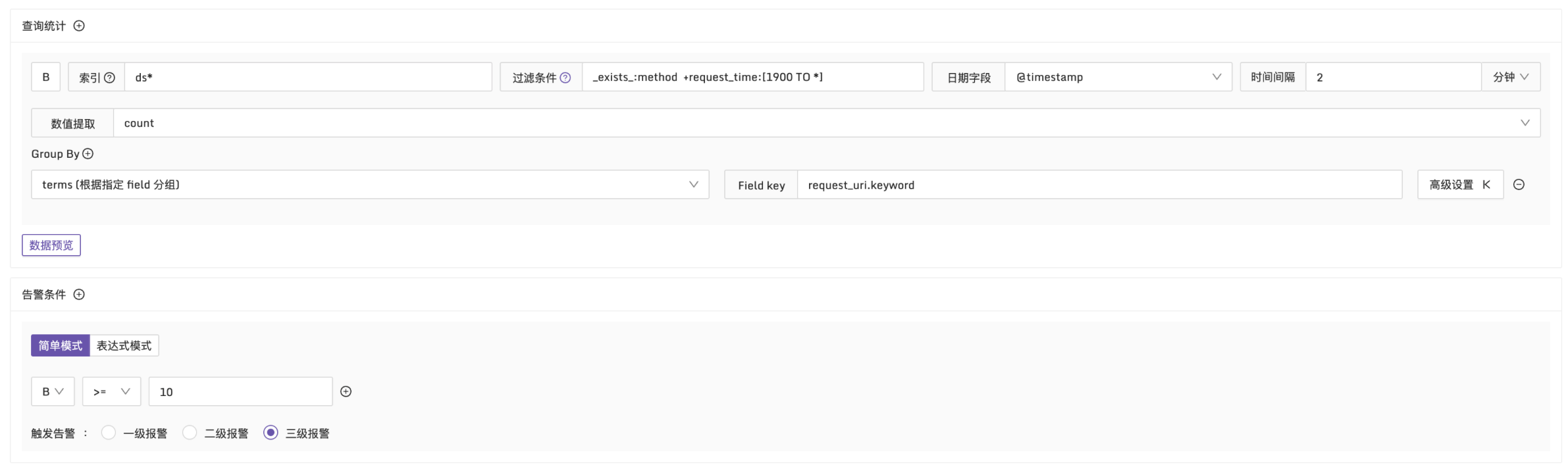
例子3:request_time 大於 1900ms,匹配日誌超過10條時觸發告警
說明:在每2分鐘的時間段內,篩選出 request_time 大於1900ms 的日誌。按 request_uri 維度進行分組,檢查日誌數量是否超過10條,配置方式如下:
在配置完成所需的數據字段後,還可以通過數據預覽按鈕來預覽查詢結果。