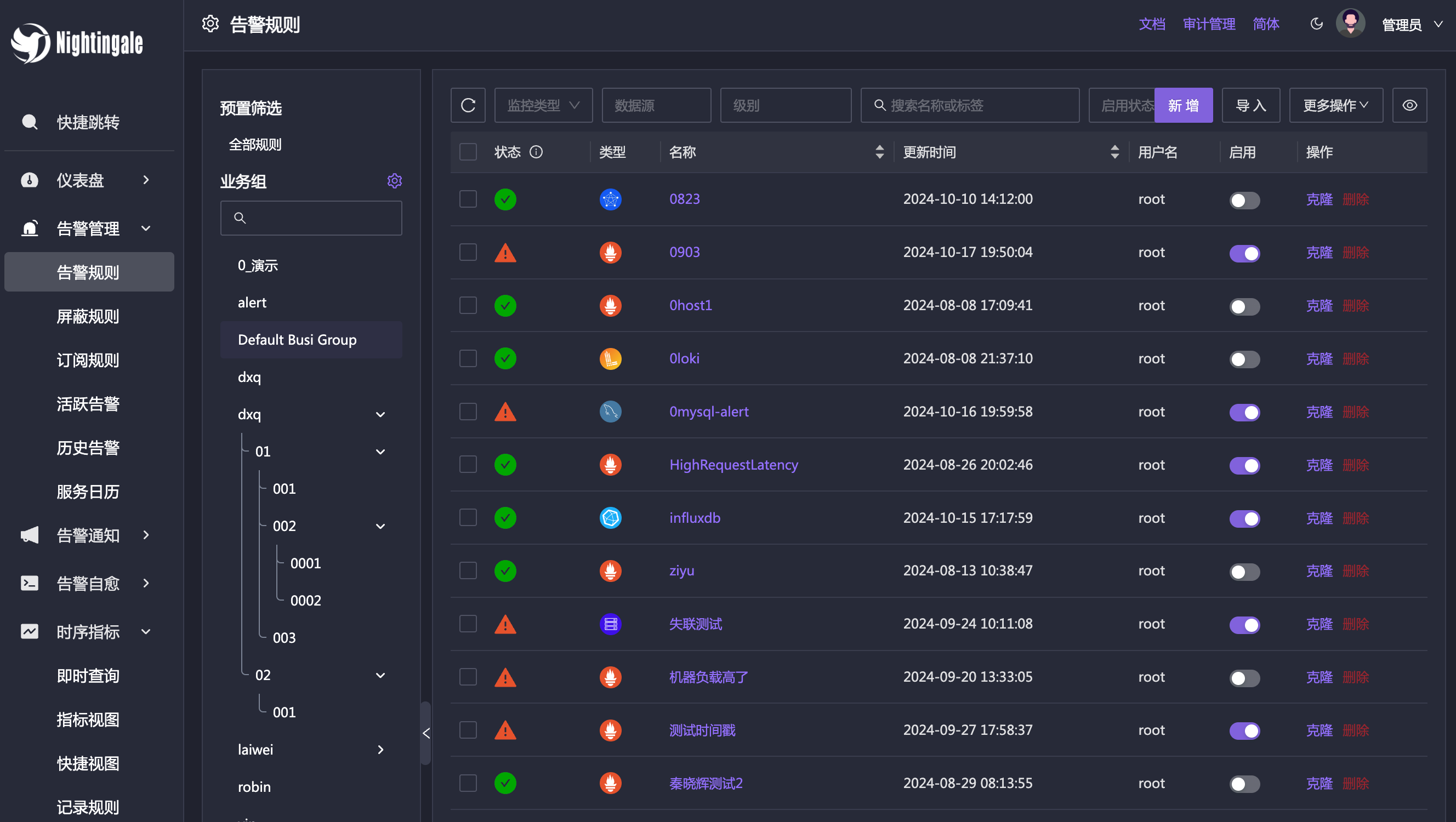
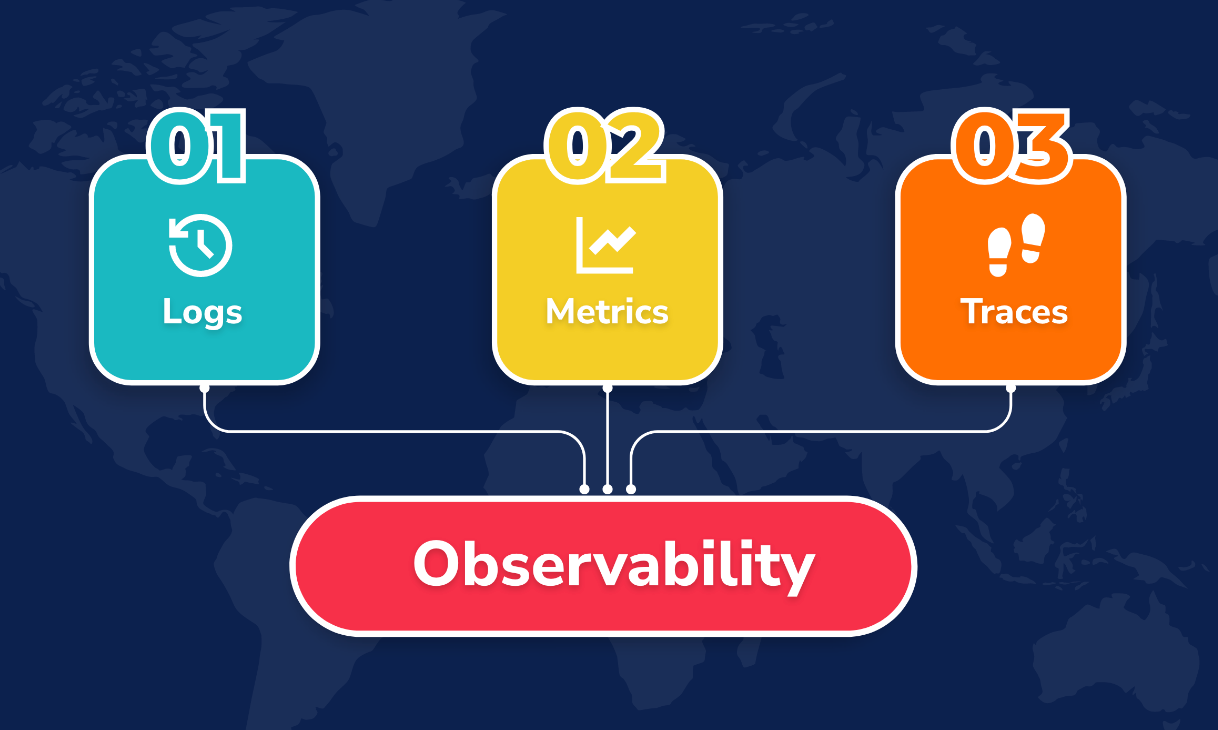
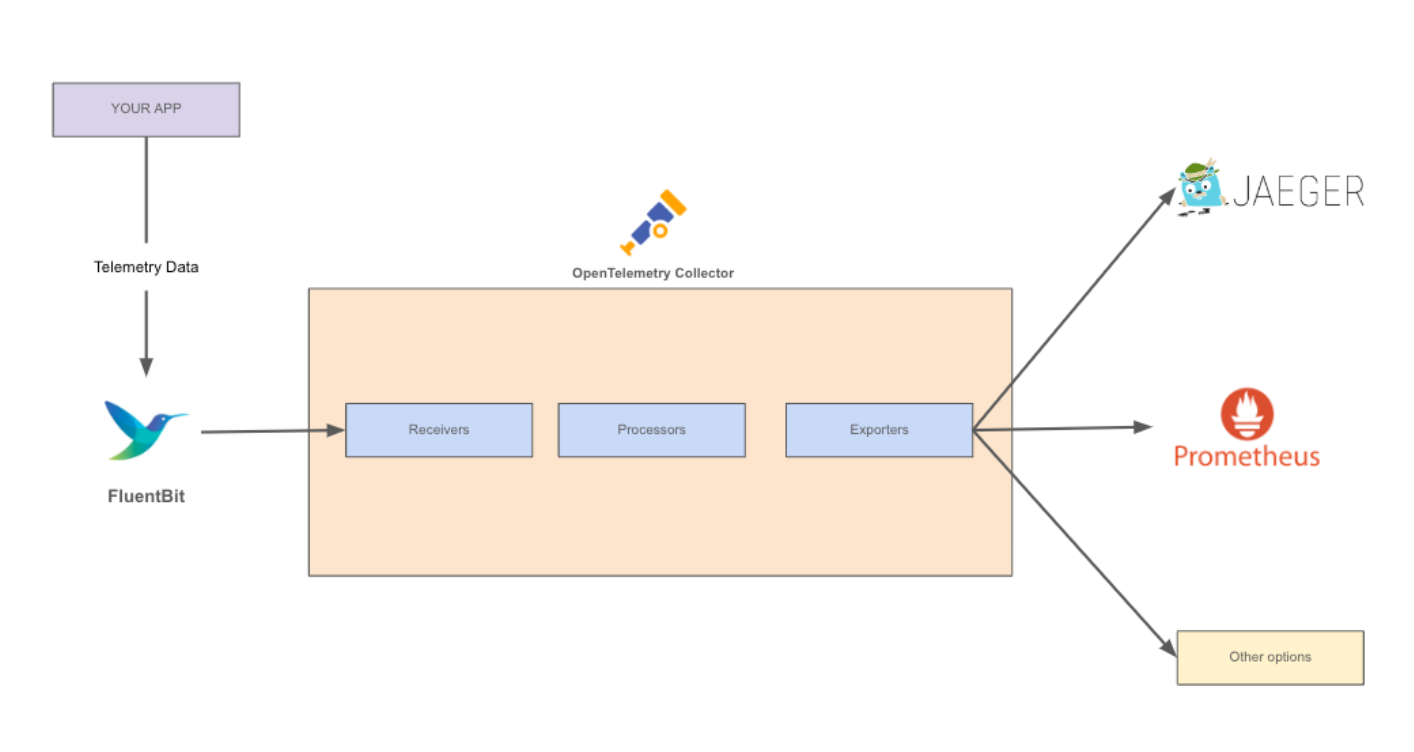
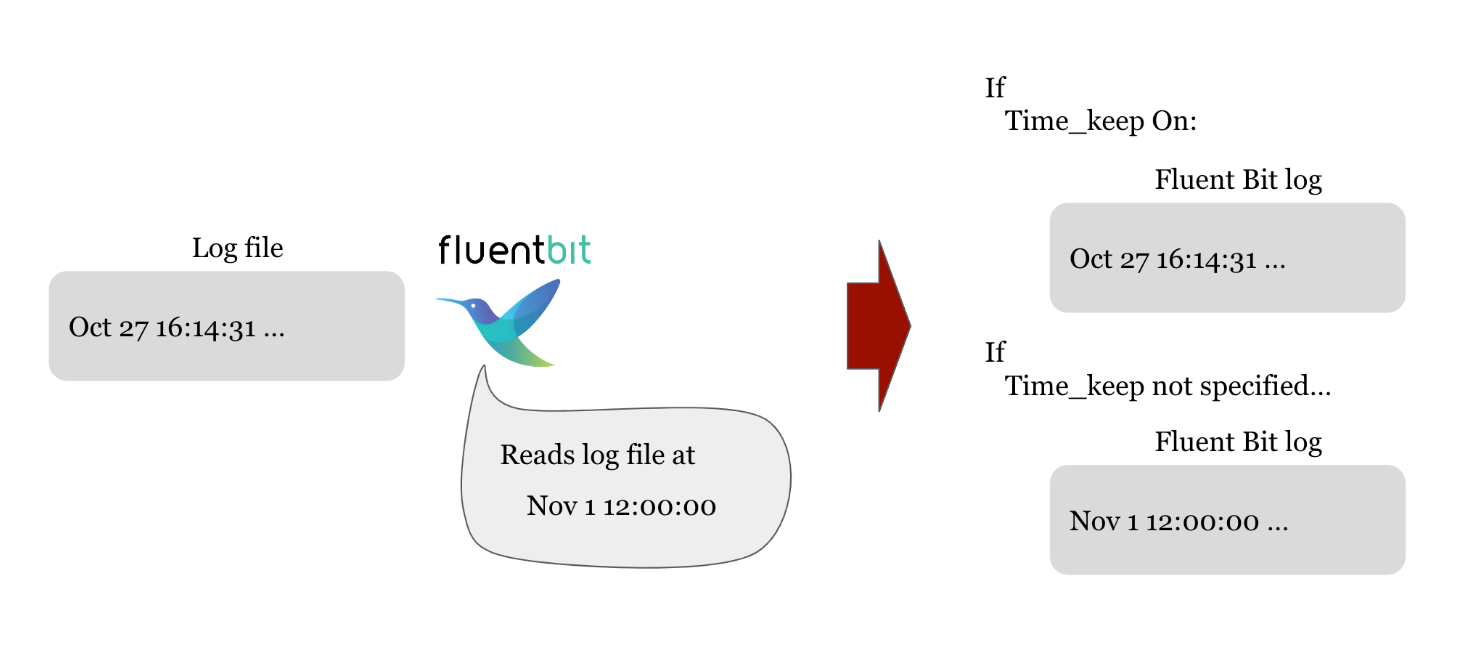
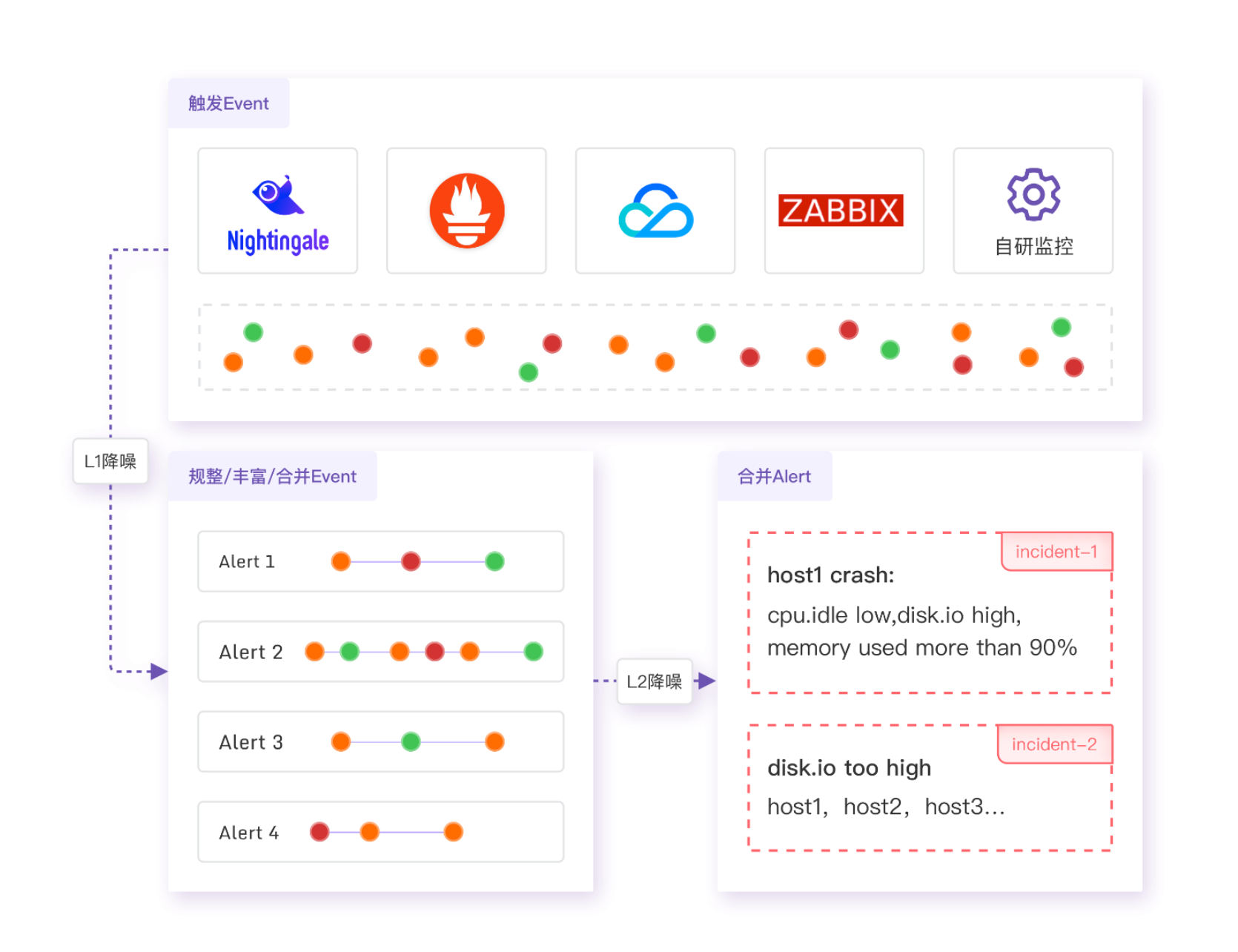
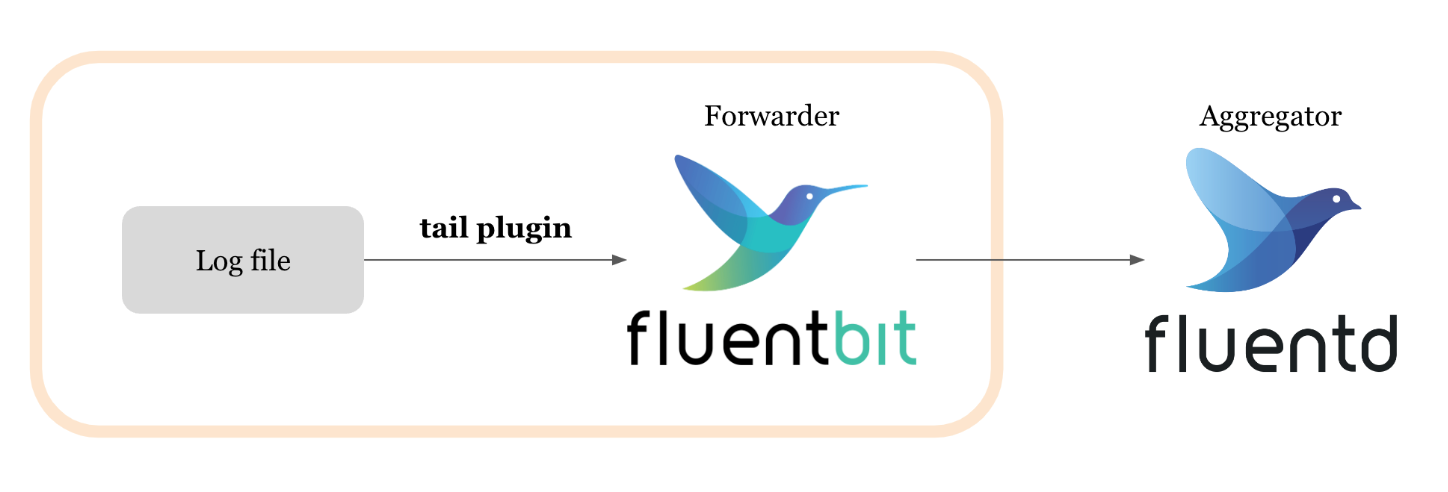
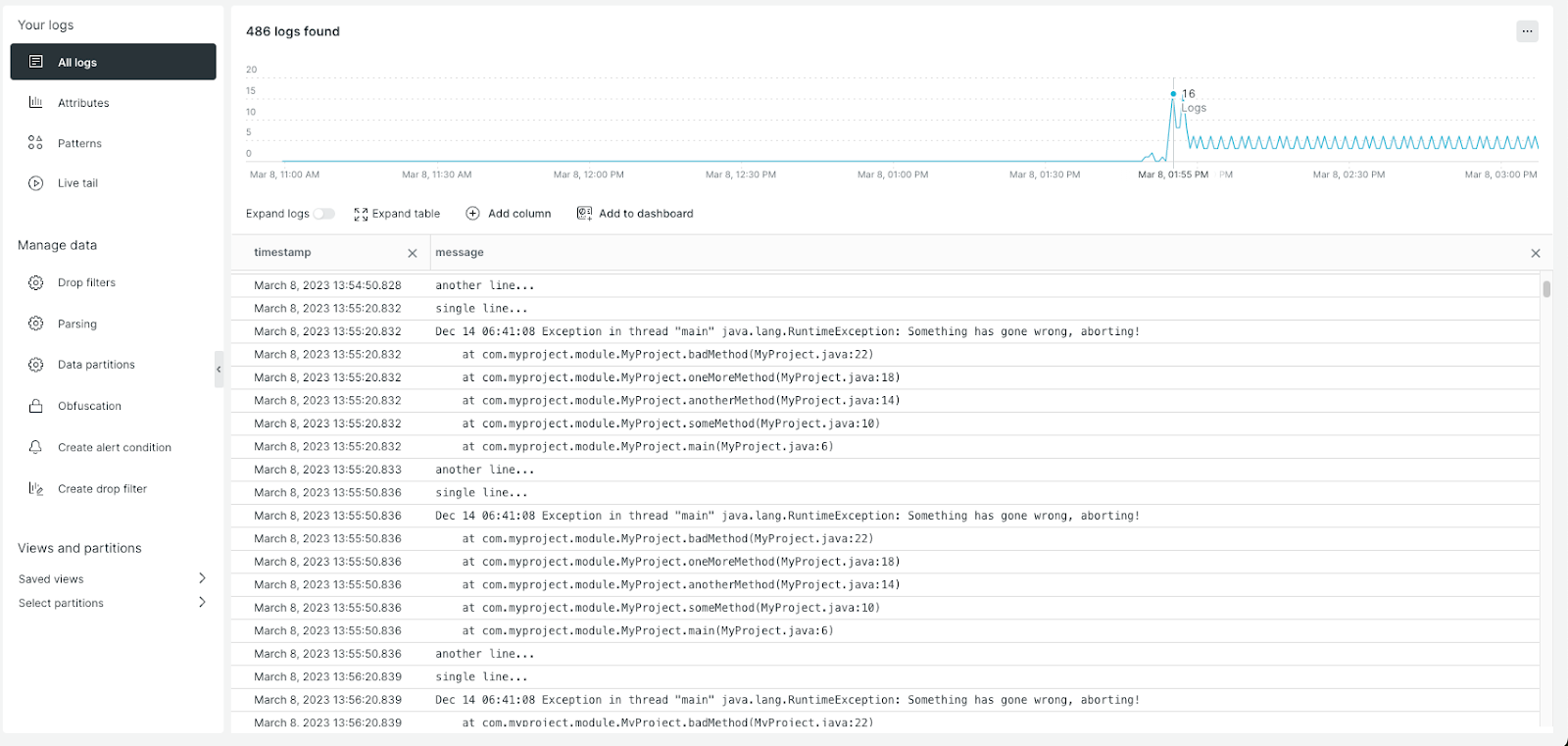
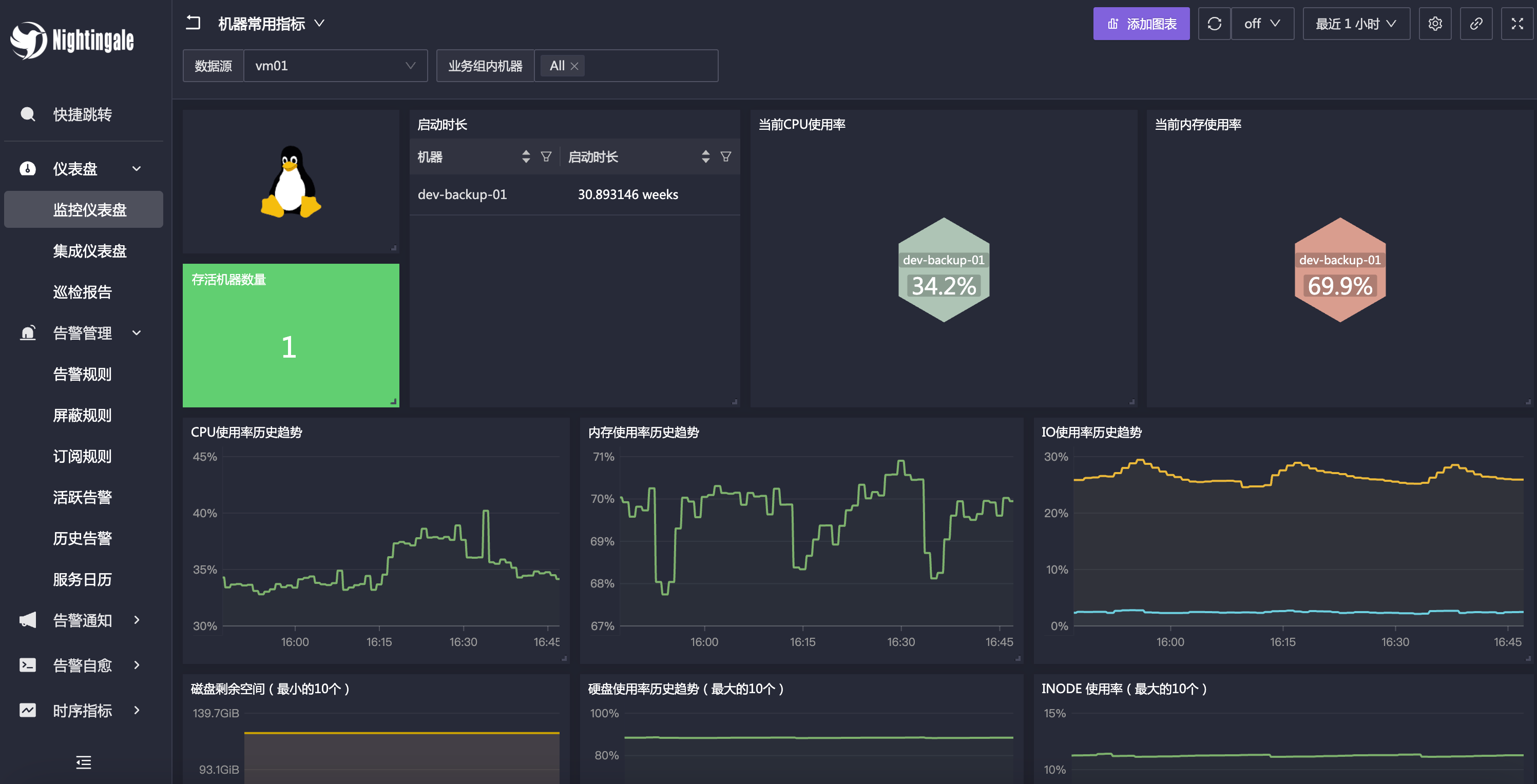
Posted by 快猫运营团队 on 2024-10-19 12:05:42
Posted by 秦晓辉 on 2024-10-18 18:05:08
Posted by 快猫运营团队 on 2024-10-18 15:08:59
Posted by 快猫运营团队 on 2024-10-18 10:08:59
Posted by 快猫运营团队 on 2024-10-18 08:39:06
Posted by 快猫运营团队 on 2024-10-17 08:26:05
Posted by 快猫运营团队 on 2024-10-16 14:49:05
Posted by 译文 on 2024-10-16 12:05:08
Posted by 快猫运营团队 on 2024-10-16 10:08:34
Posted by 译文 on 2024-10-15 17:09:33
Posted by 译文 on 2024-10-15 14:37:47
Posted by 快猫运营团队 on 2024-10-15 14:00:29
Posted by 译文 on 2024-10-15 09:22:57
Posted by 快猫运营团队 on 2024-10-14 16:38:19
Posted by Diogo Daniel Pacheco on 2024-10-14 14:56:54
Posted by 快猫运营团队 on 2024-10-14 11:01:58
Posted by 快猫运营团队 on 2024-10-13 16:16:30
Posted by 译文 on 2024-10-12 10:13:08
Posted by gene on 2024-10-12 07:31:12
Posted by 快猫运营团队 on 2024-10-11 16:33:50