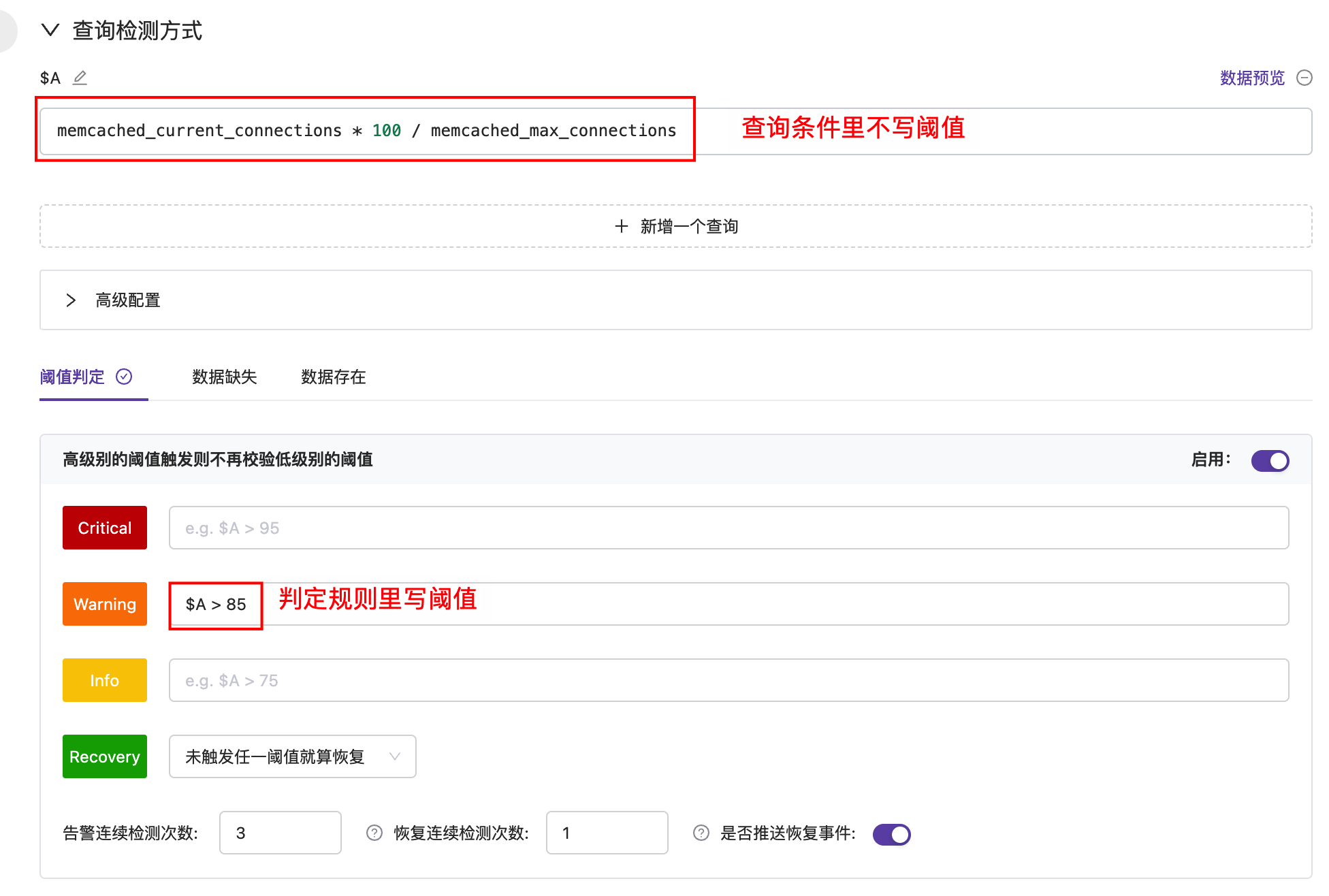
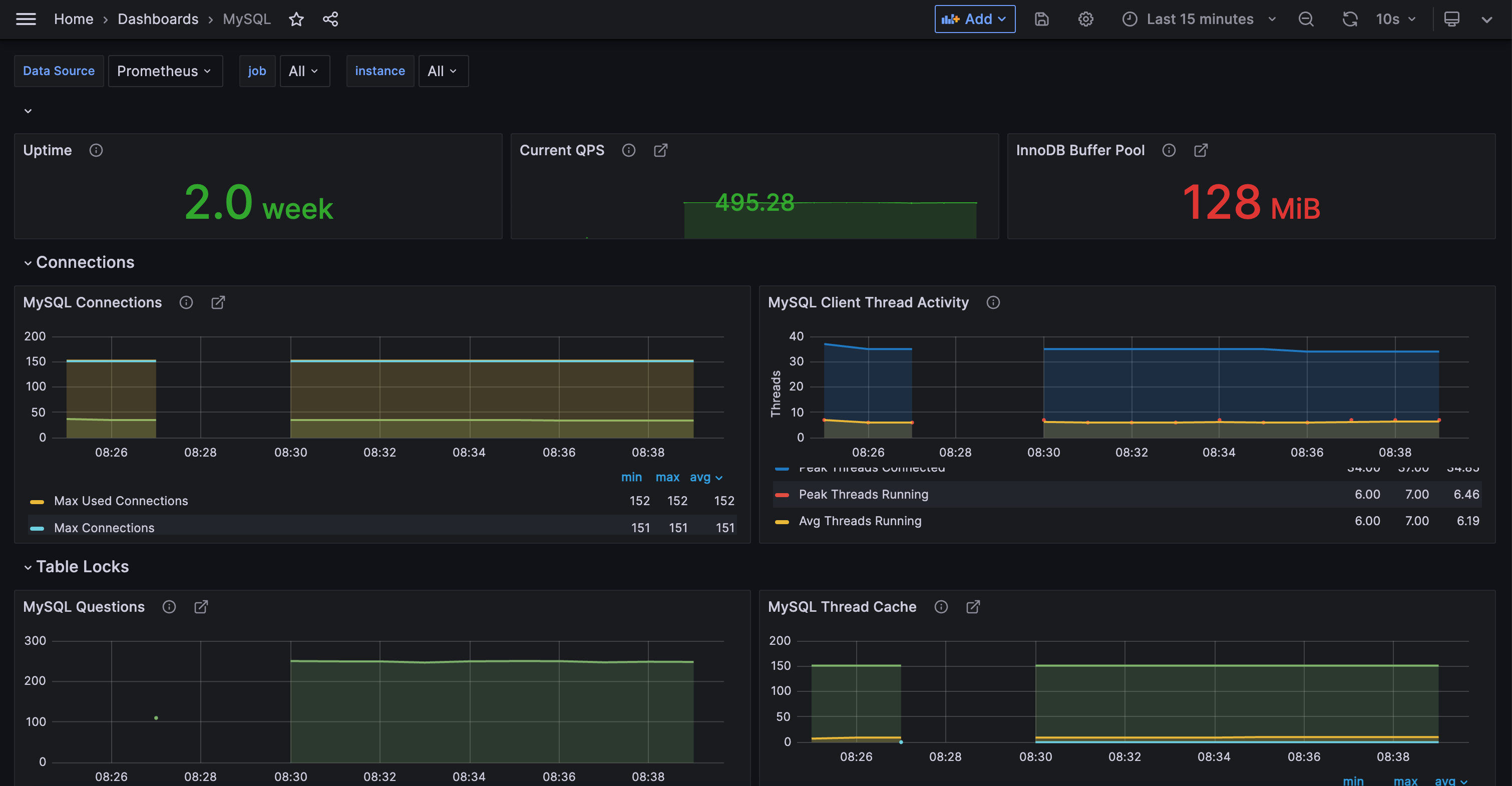
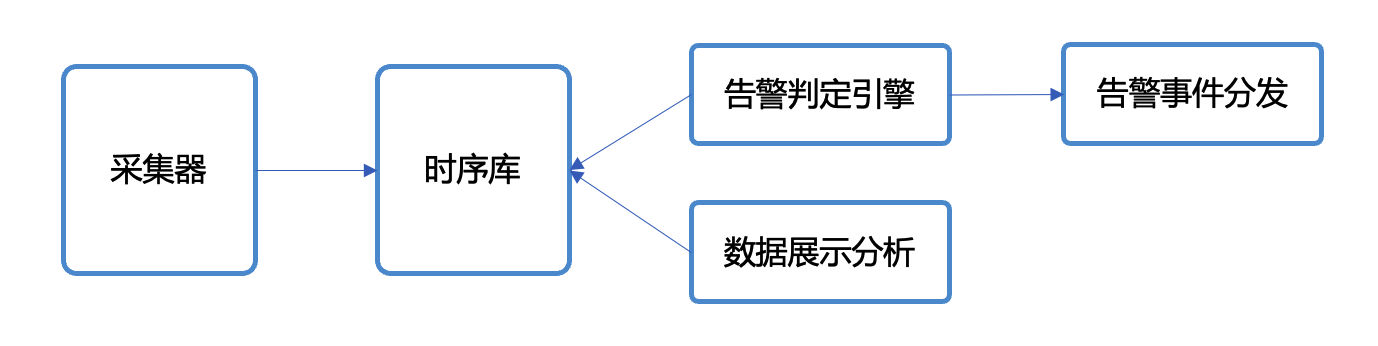
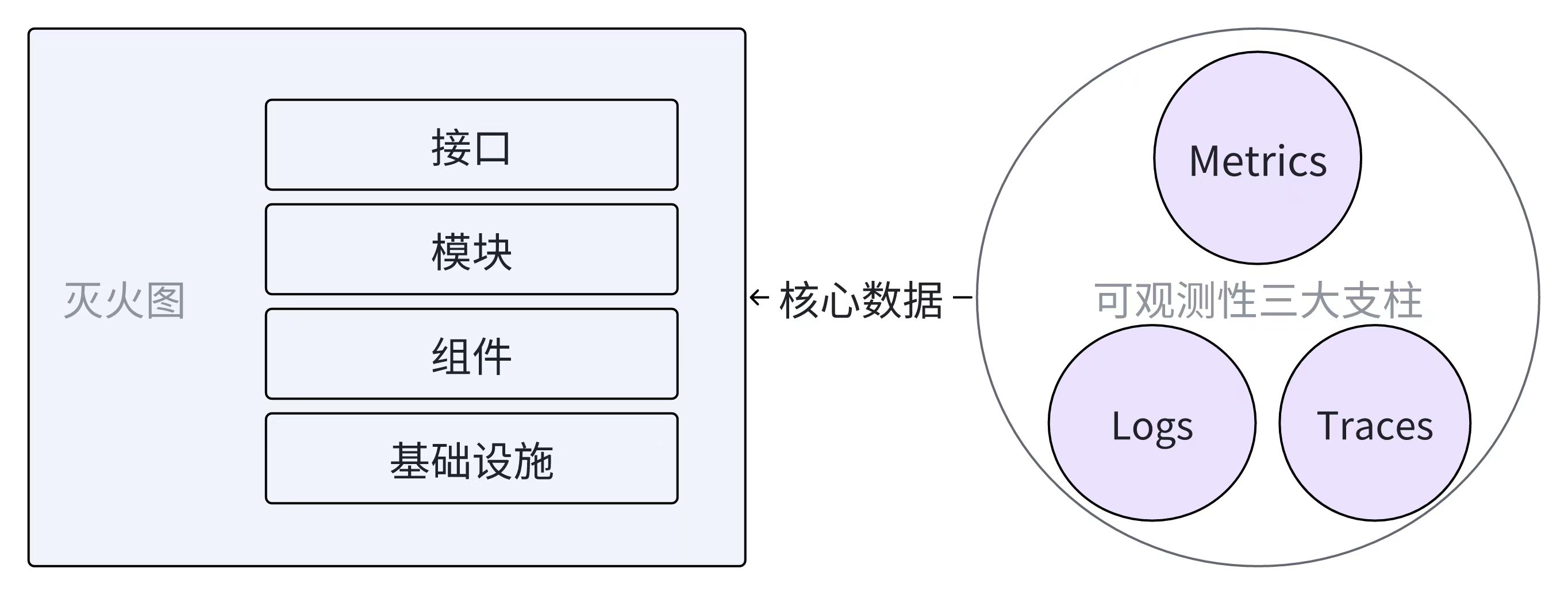
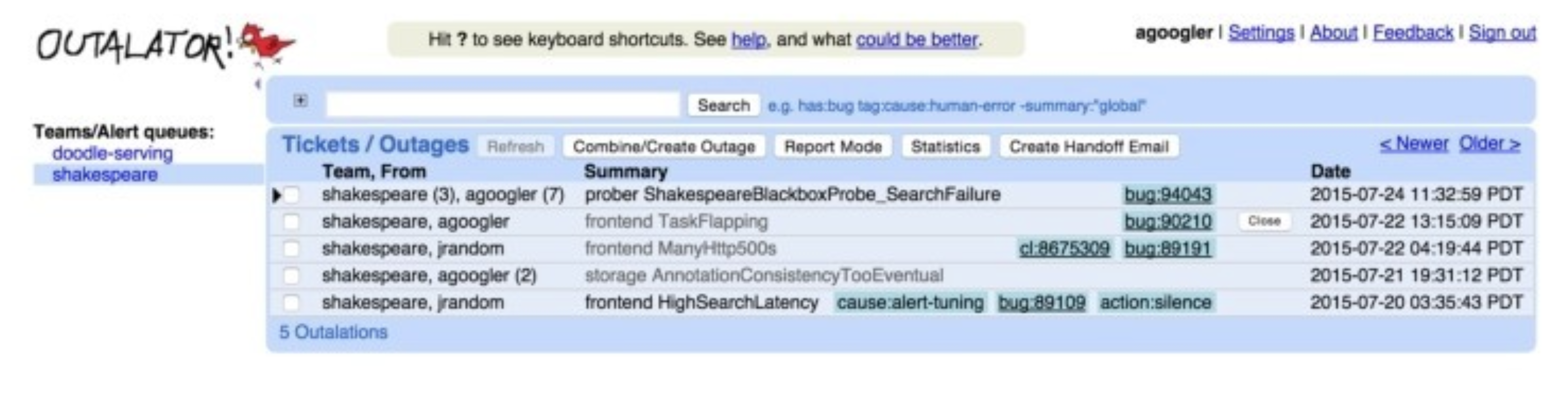
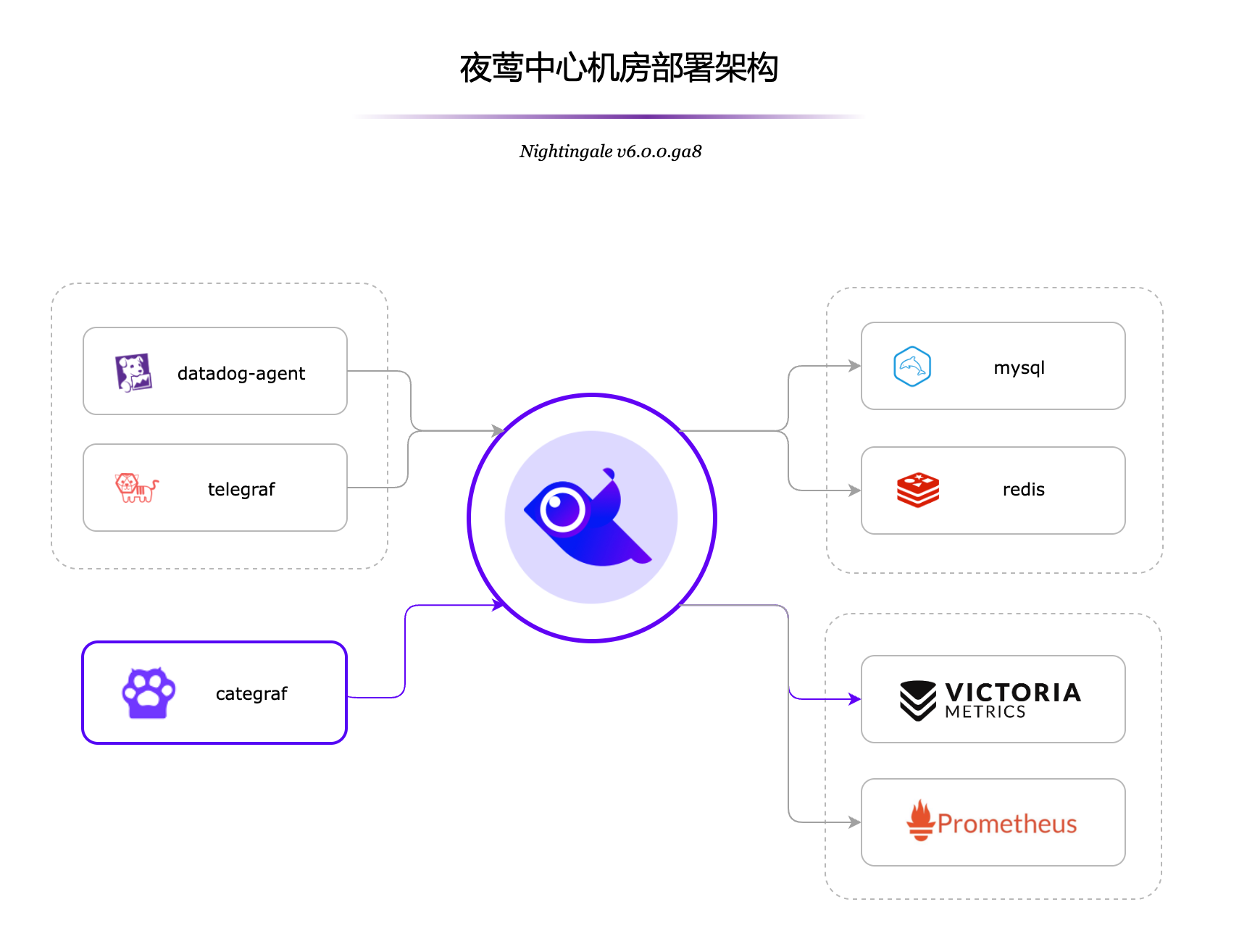
如果你在意生产环境的稳定性,希望自己的服务出问题时及时发现,大概率就有日志监控告警的需求,比如发现日志中有 Error 或 Exception 关键字就告警,比如通过日志统计某个服务的 95 分位延迟数据,延迟过高就告警,比如通过日志统计某个服务的 status code,出现多个 5xx 就告警,等等。日志可能存储在 ElasticSearch、Loki、ClickHouse 等系统中,告警系统的核心逻辑也比较清晰,就是根据用户配置的查询语句,周期性查询这些存储,并对查询结果做阈值判定,如果达到阈值就触发告警。比如统计 5 分钟内出现的 Error 数量,如果大于 10 就告警。