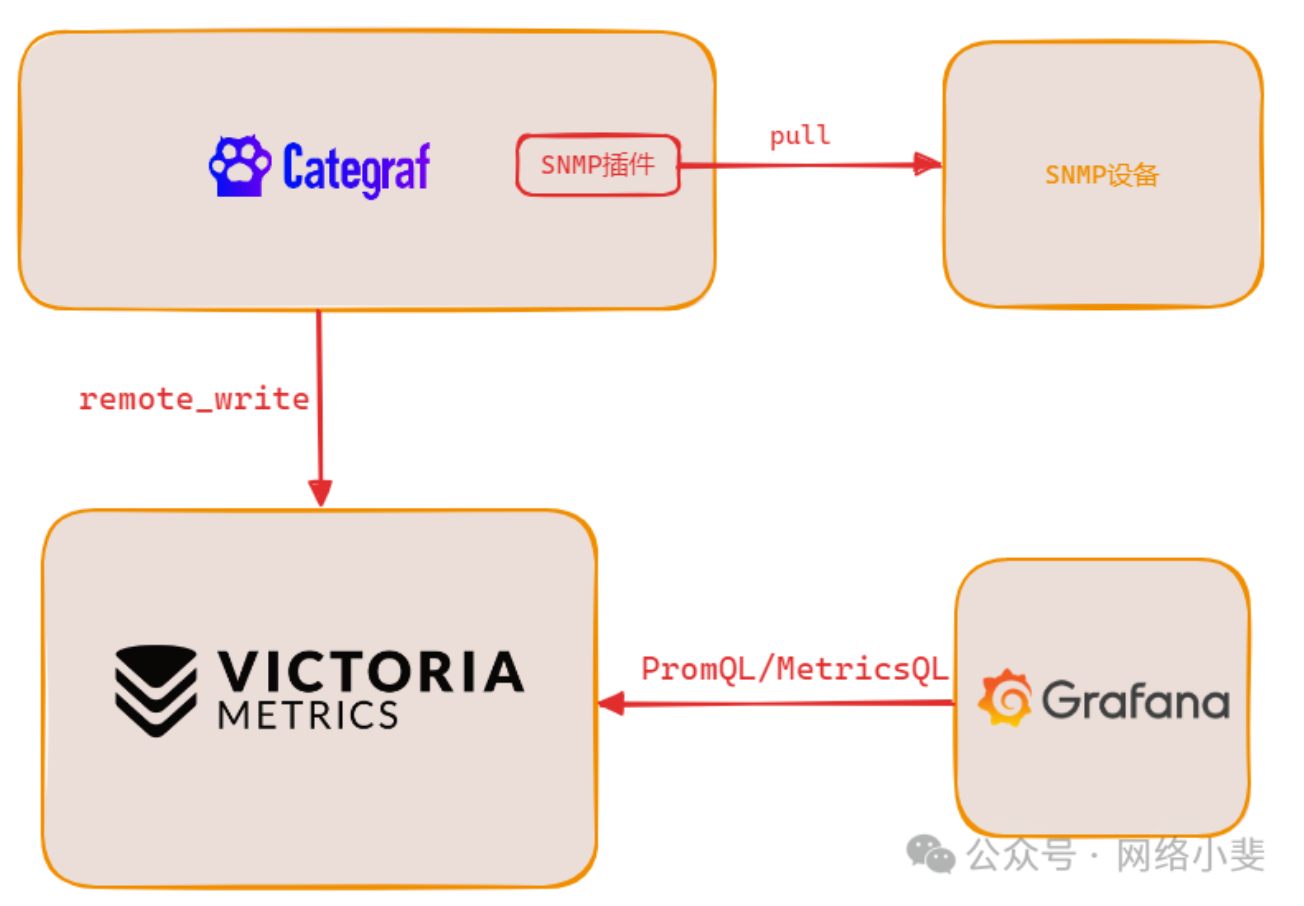
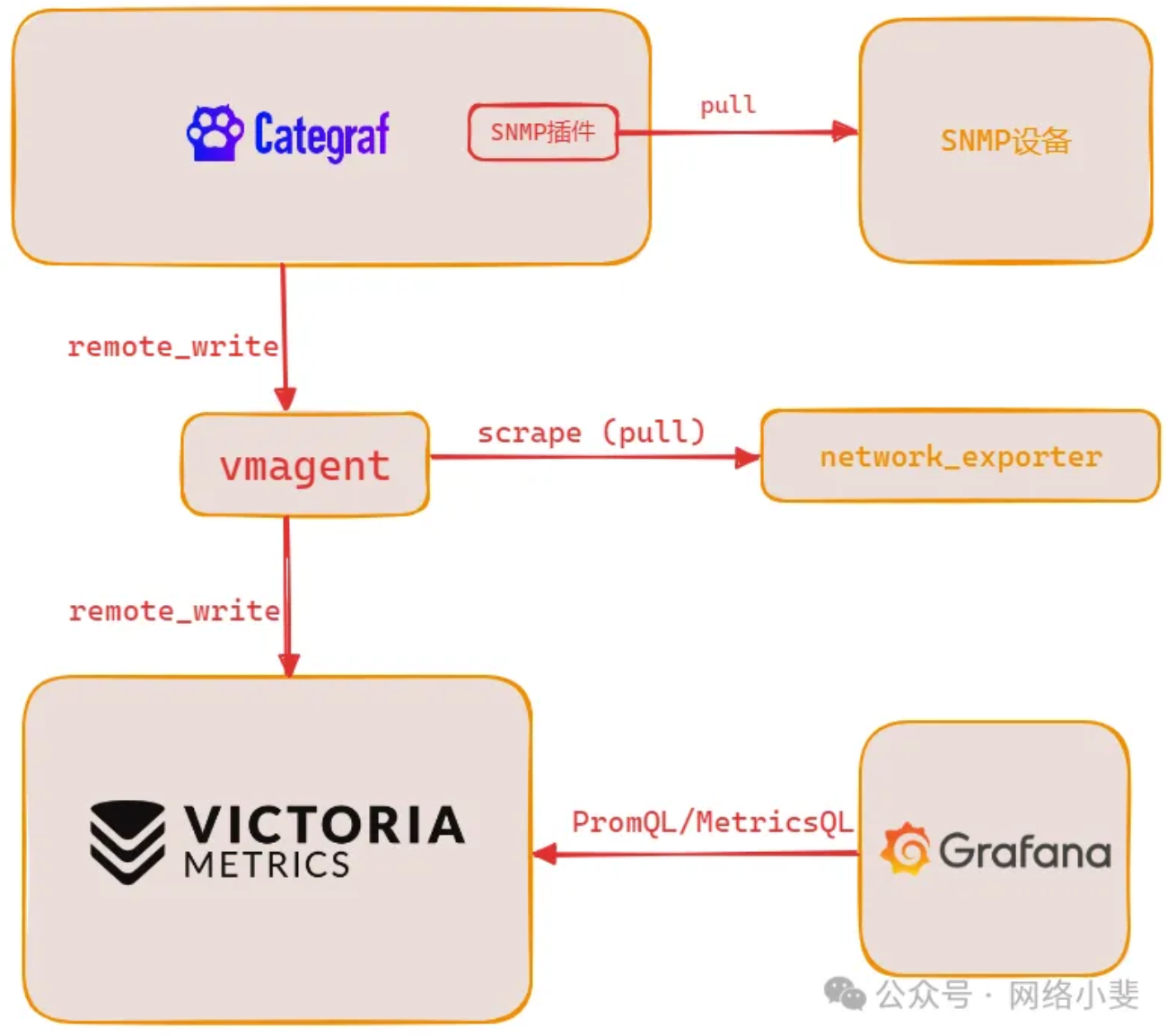
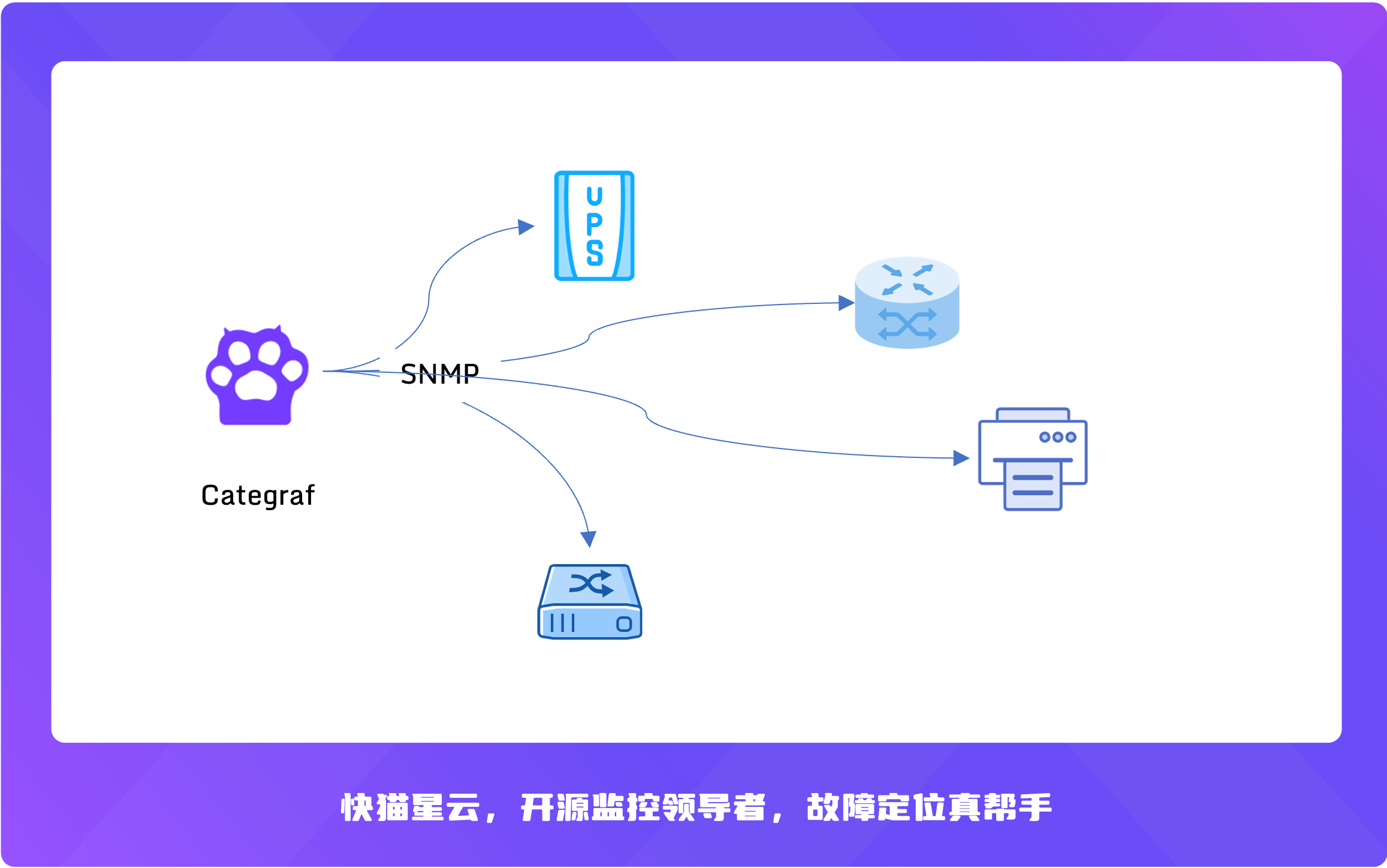
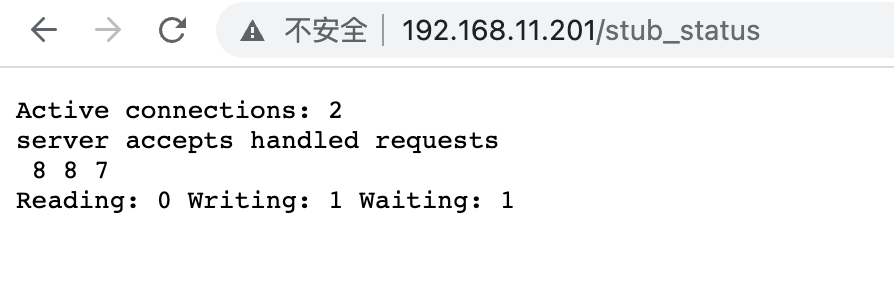
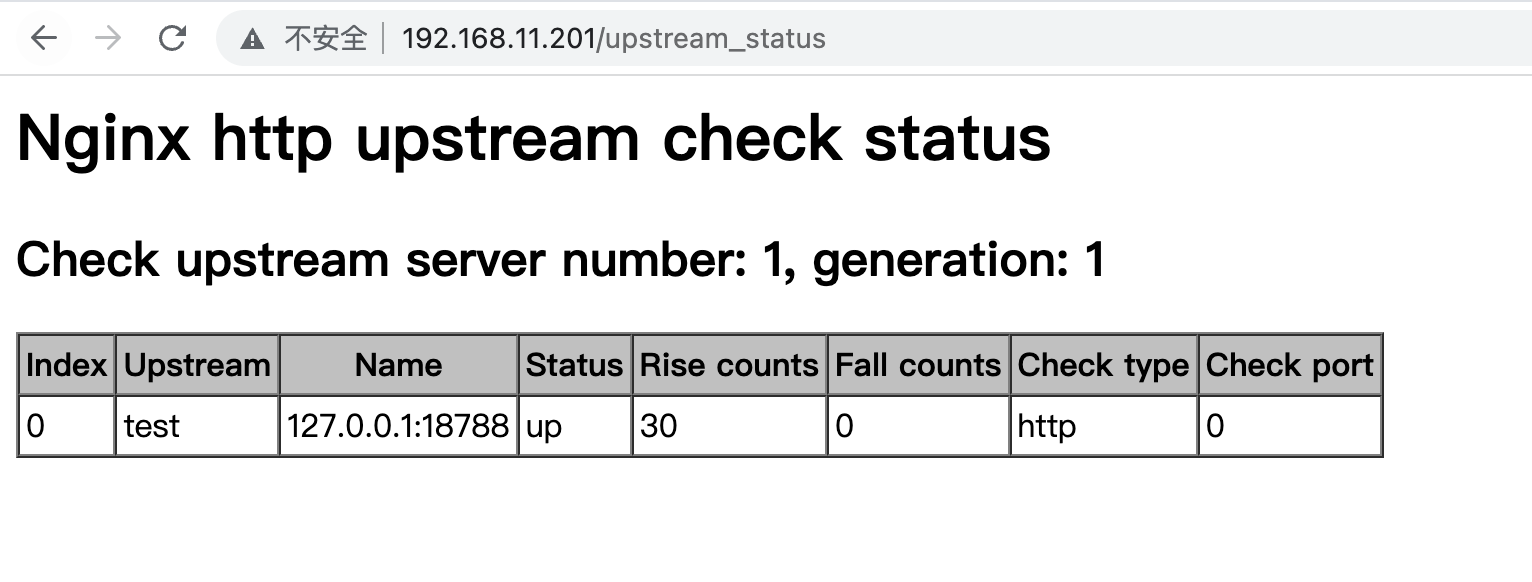
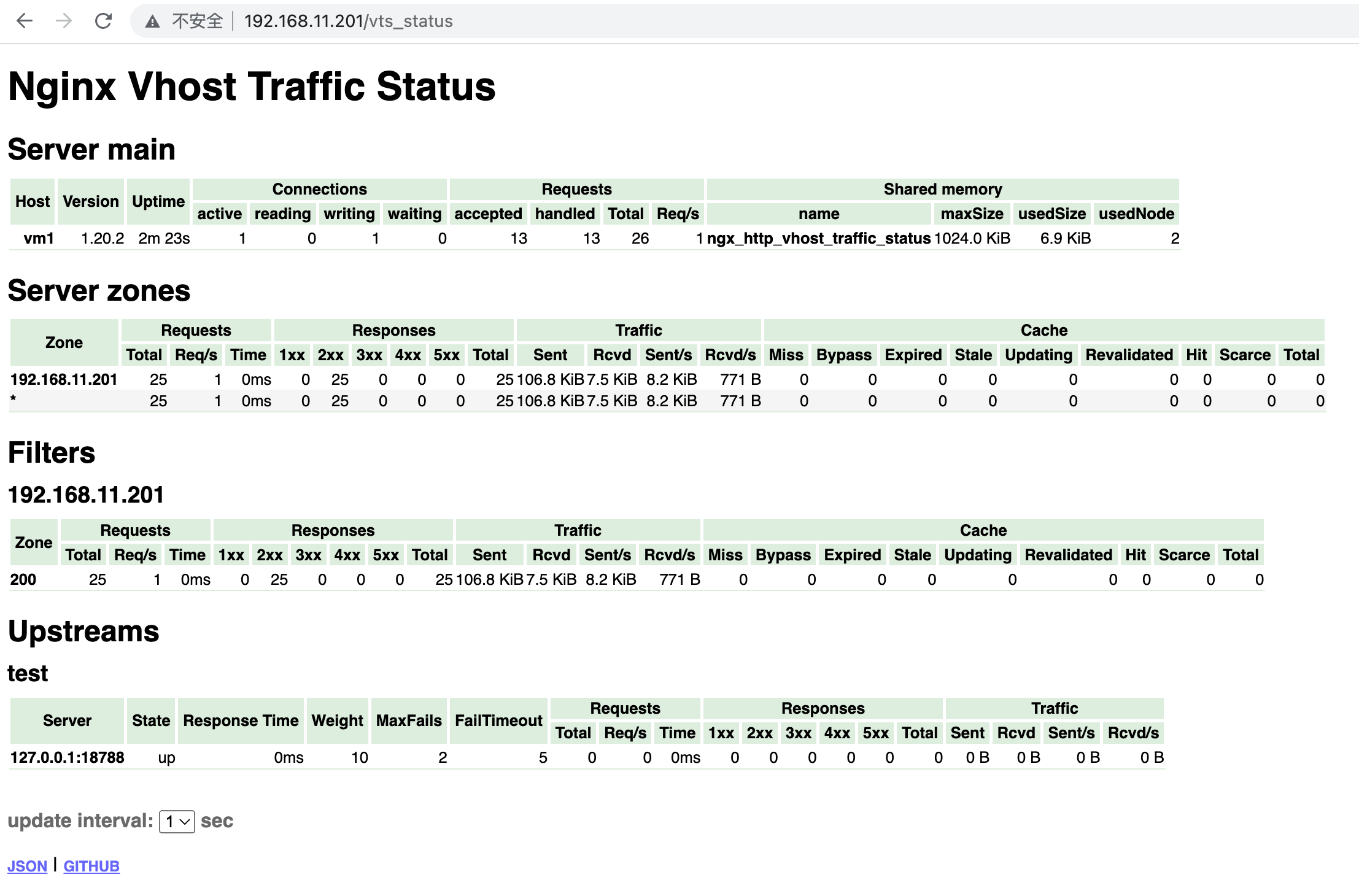
Posted by 快猫技术 on 2026-01-22 15:00:00
Posted by 巴辉特 on 2026-01-18 19:11:51
Posted by 巴辉特 on 2026-01-18 19:11:38
Posted by 巴辉特 on 2026-01-18 19:11:27
Posted by 巴辉特 on 2026-01-18 19:11:14
Posted by 巴辉特 on 2026-01-18 19:11:04
Posted by 巴辉特 on 2026-01-09 15:28:07
Posted by 巴辉特 on 2026-01-09 11:17:57
Posted by 孔飞@快猫星云 on 2026-01-09 11:16:02
Posted by 宋芮涛@Zenlayer 孔飞@快猫星云 on 2026-01-09 11:15:10
Posted by 网络小斐 on 2026-01-09 11:14:43
Posted by 巴辉特 on 2026-01-09 11:12:15
Posted by 孔飞@快猫星云 on 2026-01-09 11:11:46
Posted by 网络小斐 on 2026-01-09 11:10:09
Posted by 秦晓辉@快猫星云 on 2026-01-09 11:09:44
Posted by 孔飞@快猫星云 on 2026-01-09 11:09:22
Posted by 快猫运营 on 2026-01-09 11:08:50
Posted by 孔飞@快猫星云 on 2026-01-09 11:07:00