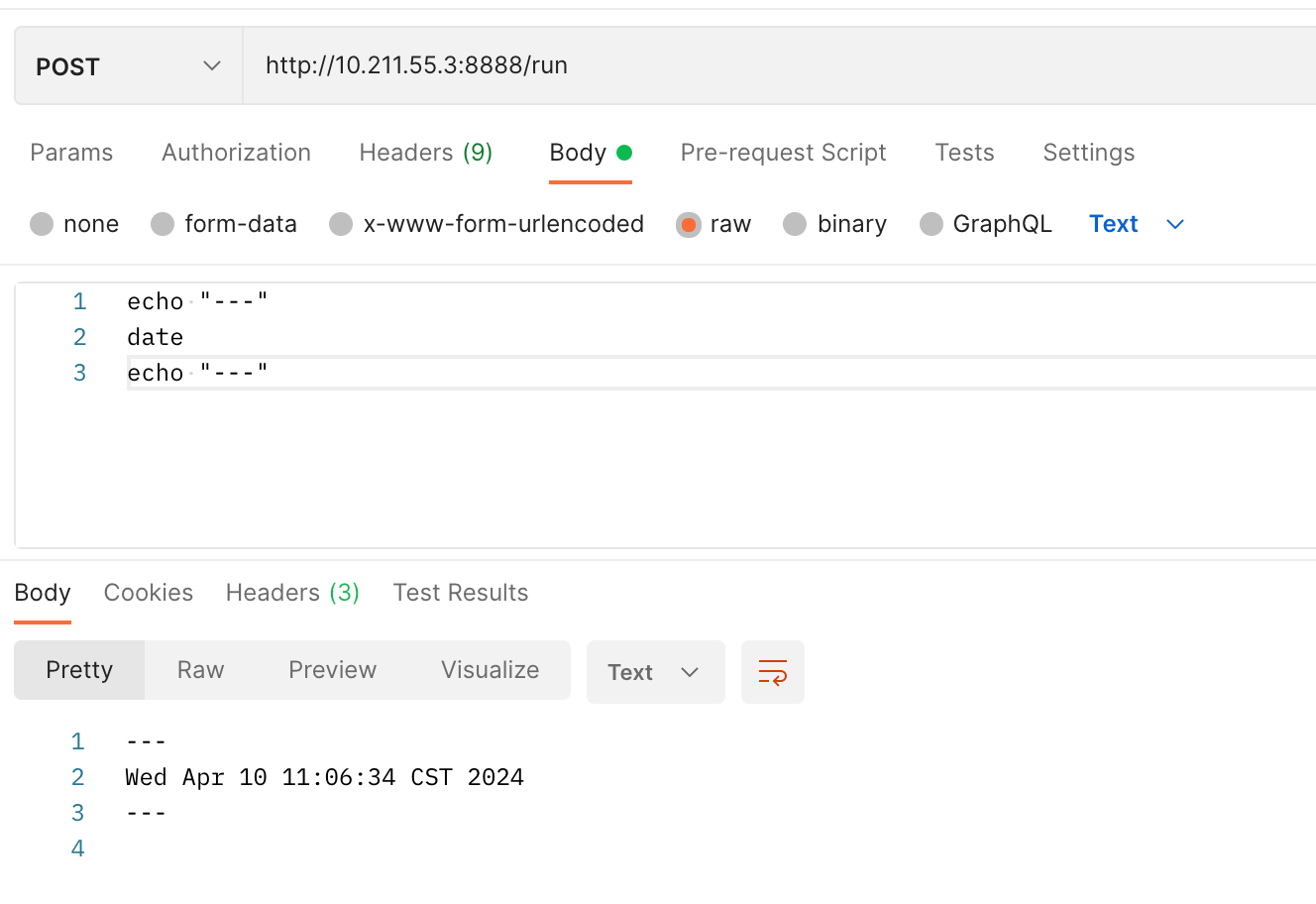
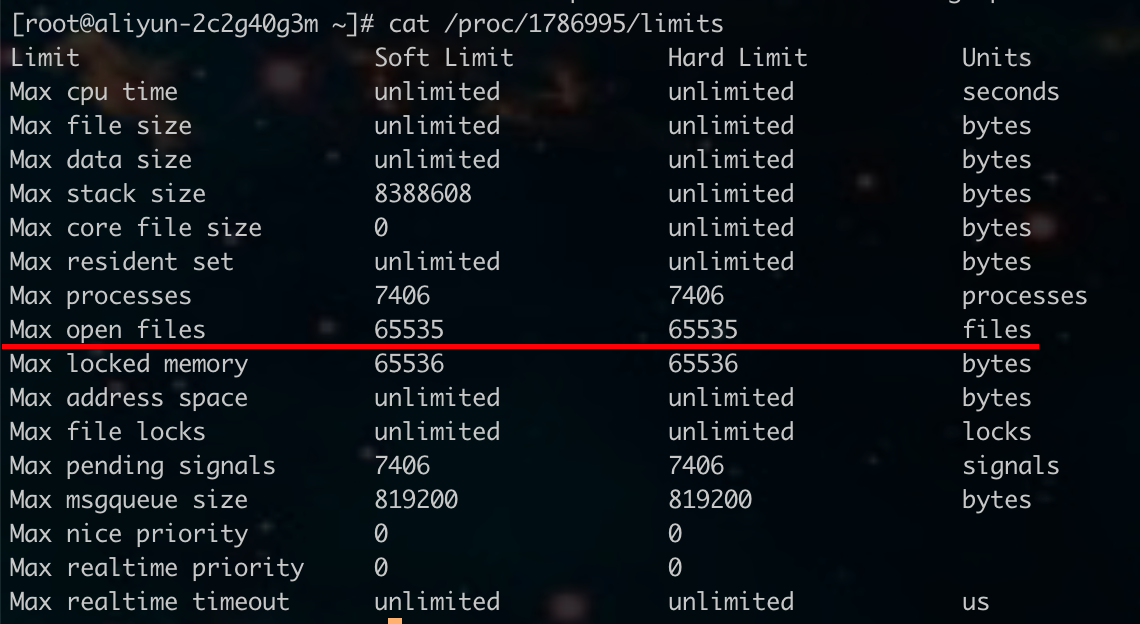
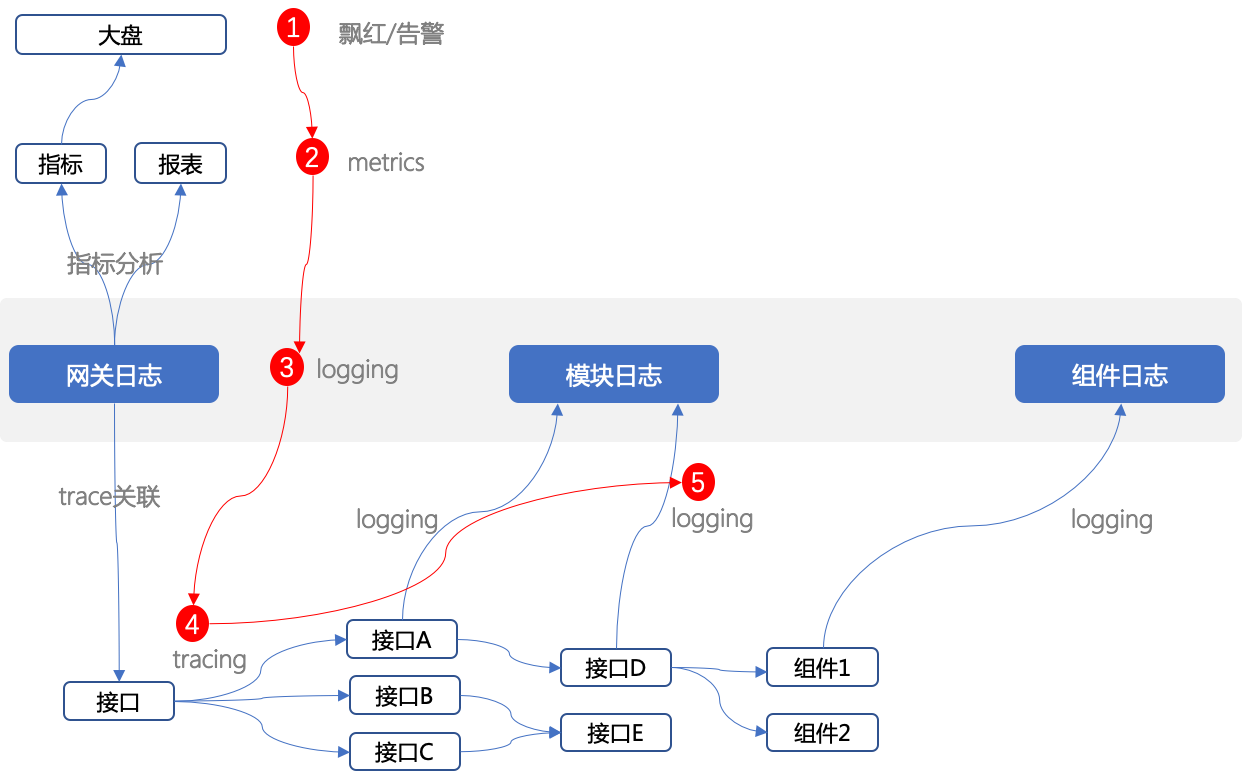
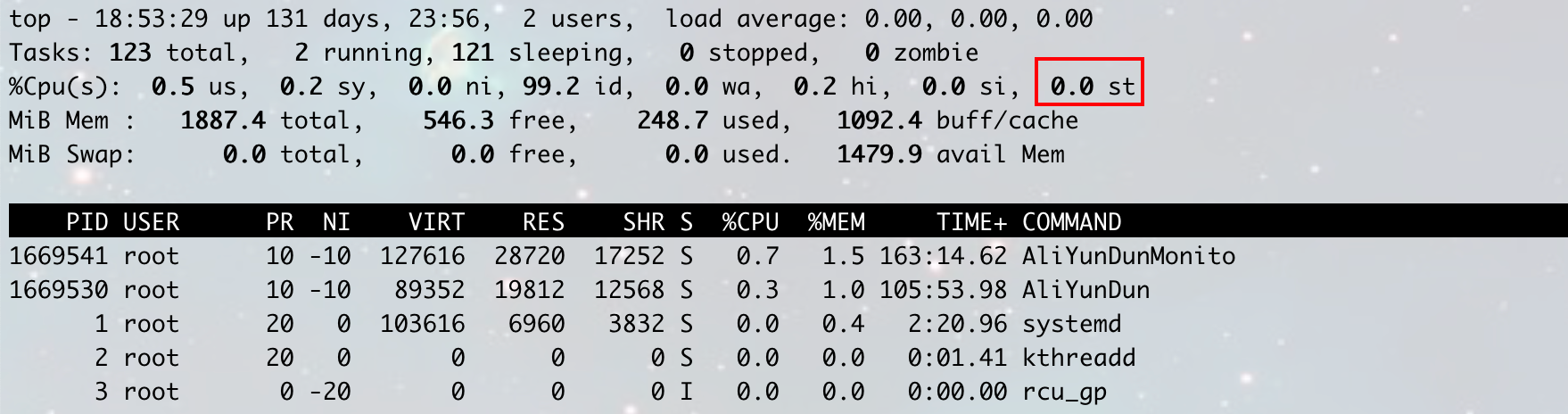
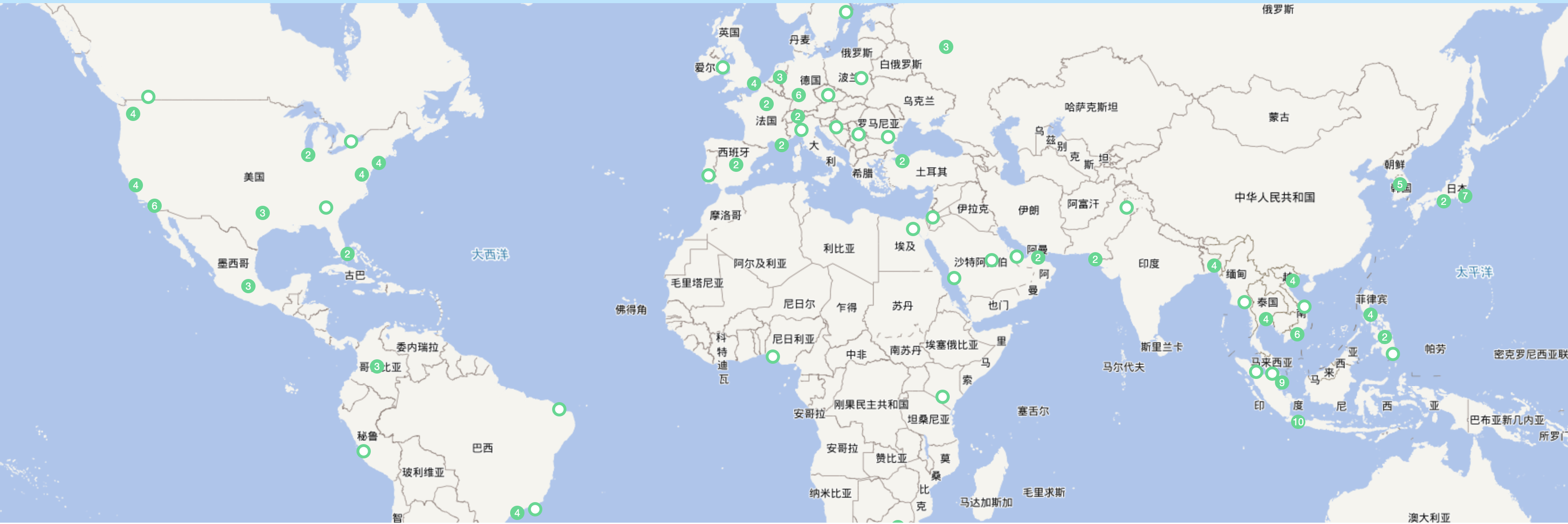
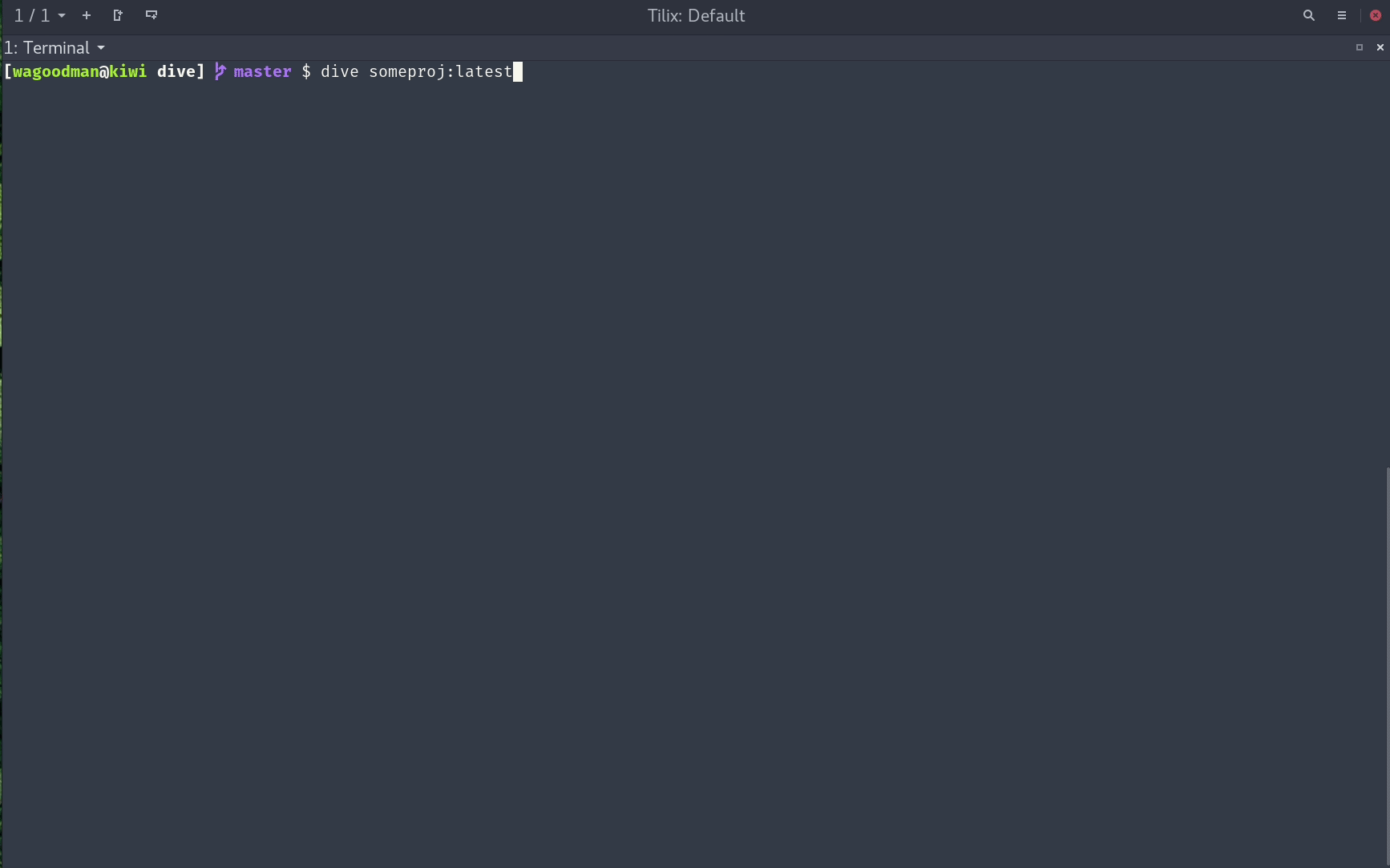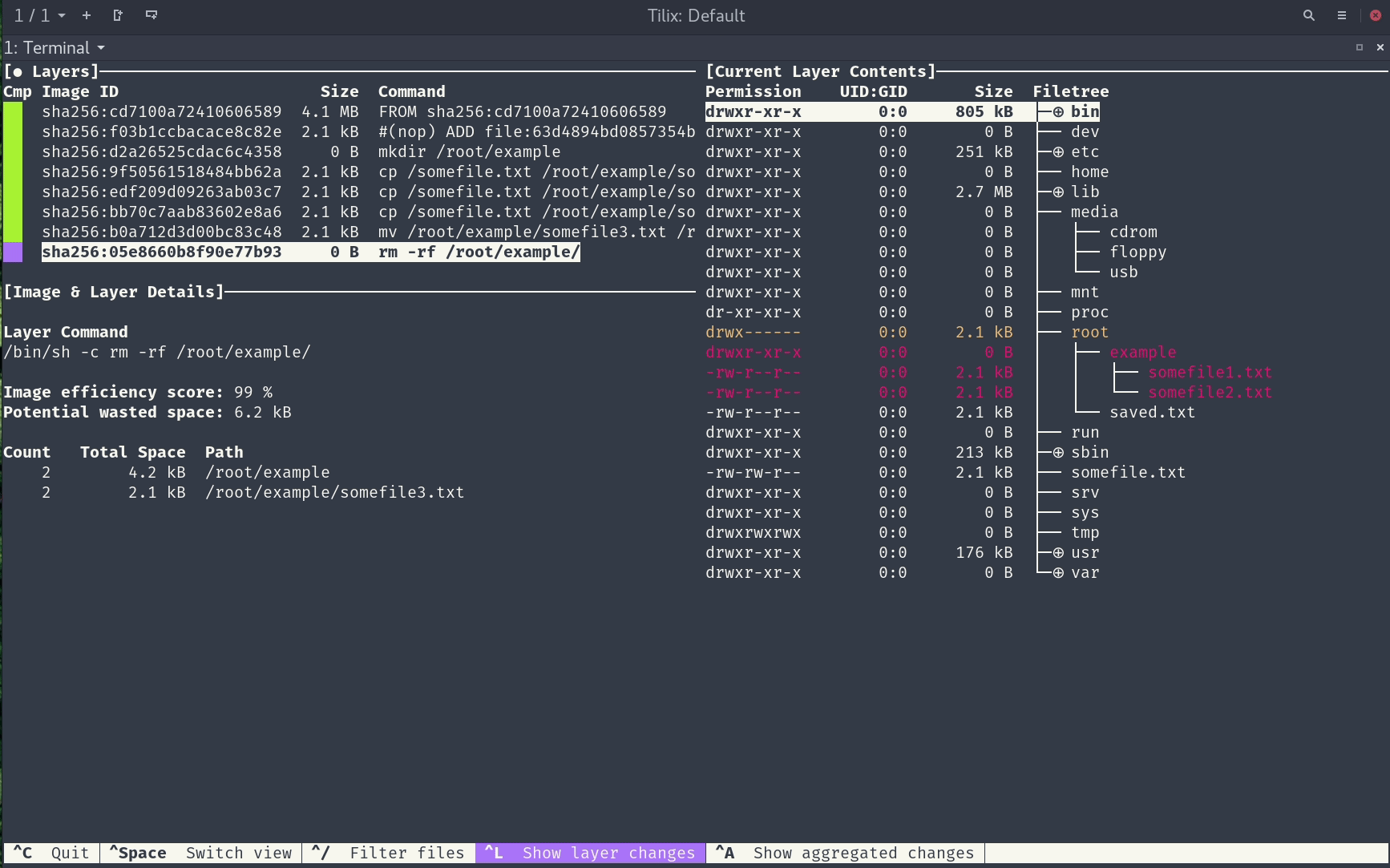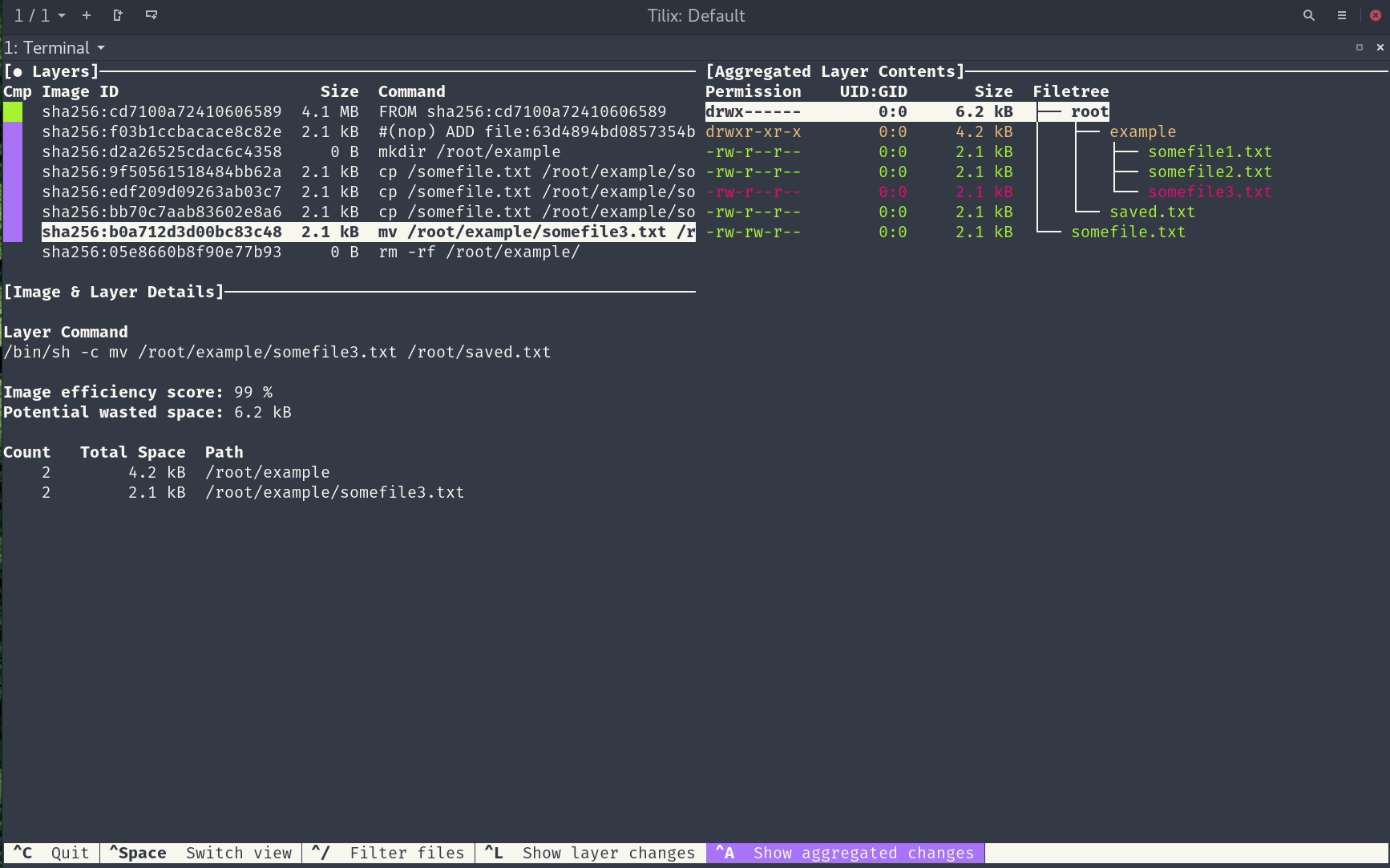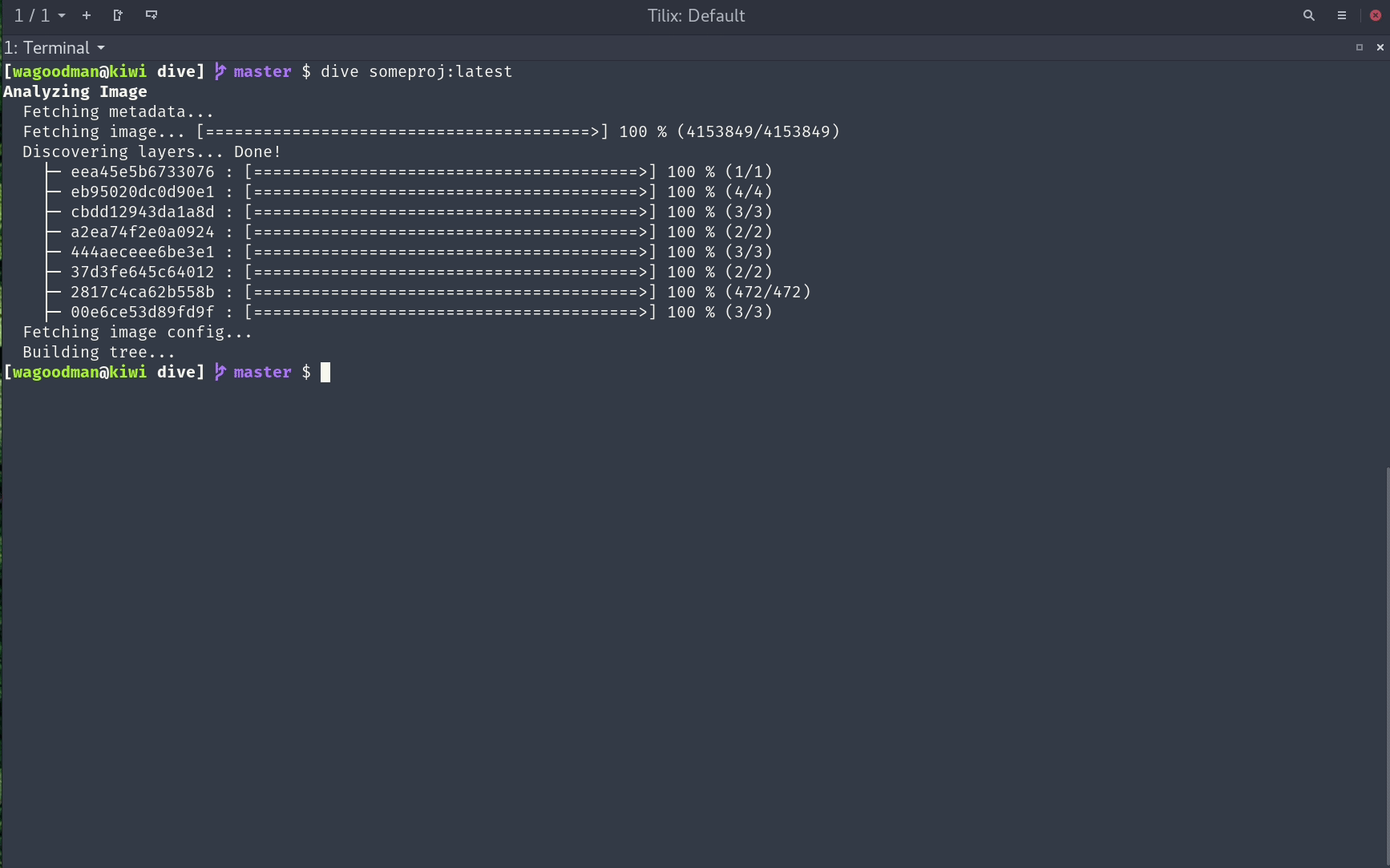
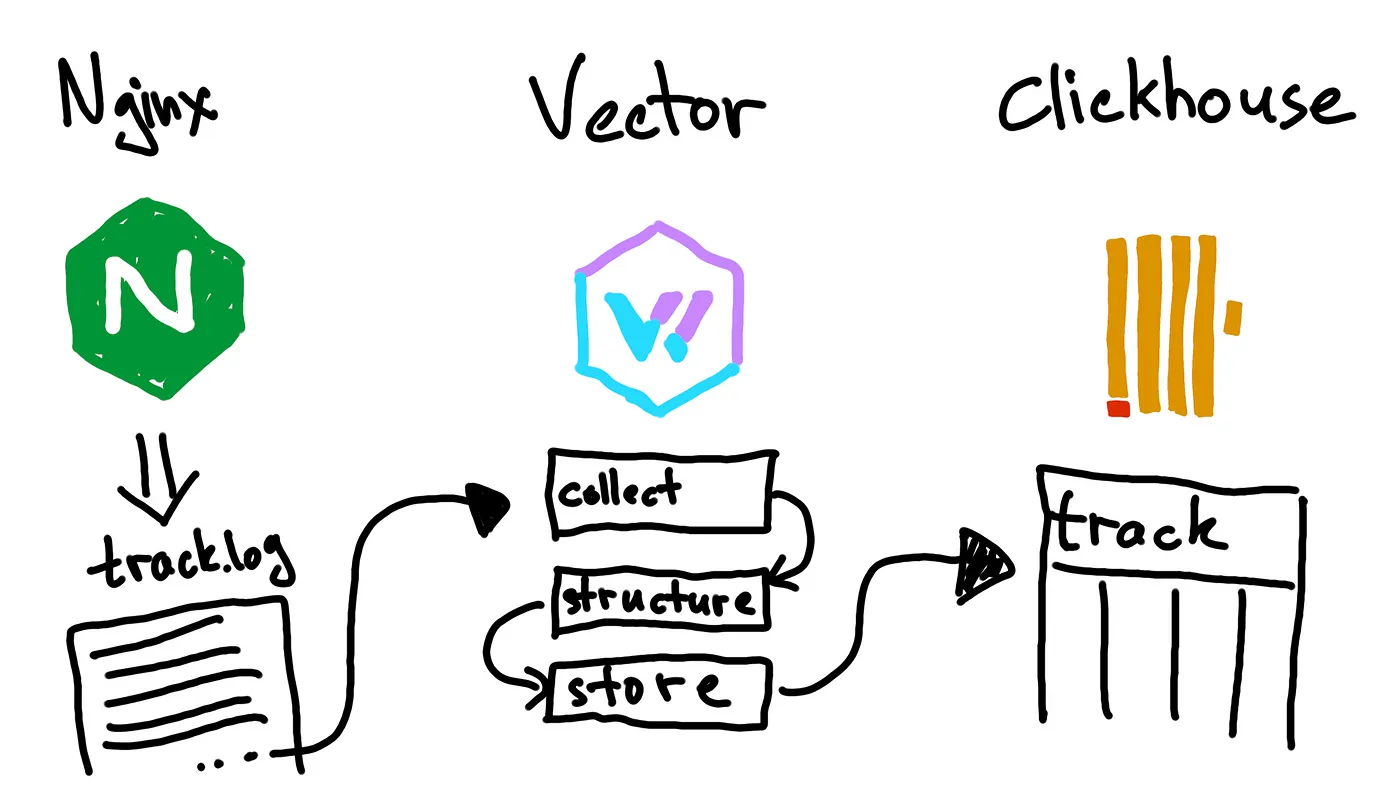
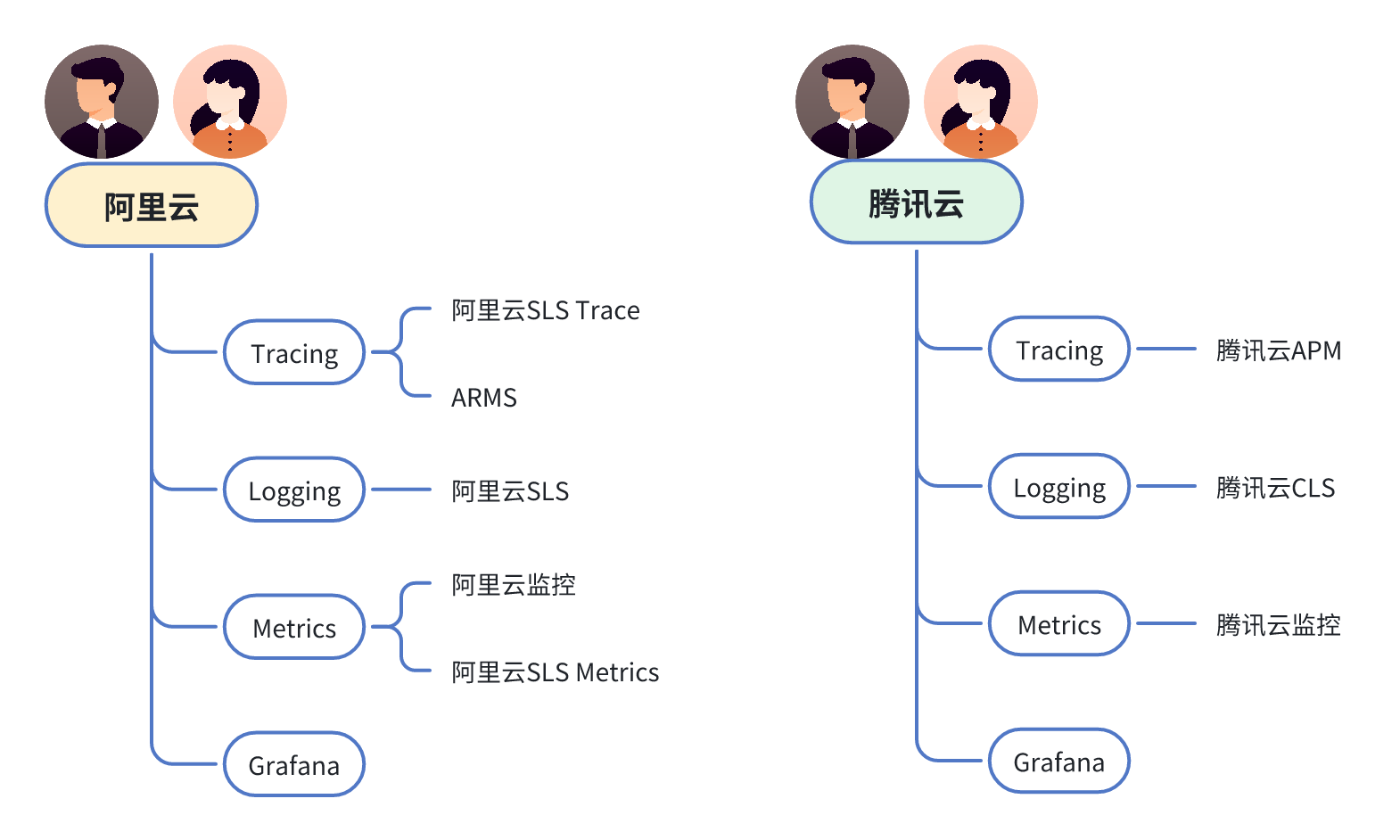
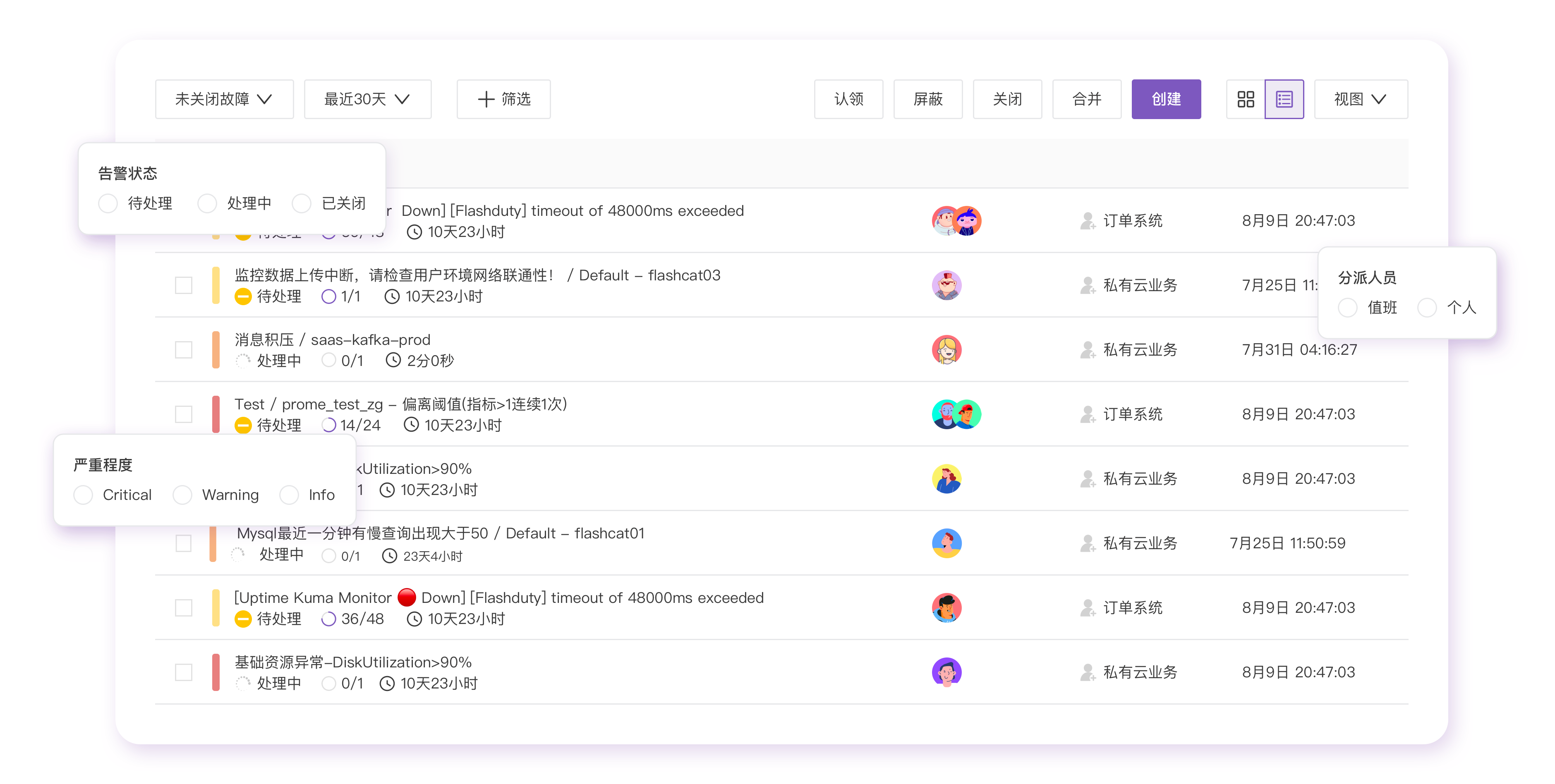
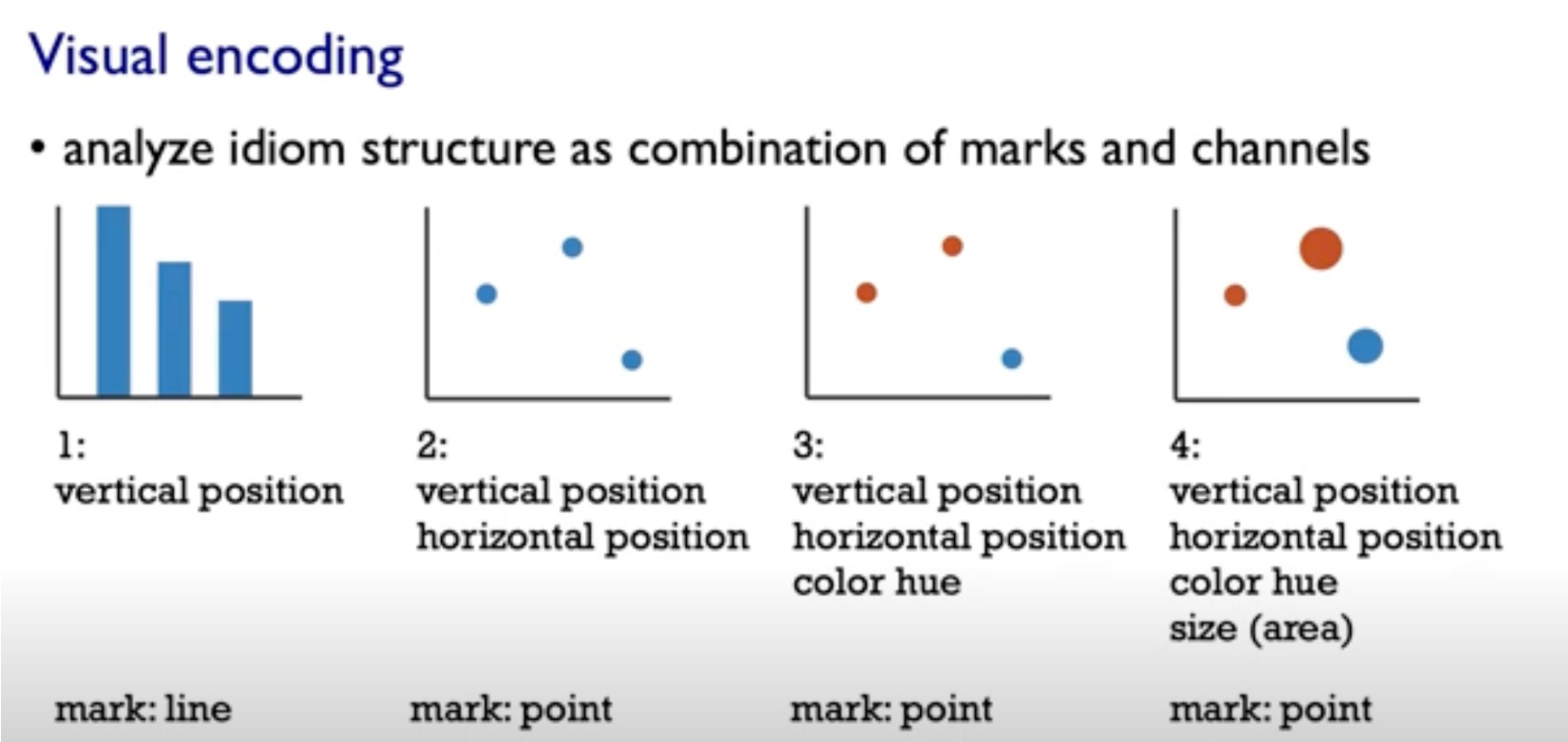
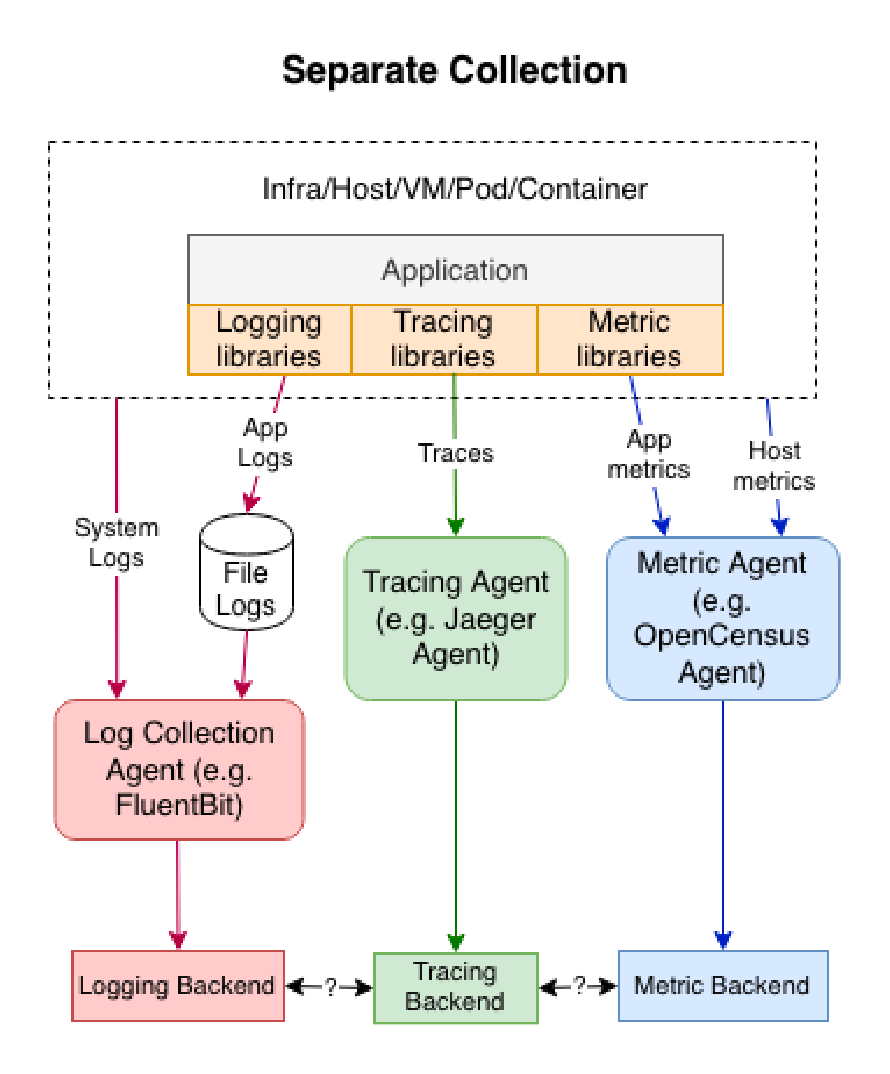
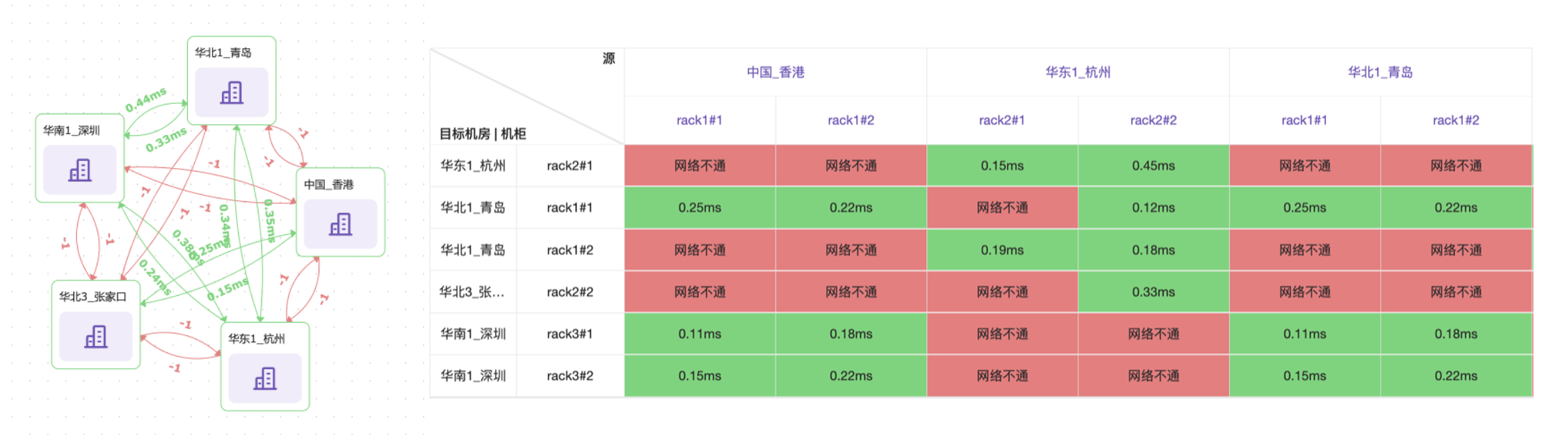
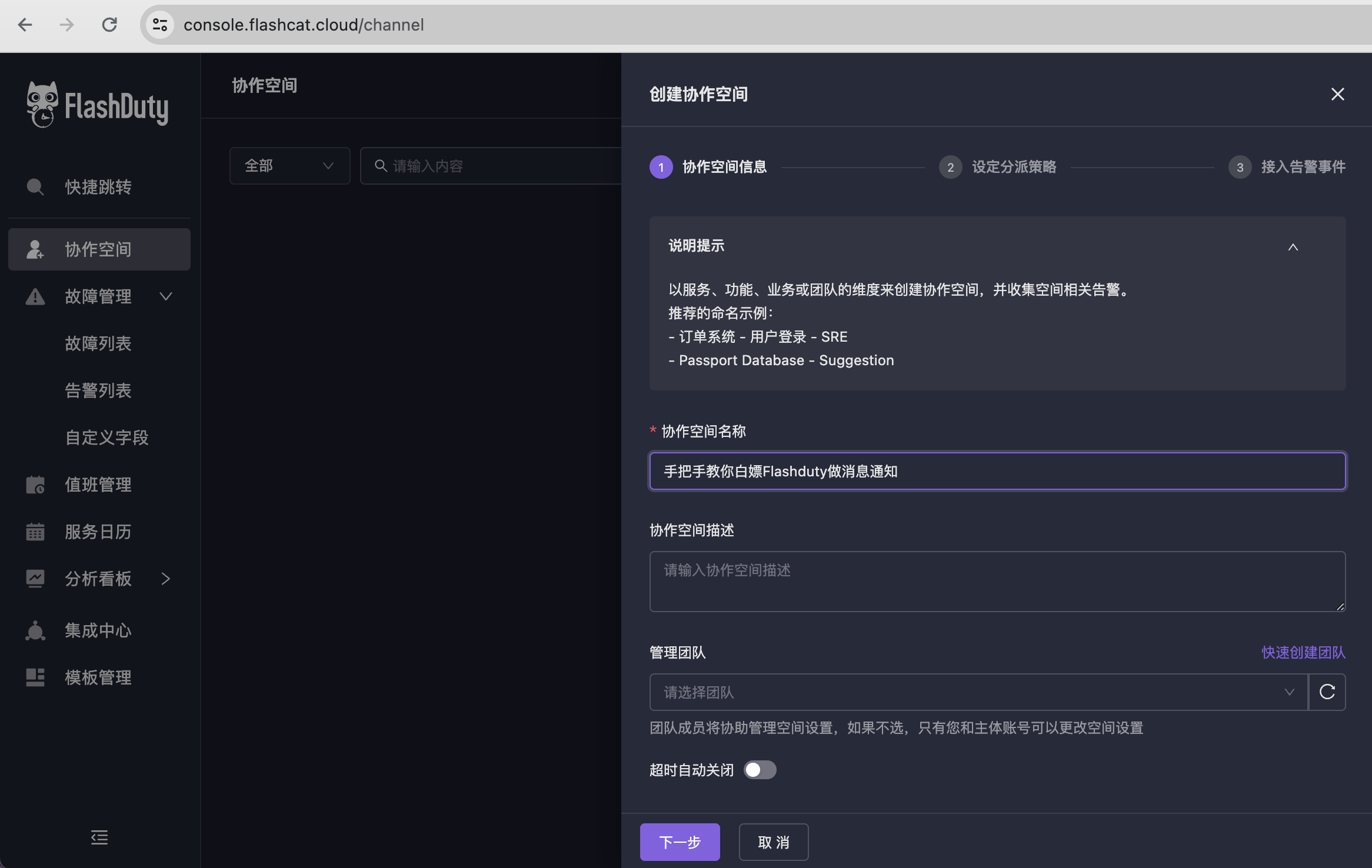
Posted by 巴辉特 on 2024-04-10 00:08:08
Posted by 巴辉特 on 2024-04-09 00:08:08
Posted by 巴辉特 on 2024-04-07 00:08:08
Posted by 巴辉特 on 2024-04-01 00:08:08
Posted by 快猫技术 on 2024-03-28 06:06:10
Posted by 巴辉特 on 2024-03-21 00:08:08
Posted by 巴辉特 on 2024-03-20 00:08:08
Posted by 巴辉特 on 2024-03-18 00:08:08
Posted by Flashcat on 2024-03-12 00:00:00
Posted by 巴辉特 on 2024-03-12 00:08:08
Posted by Denys Golotiuk, Ulric on 2024-03-07 00:06:10
Posted by Flashcat on 2024-03-05 00:00:00
Posted by 快猫技术 on 2024-03-04 00:06:00
Posted by 戴夏清@快猫星云 on 2024-03-01 00:06:00
Posted by Flashcat on 2024-02-26 10:06:10
Posted by 快猫星云 on 2024-02-18 00:00:00
Posted by 保清@快猫技术 on 2024-02-01 04:06:10
Posted by guguji5 on 2024-02-01 03:06:10
Posted by 快猫星云 on 2024-01-30 06:06:10