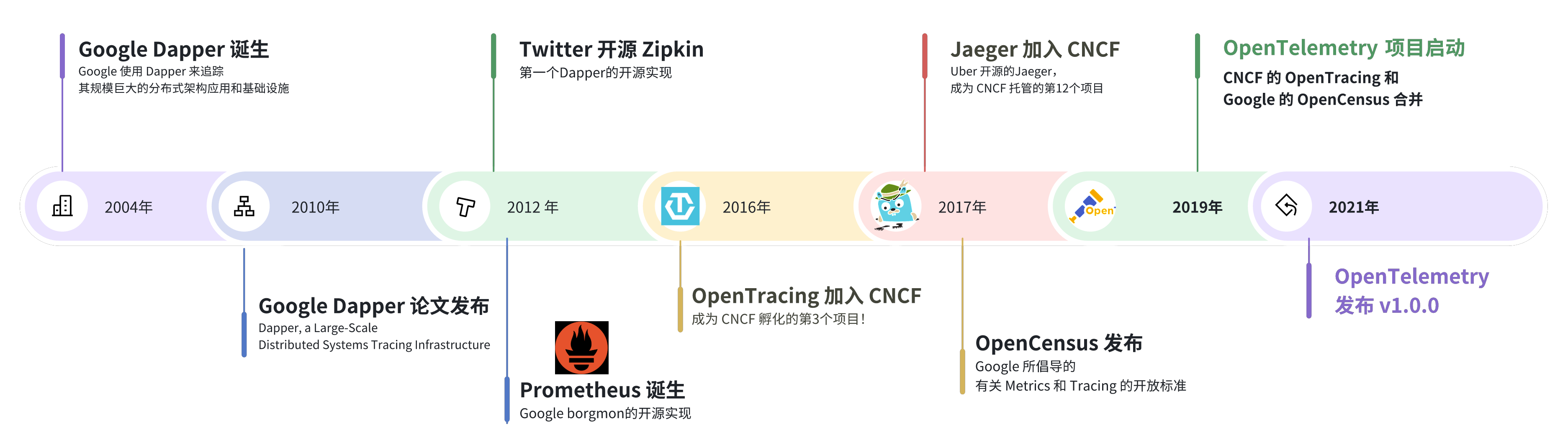
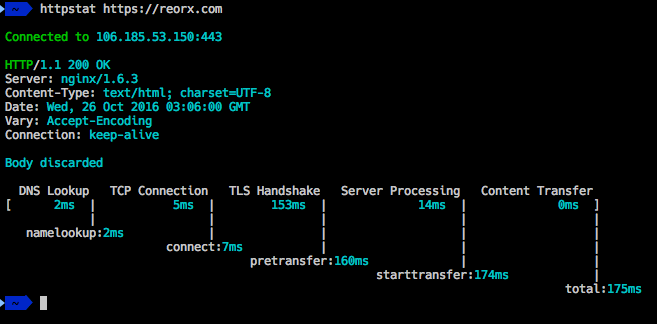
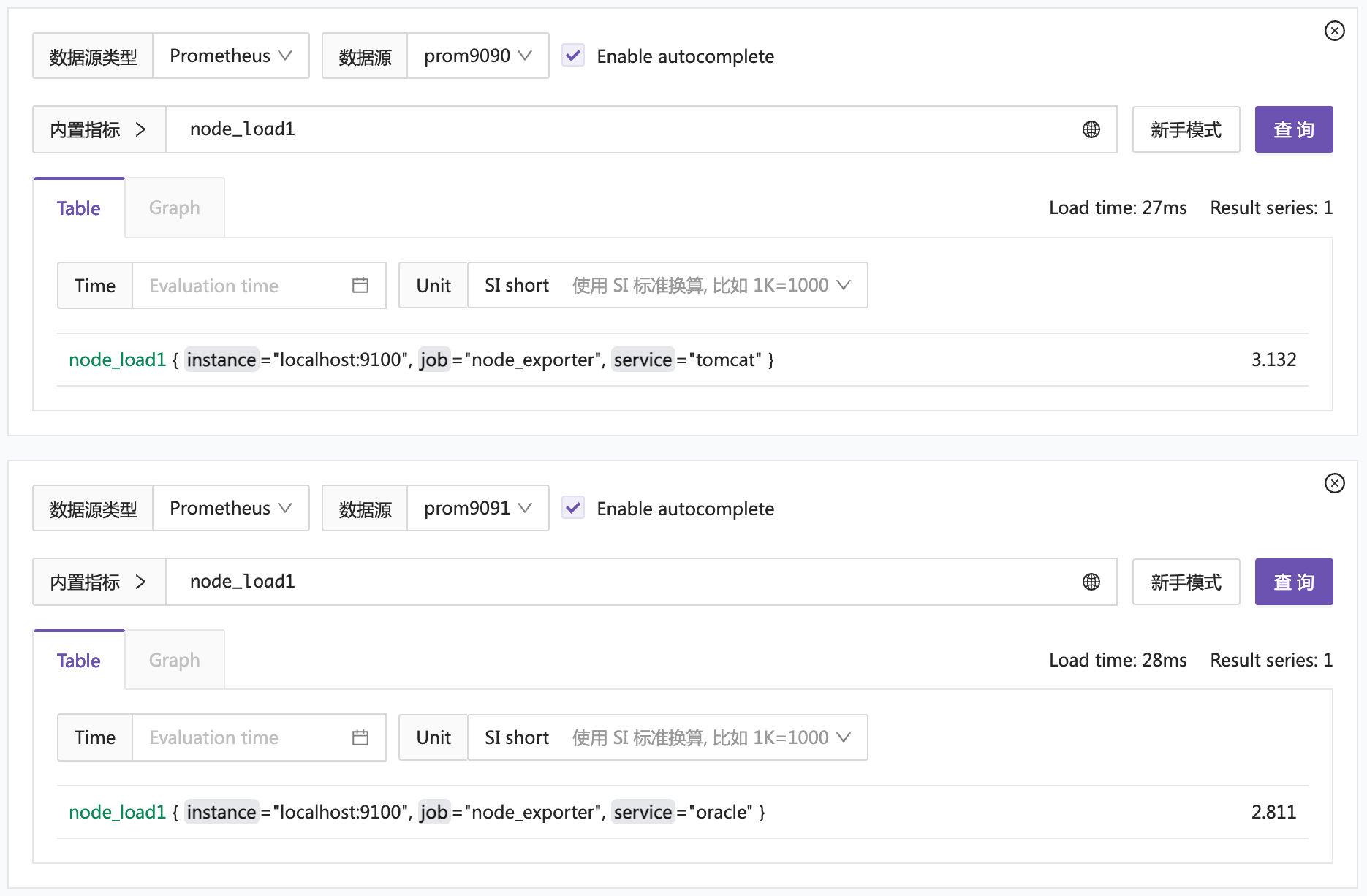
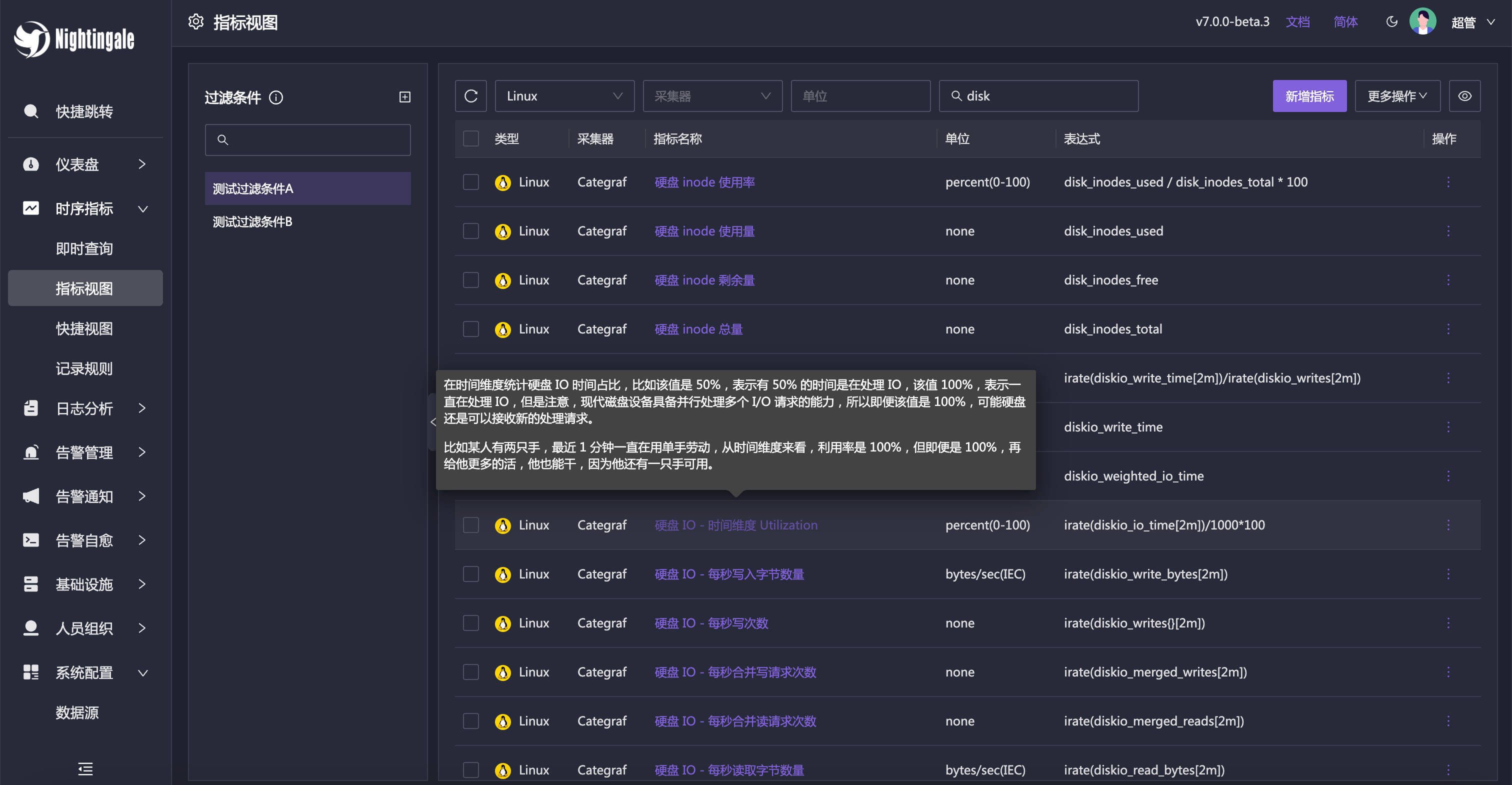
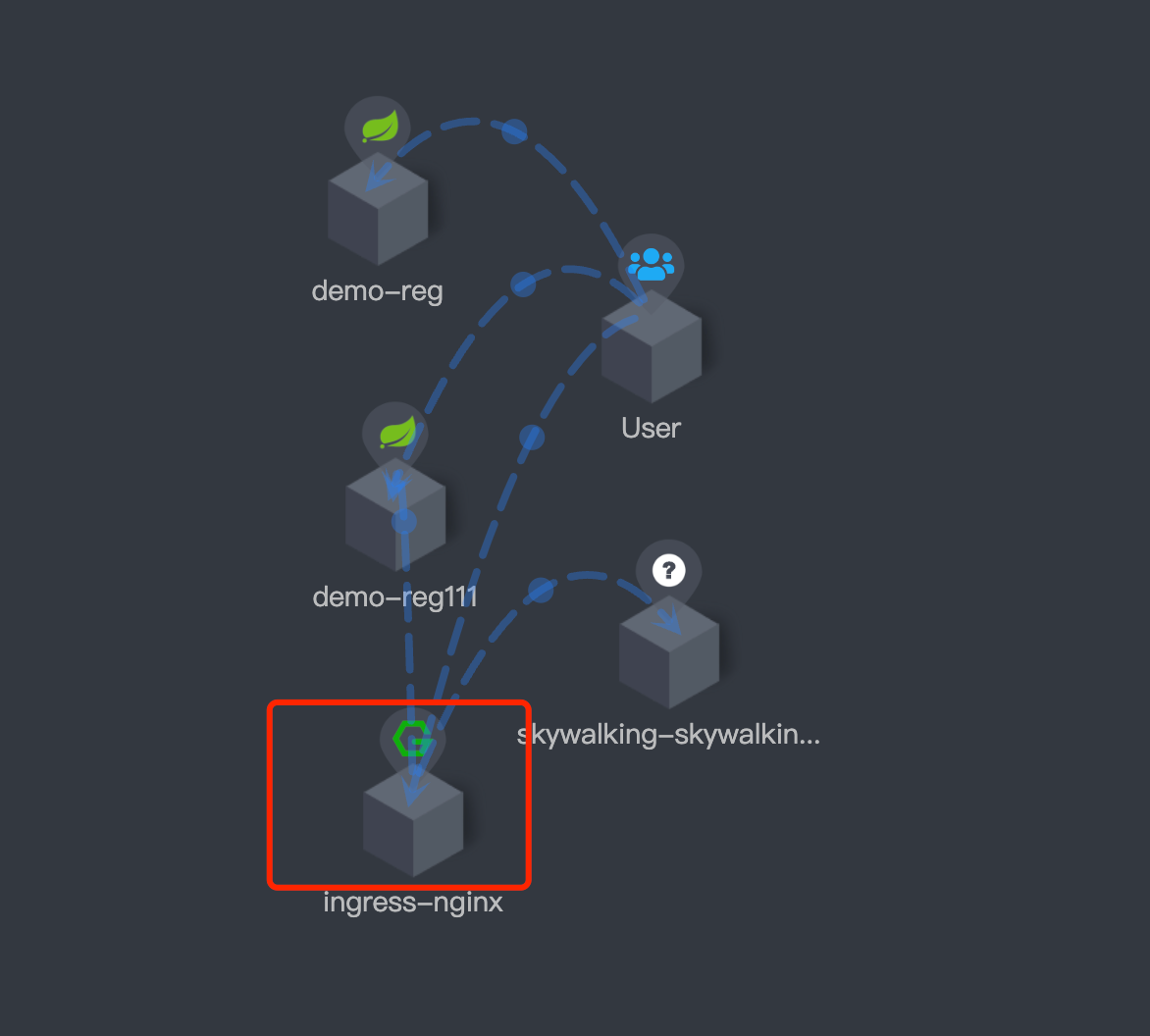
Posted by crossoverJie on 2024-06-05 08:08:08
Posted by 巴辉特 on 2024-06-03 00:08:08
Posted by 巴辉特 on 2024-05-29 00:00:01
Posted by 快猫技术 on 2024-05-27 10:00:00
Posted by 夜莺 on 2024-05-24 14:00:00
Posted by 巴辉特 on 2024-05-24 00:00:01
Posted by 巴辉特 on 2024-05-22 00:08:08
Posted by 巴辉特 on 2024-05-20 00:08:08
Posted by 巴辉特 on 2024-05-11 00:06:10
Posted by 巴辉特 on 2024-05-10 00:06:10
Posted by 巴辉特 on 2024-05-09 00:06:10
Posted by VicLai on 2024-05-07 08:08:08
Posted by 巴辉特 on 2024-05-07 00:06:10
Posted by 胡冲-快猫星云 on 2024-04-29 00:08:08
Posted by 巴辉特 on 2024-04-24 00:08:08
Posted by 巴辉特 on 2024-04-23 00:08:08
Posted by Product Team @快猫星云 on 2024-04-22 10:00:00
Posted by 译文 on 2024-04-19 00:08:08
Posted by 张根 on 2024-04-16 00:08:08