ES日志监控(专业版)
日志分析-即时查询
在选择关联数据源后,可能你第一个遇到的疑问是关于 “index patterns” 和 “indices” 的异同。下面是这两者的简要解释:
-
Index Patterns(索引模式)是用于匹配单个条件的索引模式规则;而 Indices(索引)是用于匹配多个条件并集的索引。

-
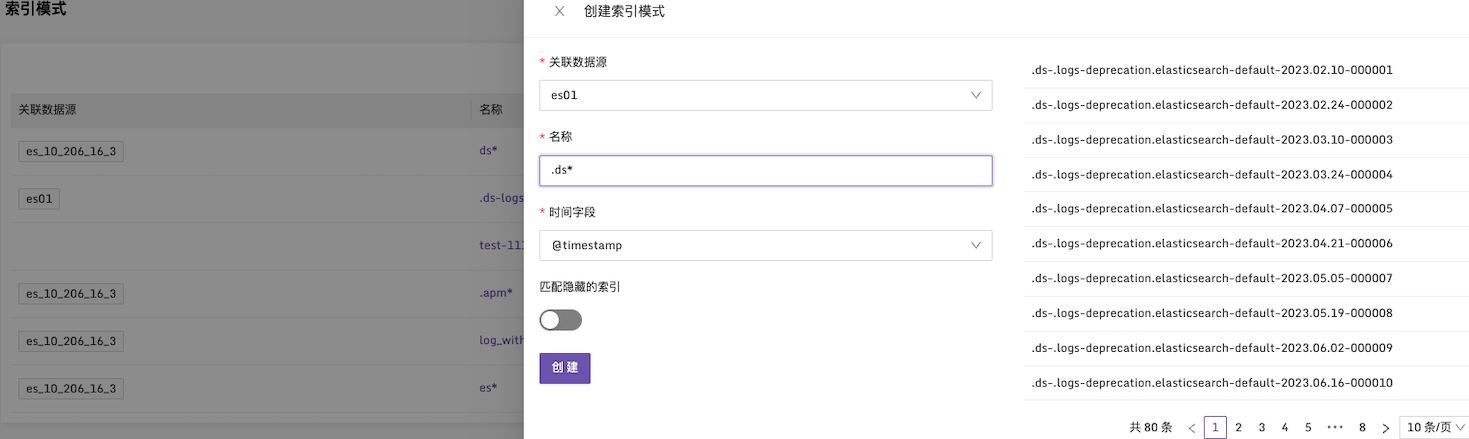
在使用 Index Patterns 时,需要提前在索引模式列表中进行配置,以指定索引的内容和日期字段;而在使用 Indices 时,可以根据需要直接输入索引的内容。
-
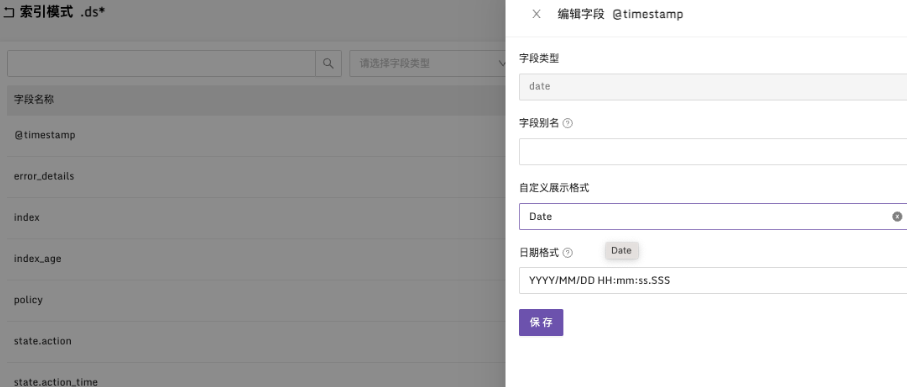
Index Patterns 的索引模式还可以设置字段别名,对时间类型设置自定义格式。
-
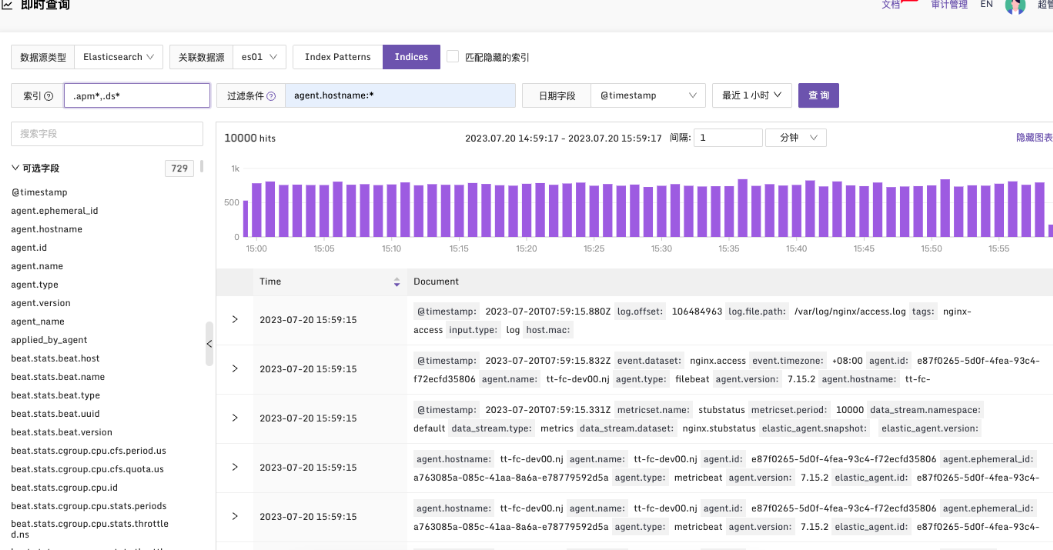
Indices 输入索引的内容支持多种配置方式,以下是一些有效的语法示例:
- 指定单个索引进行完整匹配:例如,gb 将在 gb 索引中搜索所有文档。
- 指定多个表达式并用逗号分隔:例如,gb,us 将在 gb 和 us 索引中搜索所有文档。
- 使用索引前缀和通配符进行模糊匹配:例如,g*,u* 将在以 g 或 u 开头的所有索引中搜索。
查询条件中的过滤条件语法,可以使用 Elasticsearch 的 Query DSL 中的查询语法,支持字段值(field names)、通配符、正则表达式、模糊匹配等。具体语法细节可以参考 Elasticsearch 的 API 文档。
告警管理-告警规则
夜莺专业版提供了 ES日志告警的能力,如果你们有针对日志告警的需求,欢迎联系我们,沟通试用。
在告警规则配置中,日志类型和常规的指标告警规则非常相似,其唯一的区别在于告警条件的设置。指标告警规则使用 PromQL 作为查询条件,而日志类型的告警规则则使用布尔表达式作为查询条件。这些告警条件(如 A、B 等)需要通过查询统计来获取。
在配置查询统计时,会发现它和ES日志即时查询类似,但还有两个额外的数据字段组:数值提取和 Group By。
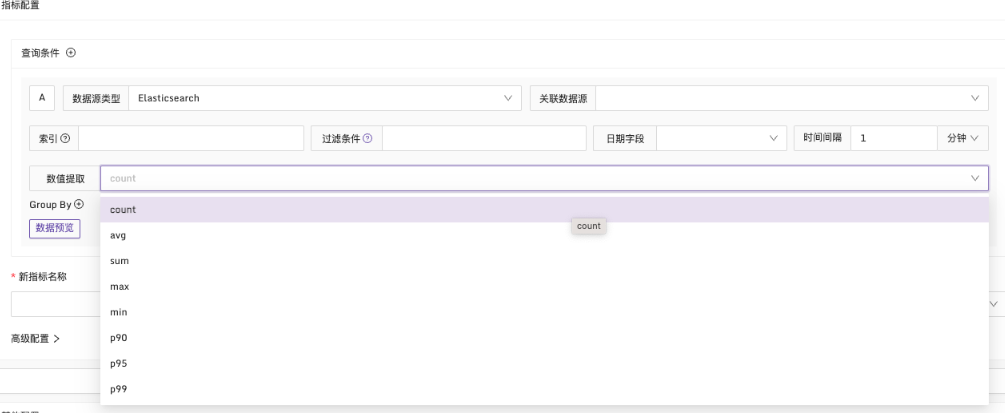
为了获得数值类型的结果,需要使用数值提取,选择适当的统计函数。除了常见的 count、sum、avg、min、max 等函数外,还支持一些百分位值函数,如 p90、p95、p99。
此外,通过配置 Group By,可以根据特定字段对结果进行分组。这将生成多个时间序列,并在满足告警条件的情况下产生多个异常点,从而生成多条告警事件。
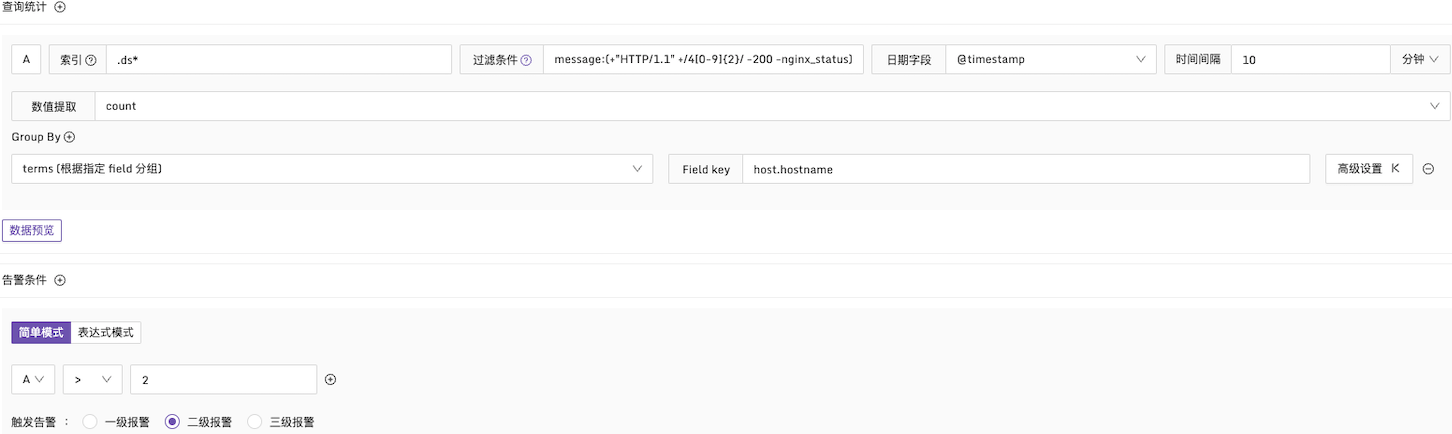
例子1:HTTP CODE 为4xx的告警条件
说明:在每10分钟的时间段内,检查日志中的 message 字段。如果4xx的日志数量超过2次,产生告警,并且按照 host.hostname 字段进行分组统计,配置方式如下
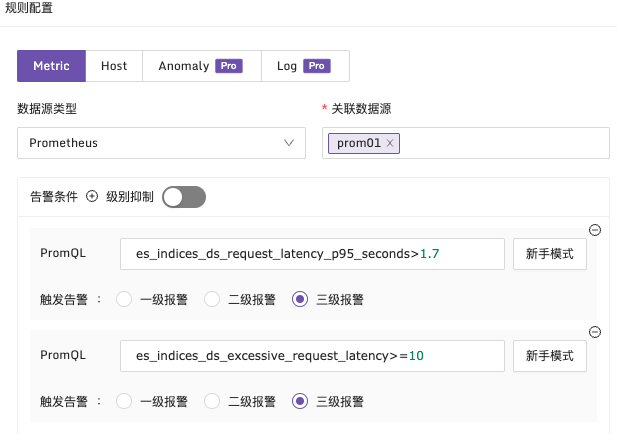
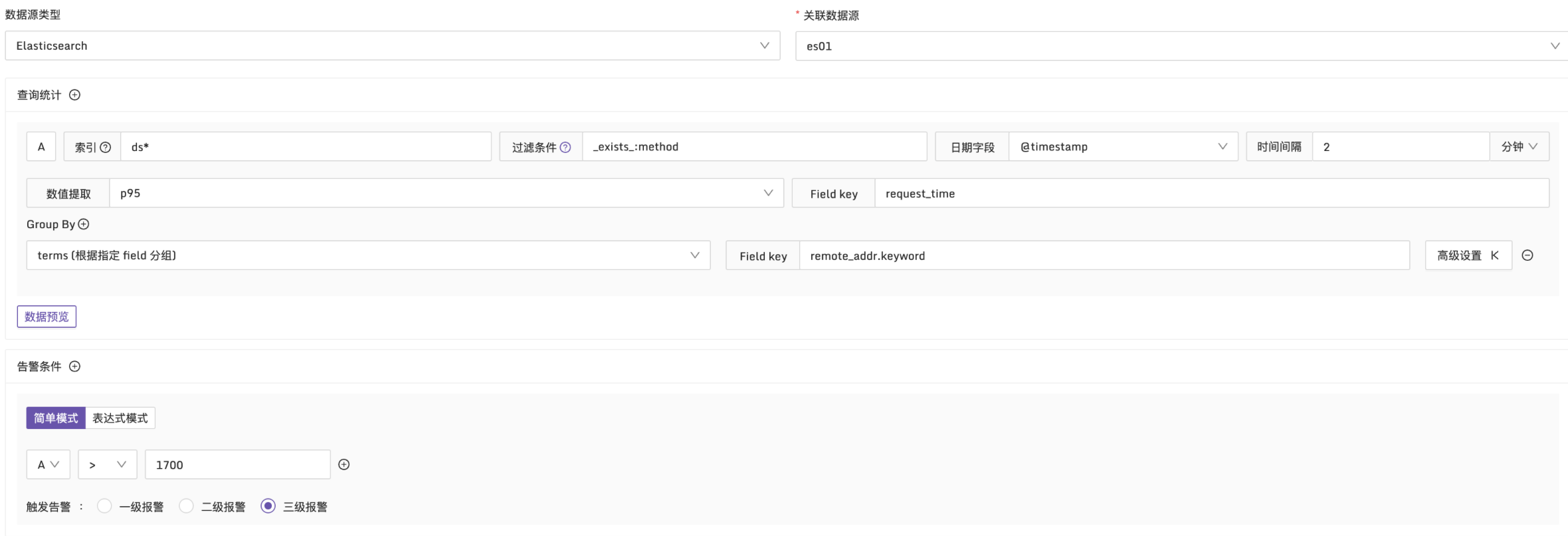
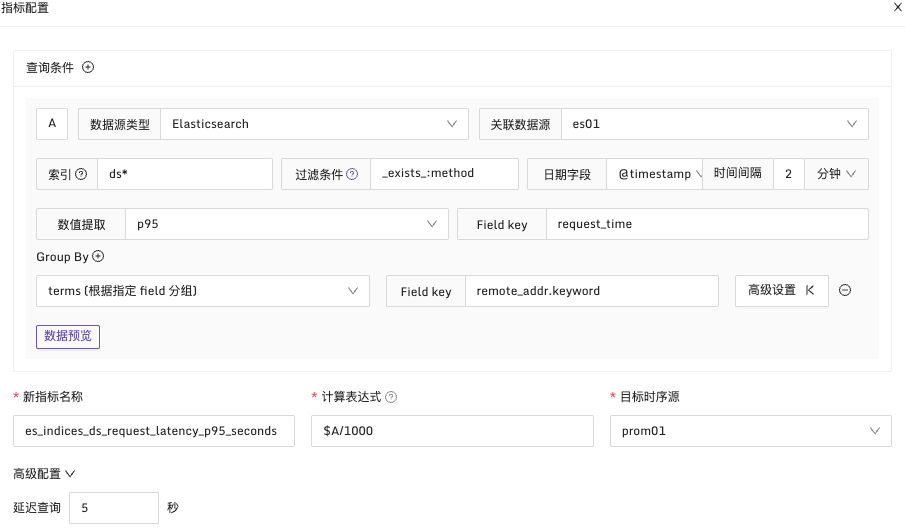
例子2:接口的请求耗时95分位值超过 1700ms 时触发告警
说明:在每2分钟的时间段内,使用p95函数统计日志中的 request_time 。按 remote_addr 维度进行分组,检查是否有超过1700ms 的请求耗时,配置方式如下
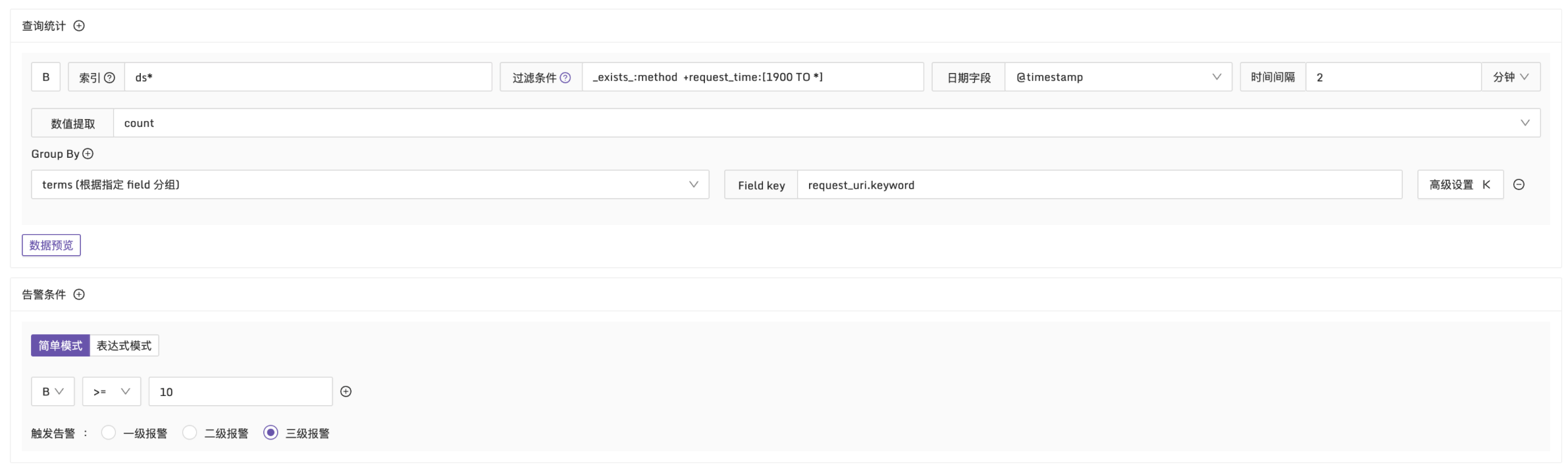
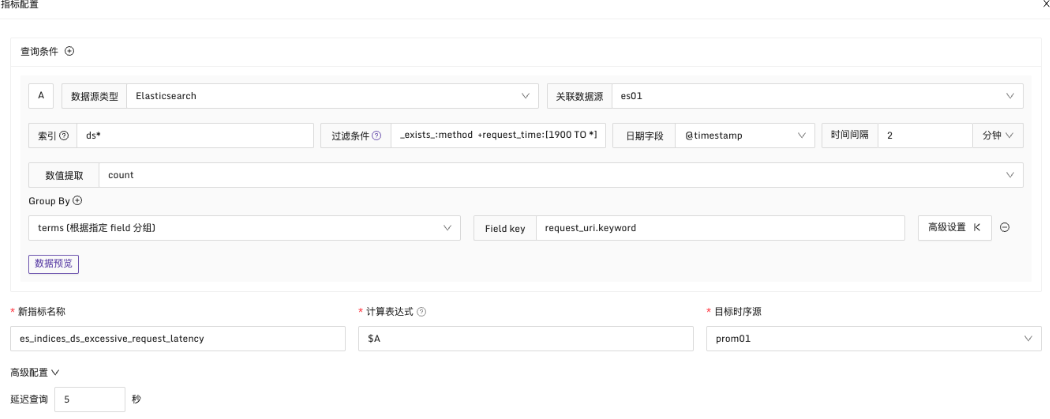
例子3:request_time 大于1900ms,匹配日志超过10条时触发告警
说明:在每2分钟的时间段内,筛选出 request_time 大于1900ms 的日志。按 request_uri 维度进行分组,检查日志数量是否超过10条,配置方式如下
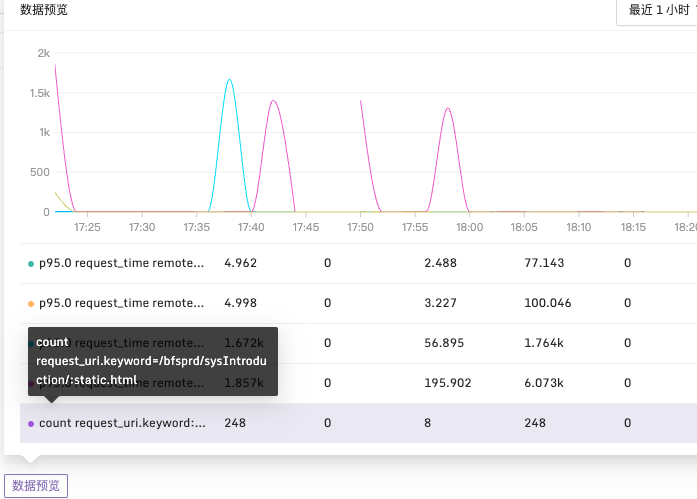
在配置完成所需的数据字段后,还可以通过数据预览按钮来预览查询结果。
时序指标-记录规则
记录规则也是支持数据源为 ES 类型,它的字段组和告警规则一样,通过记录规则的配置可以减少重复的查询。把需要耗费大量资源/时间计算的查询结果重新定义为新的指标值,其他用到相同查询的地方就可以直接使用新指标值。
举个例子,改造告警规则例子2,3中的两个告警条件,重新定义为两个新的指标。
当再配置告警规则条件时,就可以改用指标类型告警,通过 PromQL 作为告警条件。