Mtail 日志采集插件
mtail插件
简介
mtail 是谷歌开源的一款从应用日志中提取 metrics 的工具。categraf 将 mtail 作为一个插件集成了进来,并且兼容 mtail 的语法,简化了部署。原本 mtail 和日志文件之间是一对一的关系,即一般都是一个 mtail 进程处理一类日志,但是对于很高配的物理机,上面会部署很多不同的服务,每个服务进程都对应一个 mtail,此时机器上会出现特别多的 mtail 进程,较难维护。把 mtail 集成到 categraf 之后,复用 categraf 的多实例插件机制,可以做到一台机器上只有一个 categraf 进程即可读取解析多个服务的日志。
示例图如下: 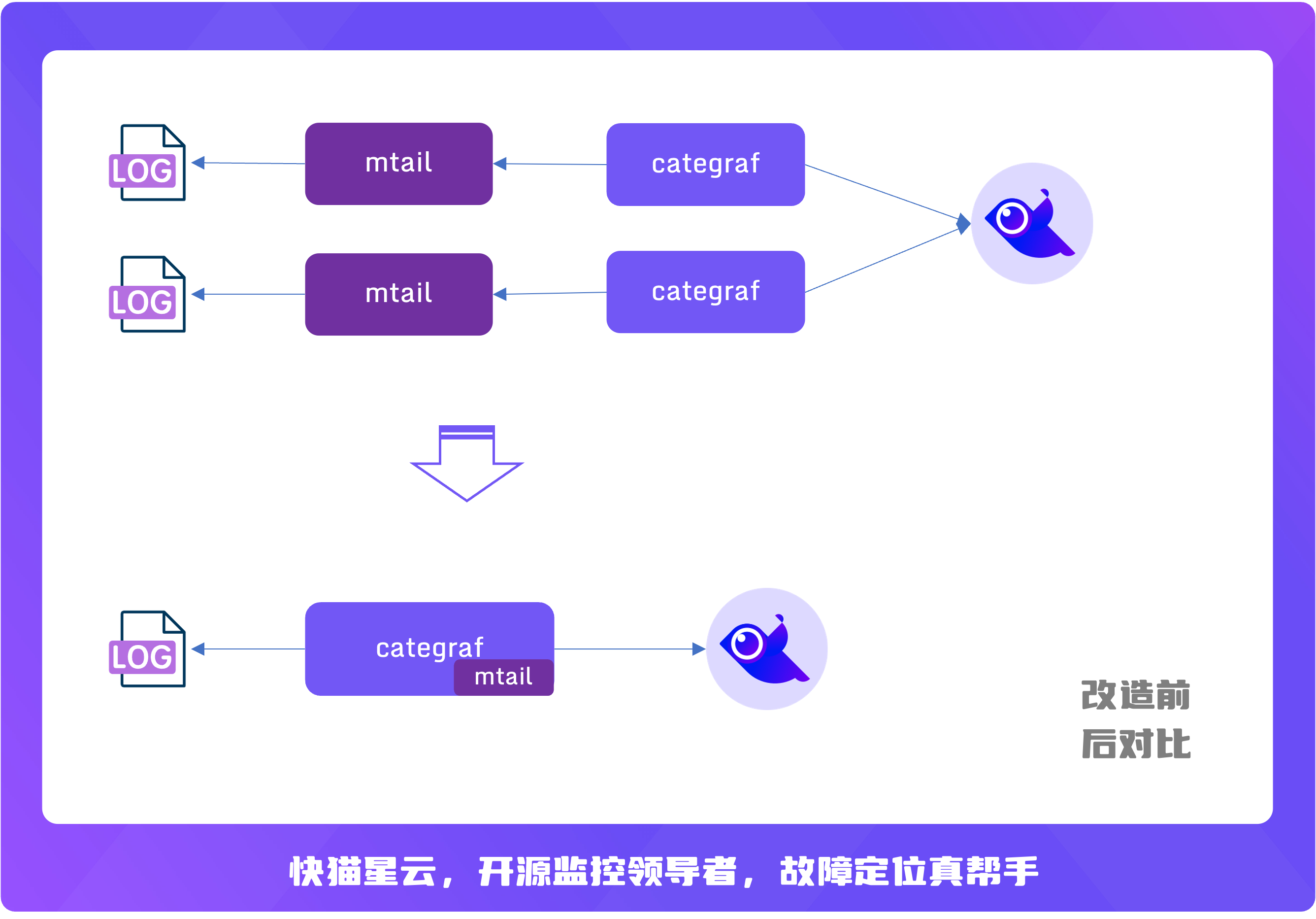
- 功能: 提取日志内容,转换为监控 metrics
- 输入: 日志
- 输出: metrics 按照 mtail 语法输出, 仅支持 counter、gauge、histogram
- 处理: 本质是 golang 的正则提取+表达式计算
启动
编辑 mtail.toml 文件, 一般每个 instance 需要指定不同的 progs 参数(不同的 progs 文件或者目录),否则指标会相互干扰。
注意: 如果不同 instanc 使用相同 progs, 可以通过给每个 instance 增加 labels 做区分,
labels = { k1=v1 }
或
[instances.labels]
k1=v1
配置说明
conf/inputs.mtail/mtail.toml中指定 instance
[[instances]]
## 指定mtail prog的目录
progs = "/path/to/prog1"
## 指定mtail要读取的日志
logs = ["/path/to/a.log", "path/to/b.log"]
## 指定时区
# override_timezone = "Asia/Shanghai"
## metrics是否带时间戳,注意,这里是"true"
# emit_metric_timestamp = "true"
...
注意:
- logs参数指定要处理的日志源, 支持模糊匹配, 支持多个 log 文件。
progs指定具体的规则文件目录(或文件)
- 在/path/to/prog1 目录下编写规则文件
gauge xxx_errors
/ERROR.*/ {
xxx_errros++
}
- 在一个终端中执行
categraf --test --inputs mtail,用于测试 - 另一个终端中,向"/path/to/a.log" 或者 “path/to/b.log” 追加一行 ERROR,看看 categraf 的输出
- 测试通过后,启动 categraf
处理规则与语法
处理流程
for line in lines:
for regex in regexes:
if match:
do something
语法
exported variable
pattern {
action statements
}
def decorator {
pattern and action statements
}
定义指标名称
前面也提过,指标仅支持 counter gauge histogram 三种类型。 一个示例🌰
counter lines
/INFO.*/ {
lines++
}
注意,定义的名称只支持 C 语言类型的命名方式(字母/数字/下划线),如果想使用"-" 要使用"as"导出别名。例如,
counter lines_total as "line-count"
这样获取到的就是 line-count 这个指标名称了
匹配与计算(pattern/action)
PATTERN {
ACTION
}
例子
/foo/ {
ACTION1
}
variable > 0 {
ACTION2
}
/foo/ && variable > 0 {
ACTION3
}
支持RE2正则匹配
const PREFIX /^\w+\W+\d+ /
PREFIX {
ACTION1
}
PREFIX + /foo/ {
ACTION2
}
这样,ACTION1 是匹配以小写字符+大写字符+数字+空格的行,ACTION2 是匹配小写字符+大写字符+数字+空格+foo开头的行。
关系运算符
<小于<=小于等于>大于>=大于等于==相等!=不等=~匹配(模糊)!~不匹配(模糊)||逻辑或&&逻辑与!逻辑非
数学运算符
|按位或&按位与^按位异或+ - * /四则运算<<按位左移>>按位右移**指数运算=赋值++自增运算--自减运算+=加且赋值
支持 else 与 otherwise
/foo/ {
ACTION1
} else {
ACTION2
}
支持嵌套
/foo/ {
/foo1/ {
ACTION1
}
/foo2/ {
ACTION2
}
otherwise {
ACTION3
}
}
支持命名与非命名提取
/(?P<operation>\S+) (\S+) \[\S+\] (\S+) \(\S*\) \S+ (?P<bytes>\d+)/ {
bytes_total[$operation][$3] += $bytes
}
增加常量label
# test.mtail
# 定义常量label env
hidden text env
# 给label 赋值 这样定义是global范围;
# 局部添加,则在对应的condition中添加
env="production"
counter line_total by logfile,env
/^(?P<date>\w+\s+\d+\s+\d+:\d+:\d+)/ {
line_total[getfilename()][env]++
}
获取到的metrics中会添加上env=production的label 如下:
# metrics
line_total{env="production",logfile="/path/to/xxxx.log",prog="test.mtail"} 4 1661165941788
如果要给metrics增加变量label,必须要使用命名提取。例如
# 日志内容
192.168.0.1 GET /foo
192.168.0.2 GET /bar
192.168.0.1 POST /bar
# test.mtail
counter my_http_requests_total by log_file, verb
/^/ +
/(?P<host>[0-9A-Za-z\.:-]+) / +
/(?P<verb>[A-Z]+) / +
/(?P<URI>\S+).*/ +
/$/ {
my_http_requests_total[getfilename()][$verb]++
}
# metrics
my_http_requests_total{logfile="xxx.log",verb="GET",prog="test.mtail"} 4242
my_http_requests_total{logfile="xxx.log",verb="POST",prog="test.mtail"} 42
命名提取的变量可以在条件中使用
/(?P<x>\d+)/ && $x > 1 {
nonzero_positives++
}
时间处理
不显示处理,则默认使用系统时间
默认 emit_metric_timestamp="false" (注意是字符串)
http_latency_bucket{prog="histo.mtail",le="1"} 0
http_latency_bucket{prog="histo.mtail",le="2"} 0
http_latency_bucket{prog="histo.mtail",le="4"} 0
http_latency_bucket{prog="histo.mtail",le="8"} 0
http_latency_bucket{prog="histo.mtail",le="+Inf"} 0
http_latency_sum{prog="histo.mtail"} 0
http_latency_count{prog="histo.mtail"} 0
参数 emit_metric_timestamp="true" (注意是字符串)
http_latency_bucket{prog="histo.mtail",le="1"} 1 1661152917471
http_latency_bucket{prog="histo.mtail",le="2"} 2 1661152917471
http_latency_bucket{prog="histo.mtail",le="4"} 2 1661152917471
http_latency_bucket{prog="histo.mtail",le="8"} 2 1661152917471
http_latency_bucket{prog="histo.mtail",le="+Inf"} 2 1661152917471
http_latency_sum{prog="histo.mtail"} 3 1661152917471
http_latency_count{prog="histo.mtail"} 4 1661152917471
使用日志的时间
Aug 22 15:28:32 GET /api/v1/pods latency=2s code=200
Aug 22 15:28:32 GET /api/v1/pods latency=1s code=200
Aug 22 15:28:32 GET /api/v1/pods latency=0s code=200
histogram http_latency buckets 1, 2, 4, 8
/^(?P<date>\w+\s+\d+\s+\d+:\d+:\d+)/ {
strptime($date, "Jan 02 15:04:05")
/latency=(?P<latency>\d+)/ {
http_latency=$latency
}
}
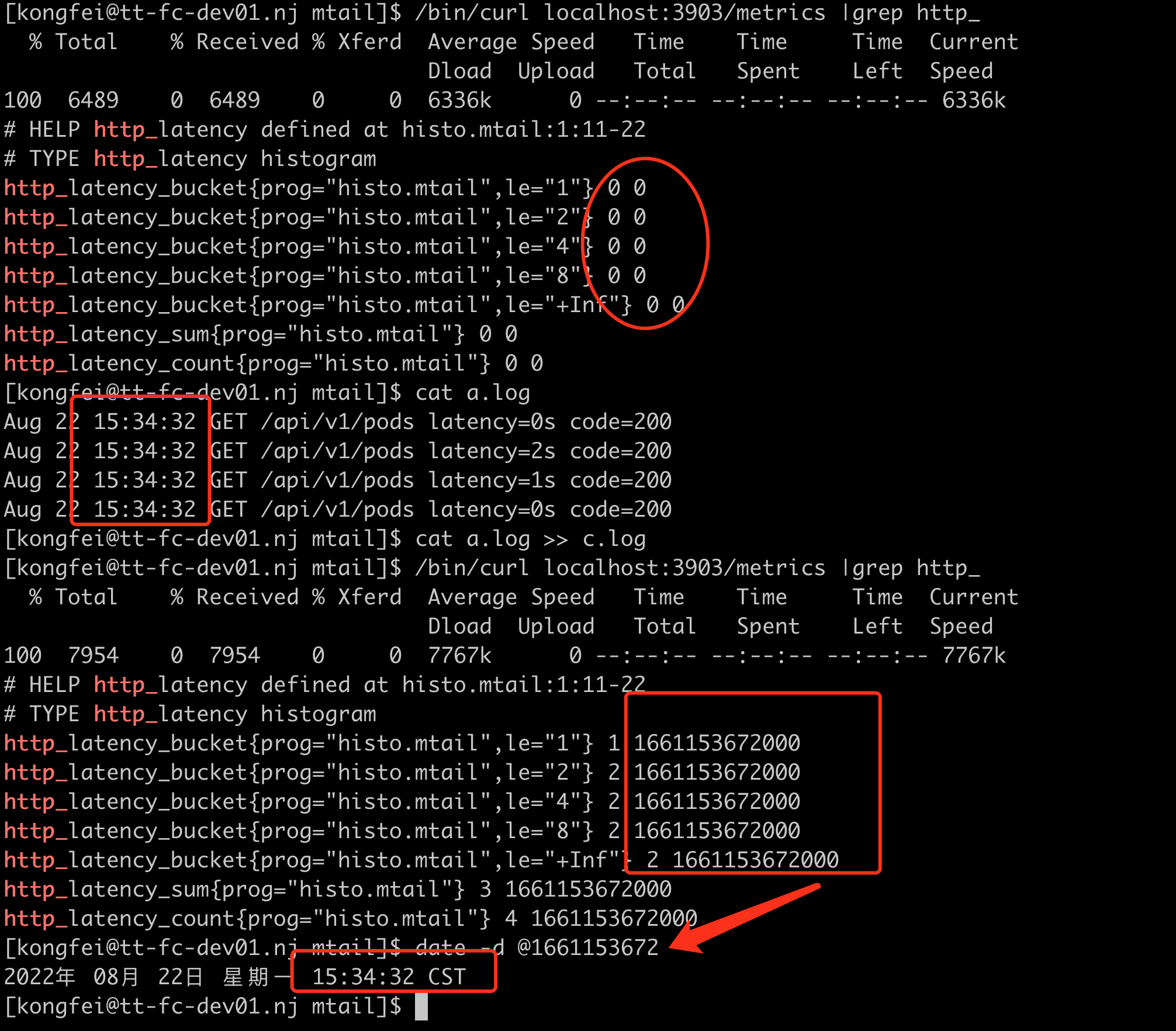
日志提取的时间,一定要注意时区问题,有一个参数 override_timezone 可以控制时区选择,否则默认使用UTC转换。
比如我启动时指定 override_timezone=Asia/Shanghai, 这个时候日志提取的时间会当做东八区时间转换为 timestamp, 然后再从 timestamp 转换为各时区时间时,就没有问题了,如图。
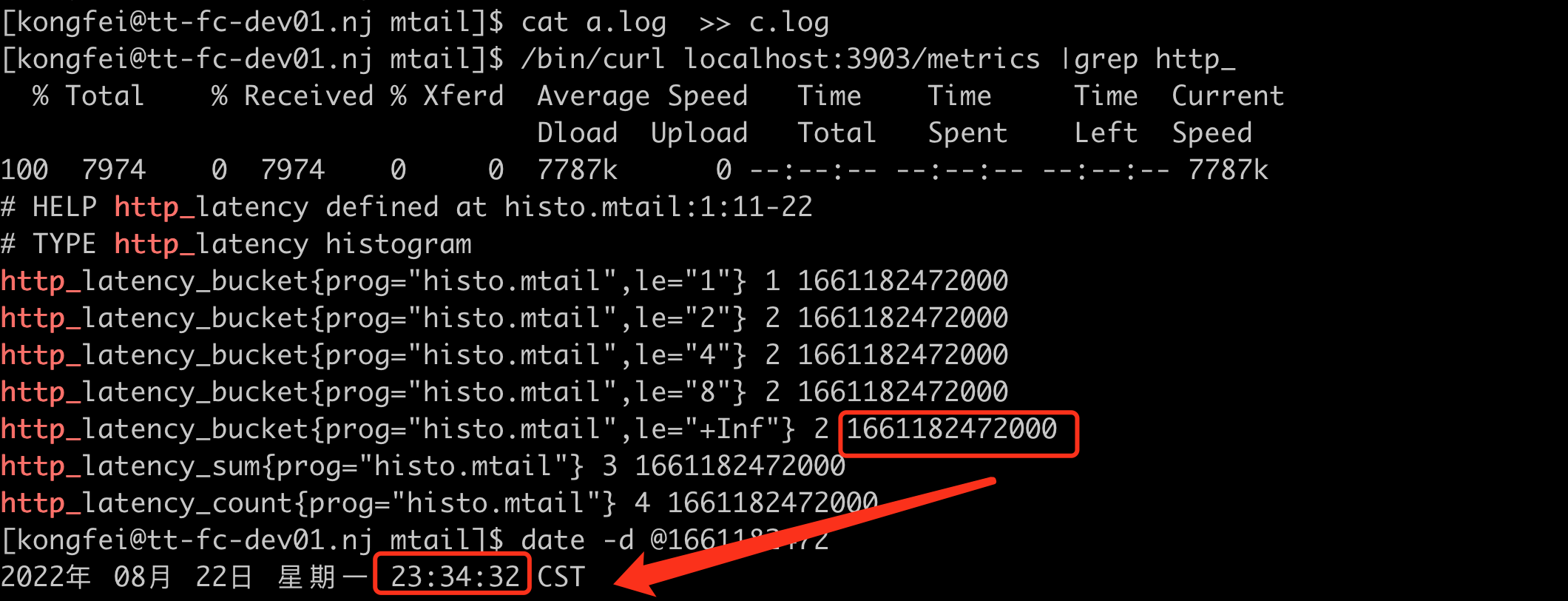
如果不带 override_timezone=Asia/Shanghai, 则默认将Aug 22 15:34:32 当做UTC时间,转换为timestamp。 这样再转换为本地时间时,会多了8个小时, 如图。
远程下发
企业版v0.3.34, 开源版v0.3.62 支持远程书写规则文件(不会落盘)
[[instances]]
#progs = "/home/flashcat/mtail/prog" # prog dir1
logs = ["/home/flashcat/mtail/logs/*/b.log"]
labels = { log="b.log" }
# override_timezone = "Asia/Shanghai"
# emit_metric_timestamp = "true" #string type
[instances.prog_content]
"b.mtail"='''
const KEY /.*ip\s(?P<ip>.*?)\s(?P<tp>.*)cnt\s(?P<val>\d+).*/
gauge log_ctp_front_out_cnt by ip,tp
KEY {
log_ctp_front_out_cnt[$ip][$tp]=$val
}
'''
下发配置说明
使用场景举例:计算/var/log/messages中关键词demo的次数
/var/log/messages 日志格式如下
[root@demo-01 ~]# tail -n 10 /var/log/messages
Aug 5 11:39:36 demo-01 crond[1212]: Local delivery not possible without a MDA
Aug 5 11:39:36 demo-01 crond[1212]: Local delivery not possible without a MDA
Aug 5 11:39:36 demo-01 crond[1212]: Local delivery not possible without a MDA
新增下发采集配置:
在数据接入—数据采集—选择指定业务组—右上角新增采集规则。
下发采集配置说明:
通过下面采集配置可以实现采集/var/log/messages中关键词demo的次数。
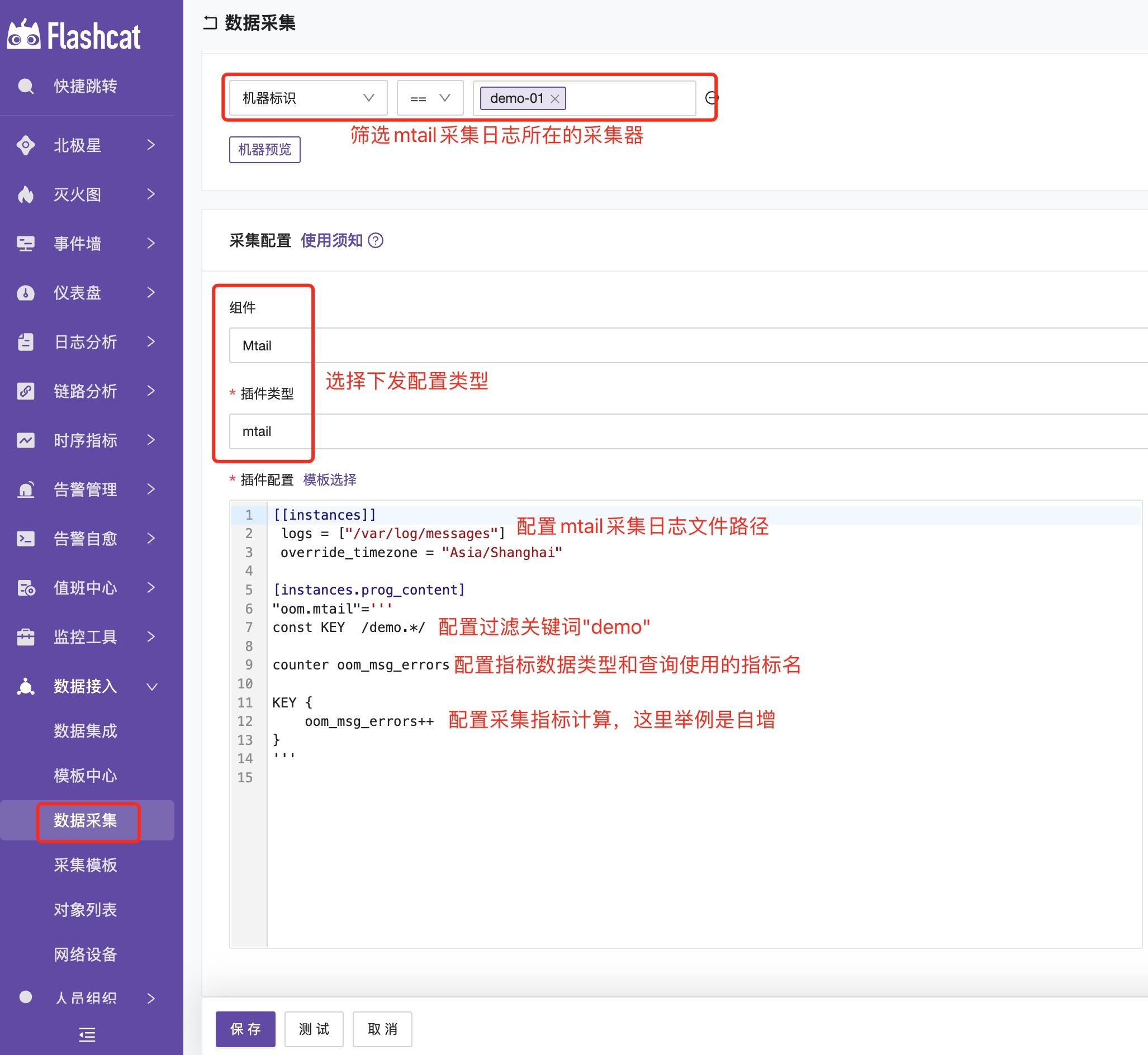
下面是采集参数的详细说明,请仔细阅读。
logs
匹配被采集的文件或者路径,常用匹配规则如下,可以根据需求进行选择。
绝对匹配:../b.log
路径模糊匹配:../*/b.log
文件模糊匹配:../*.log
匹配规则
[instances.prog_content]
"oom.mtail"='''
const KEY /demo.*/
counter oom_msg_errors
KEY {
oom_msg_errors++
}
const KEY: 过滤日志条件的常量标识符,参数后面跟过滤日志正则条件。
/demo.*/: 过滤日志的正则条件,这里举例正则:过滤日志中包含demo的日志。
gauge: 指标类型,目前支持 counter gauge histogram 三种类型。
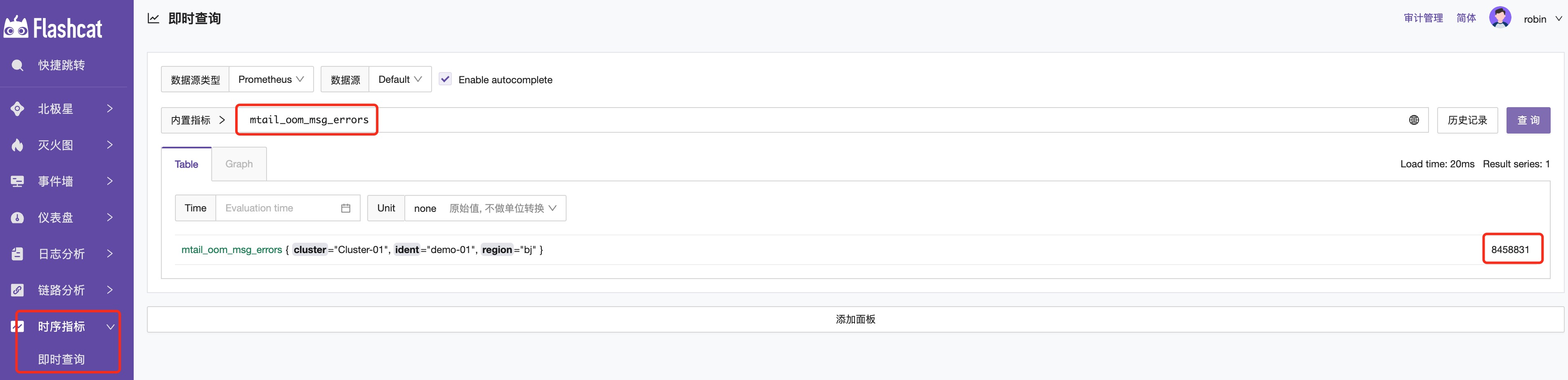
oom_msg_errors:定义的指标名称,根据需求自定义即可,如下图所示在即时查询使用的查询指标名称。

oom_msg_errors++:指标提取方式,这里举例是累加。
采集指标查询
在配置完成后,可以在即时查询输入mtail+指定指标名称进行结果查询。