

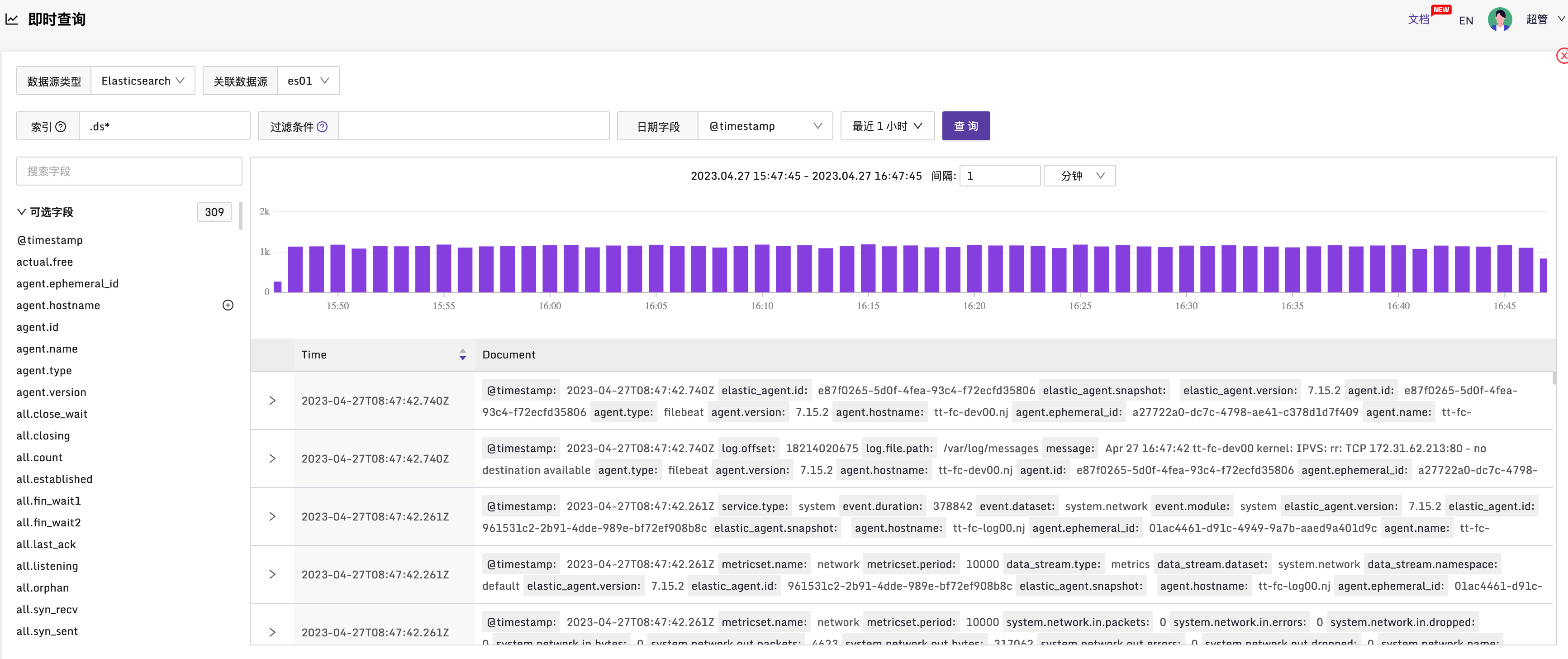
即时查询
ES 数据源
夜莺从 v6 版本支持了对接 elasticsearch 类型的数据源,在数据源管理配置好 es 数据源之后,就可以在即时查询页面查询 es 的数据了,目前过滤条件支持 query string 的查询语法,具体的语法可以到 es 官网 查看
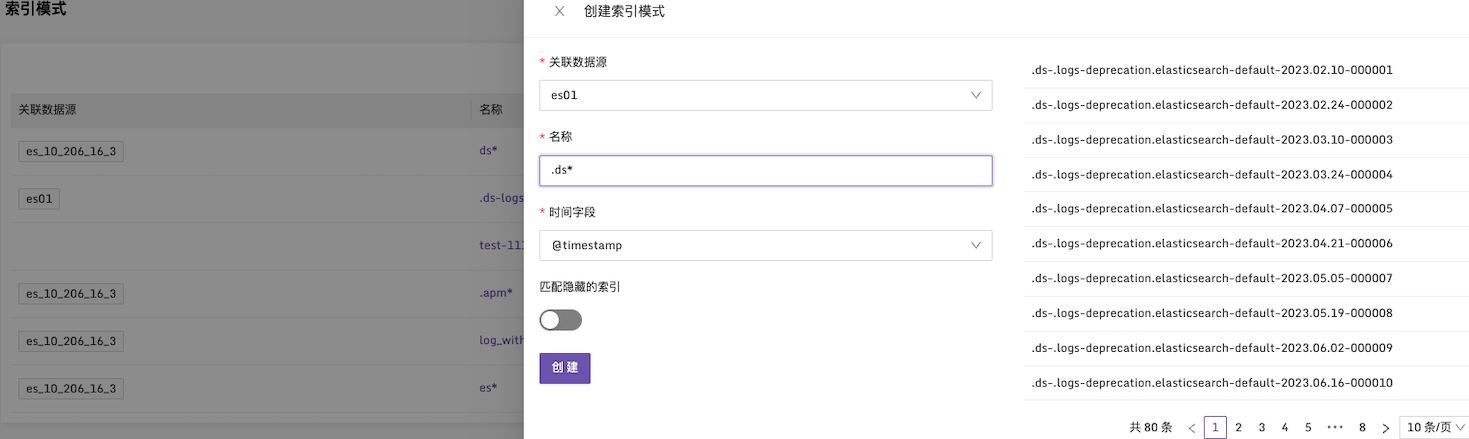
在选择关联数据源后,可能你第一个遇到的疑问是关于 “index patterns” 和 “indices” 的异同。下面是这两者的简要解释:
Index Patterns(索引模式)
-
Index Patterns(索引模式)是用于匹配单个条件的索引模式规则;而 Indices(索引)是用于匹配多个条件并集的索引。

-
在使用 Index Patterns 时,需要提前在索引模式列表中进行配置,以指定索引的内容和日期字段;而在使用 Indices 时,可以根据需要直接输入索引的内容。
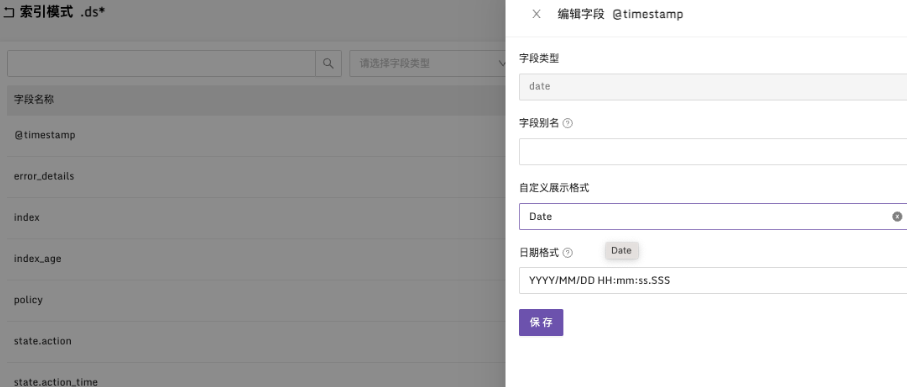
-
Index Patterns 的索引模式还可以设置字段别名,对时间类型设置自定义格式。
Indices
Indices 输入索引的内容支持多种配置方式,以下是一些有效的语法示例:
- 指定单个索引进行完整匹配:例如,gb 将在 gb 索引中搜索所有文档。
- 指定多个表达式并用逗号分隔:例如,gb,us 将在 gb 和 us 索引中搜索所有文档。
- 使用索引前缀和通配符进行模糊匹配:例如,g*,u* 将在以 g 或 u 开头的所有索引中搜索。
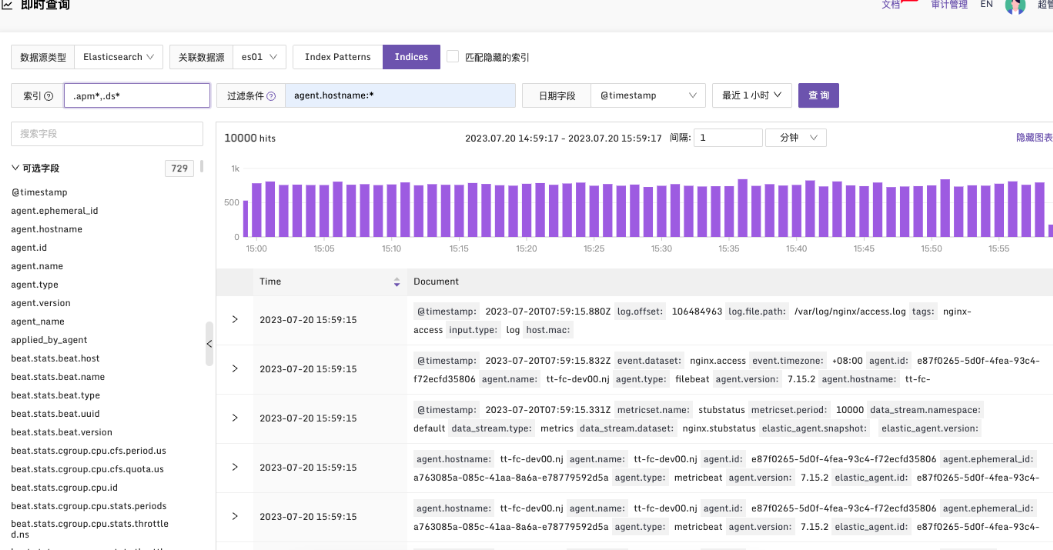
查询条件中的过滤条件语法,可以使用 Elasticsearch 的 Query DSL 中的查询语法,支持字段值(field names)、通配符、正则表达式、模糊匹配等。具体语法细节可以参考 Elasticsearch 的 API 文档。
阿里云 SLS 数据源
在关联数据源后查看 SLS 日志原文的第一步是分别选择项目(资源管理单元)和日志库(日志数据查询单元)。
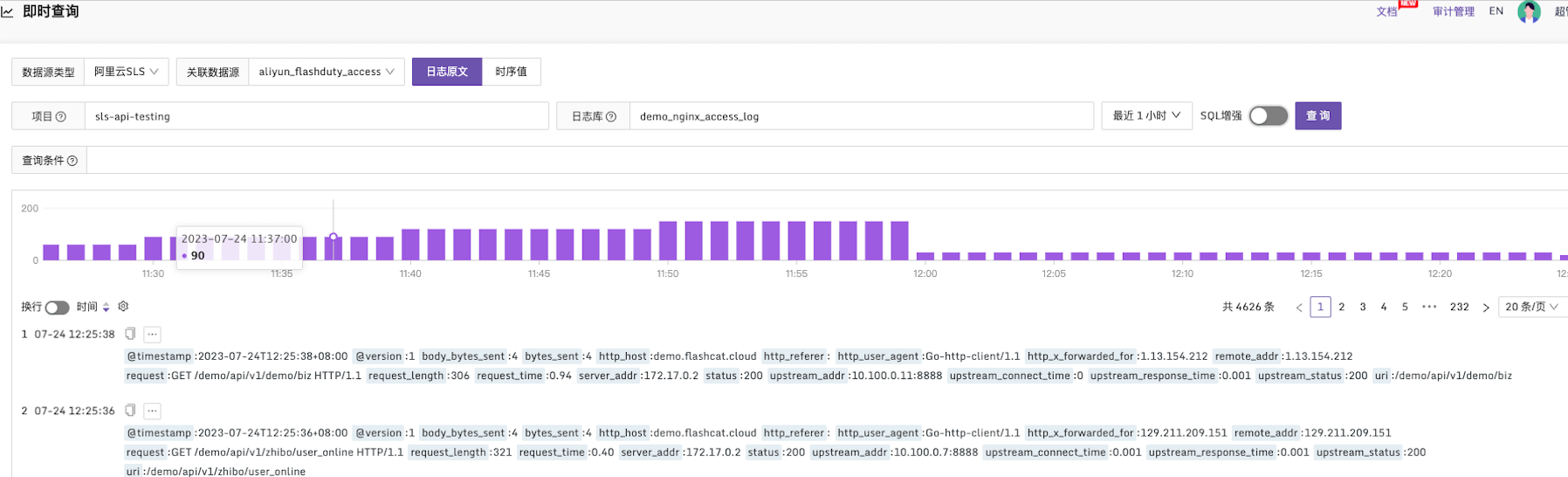
为了更准确地查询日志,您可以使用查询条件来进行精确的查询。查询条件的语法规则由查询语句和分析语句两部分组成,它们之间以竖线(|)分割。
查询语句类似于常规的日志查询方式,支持运算符,通配符等。
而分析语句是将查询语句的结果进行进一步分析查询,其语义十分灵活,支持 SQL 语法和多种 SQL 函数等,具体参见阿里云文档。
SQL 增强选项是指是否使用 SQL 独享版( SLS 的计费资源,增强分析语句查询资源使用情况),详见阿里云 API 文档–power_sql。
除了查看日志原文的方式,还可以选择切换到时序值选项,将日志指标的时序值绘制成图表。通过配置辅助配置里的 ValueKey 和 LabelKey,可以将查询结果绘制成图表(大多数情况下,只需要这两个配置参数即可)。下图所示是一个查询条件的例子: not status:200 and http_user_agent:Go* | SELECT count(*) AS PV, date_trunc('hour', __time__) AS timeHour,uri group by timeHour,uri ,该查询条件绘制了按 uri 和 timeHour 来分组的PV指标曲线图。
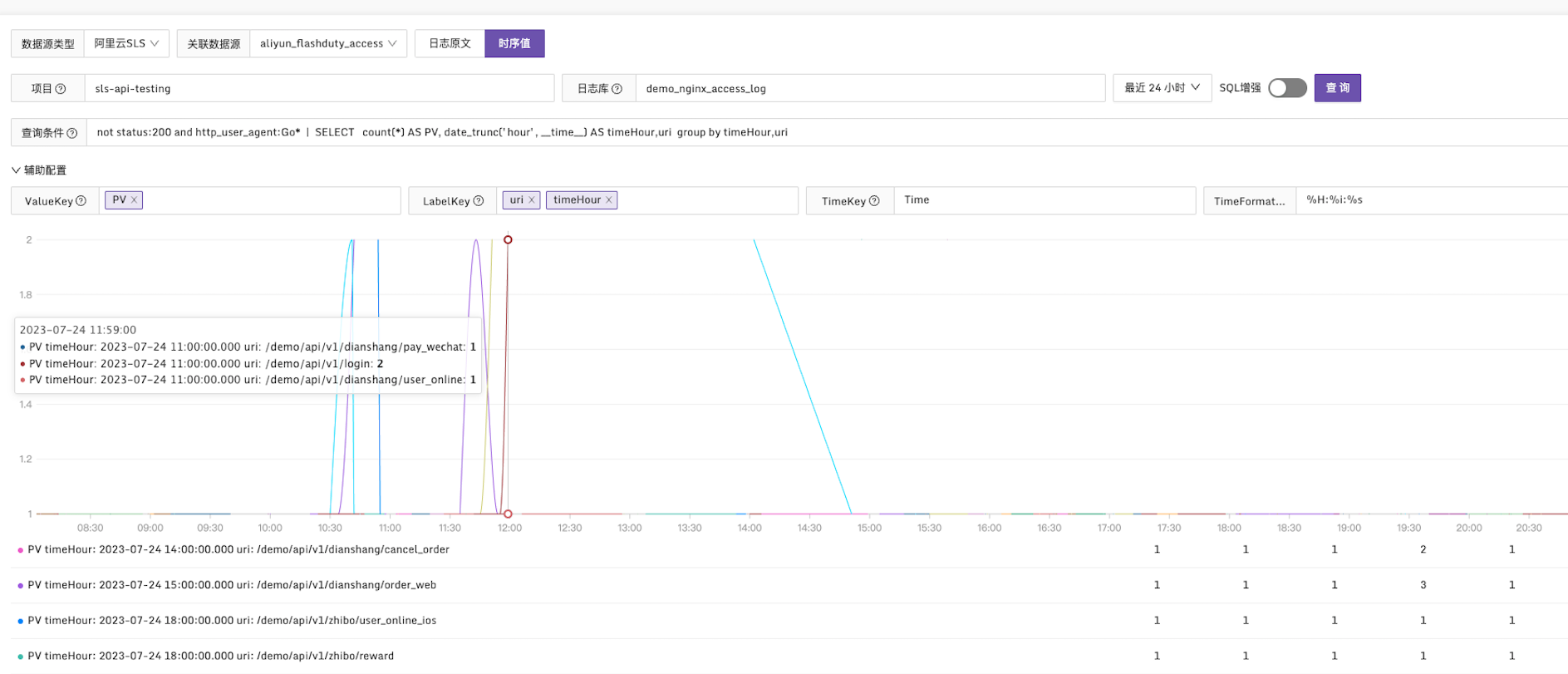
请注意一下几点:
- ValueKey 必须是数值类型,用于描述指标值,相关统计结果会显示在图表右下方。如果不是数值类型,则无法正确绘制图表。当分析语句只有一个指标值时会自动提取,如果存在多个指标值时需要明确指明使用哪个指标值,即需要主动设置 ValueKey。
- 当查询条件中没有显示使用 time_series 查询时,系统将自动使用 time_series 函数进行分组。因此,这种情况下,可以使用默认值设置 TimeKey 和 TimeFormat。


