

仪表盘
监控仪表盘
管理了各个仪表盘,仪表盘的增删改查都在这里完成,全公司可能有很多仪表盘,所以仪表盘归属于各个业务组,既分门别类做了管理,又能做权限控制。仪表盘可以导出成 JSON 分享给别人,也可以导入别人分享的仪表盘,当然,也可以导入夜莺内置的仪表盘。
夜莺也支持导入 Grafana 仪表盘,不过夜莺的仪表盘和 Grafana 的仪表盘并不是兼容的,有些图表导入进来之后无法展示,如果你已经习惯了 Grafana 仪表盘,建议还是继续使用 Grafana 仪表盘。只用夜莺做告警管理,用夜莺查看基础的机器监控数据即可。
内置仪表盘
夜莺内置了一些常用的仪表盘,分门别类放在这里了。点开某个类别,可以看到相关的仪表盘列表,可以选中一批仪表盘克隆到自己的业务组下使用。采集说明 标签下面则是相关文档,讲解这类监控数据是如何采集的。
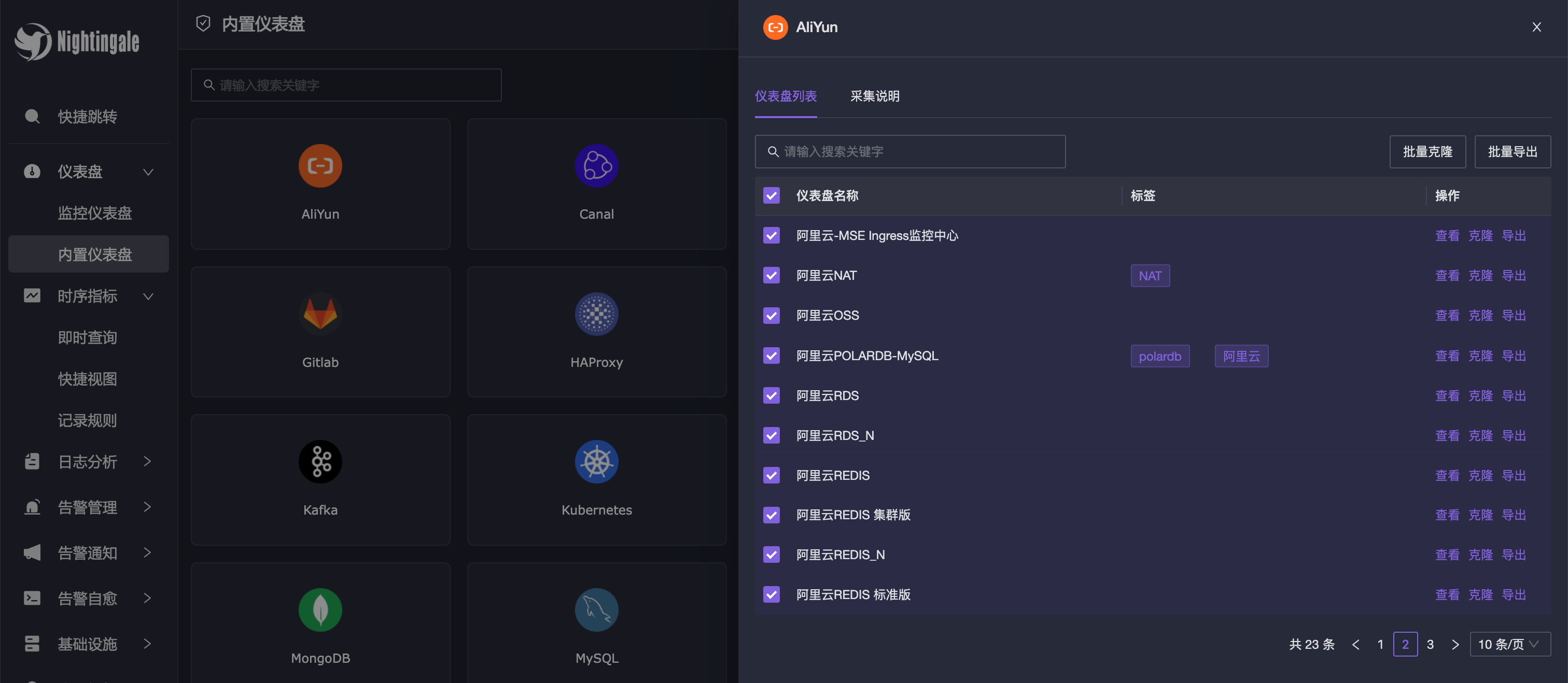
内置仪表盘实际是读取的 integrations 目录下的内容,integrations 下面每个目录就是一个类别,一般对应 Categraf 的一个采集插件,插件目录里有几个子目录,icon 存放图标图片,dashboards 存放仪表盘 JSON 文件,markdown 存放采集说明文档,alerts 存放告警规则。最新的 integrations 在这里:integrations,欢迎大家提交 PR 一起完善。
关于大盘变量
夜莺的大盘变量和 Grafana 是一样的逻辑,鉴于很多朋友实际只是会导入、查看,对原理并不清楚,这里简单介绍一下,以防遇到问题只能求助别人。
比如有这么个需求:公司有 1000 台机器,每个机器做一个大盘不现实,那就把机器这个信息作为变量,想看哪个机器的数据就在变量里选择哪个机器。下面我来演示一下如何操作,顺便说明其原理。
创建一个大盘
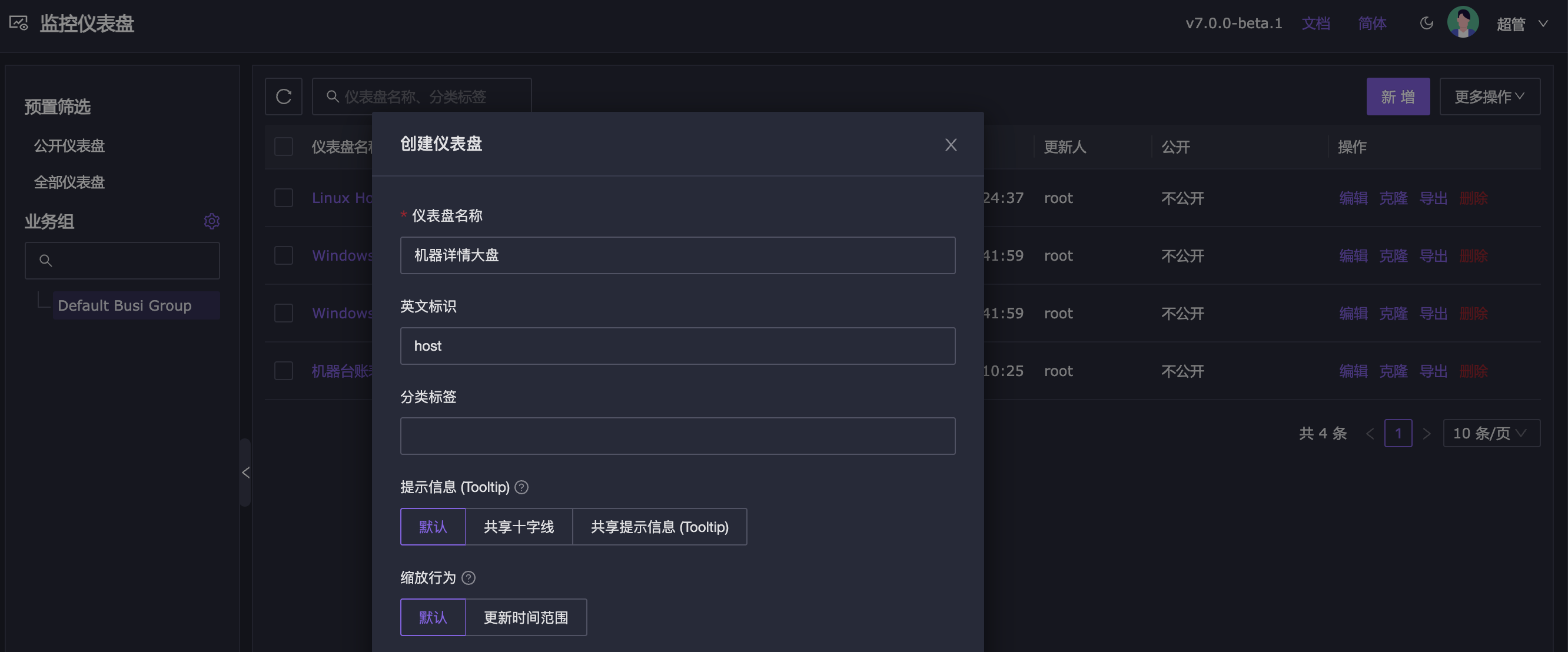
大盘名称随便命名,大盘的英文标识可以为空,如果想做大盘之间的跳转,即:在其他大盘里跳转到这个大盘,此时就建议填写英文标识。
创建完了之后点击进去,然后点即下图所示位置创建大盘变量:

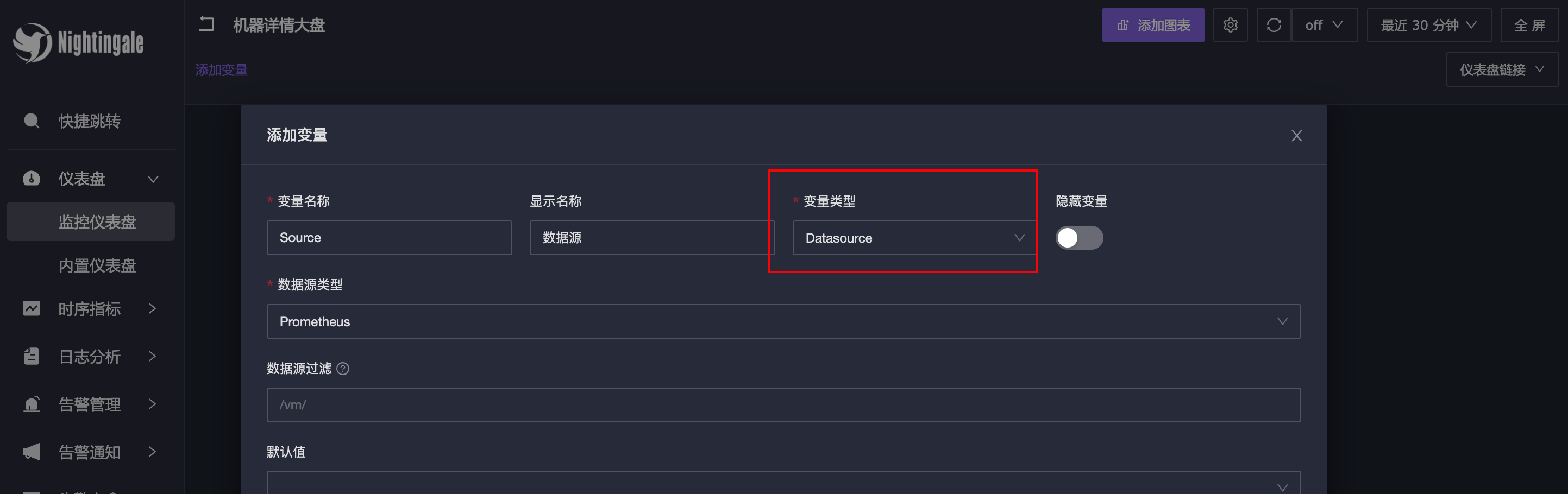
夜莺支持多个数据源,想看哪个数据源的数据,切换数据源即可,要做到这个效果,就需要把第一个变量设置为数据源变量:
第二个变量,设置为机器标识,后面我们就用这个变量来选择相关的机器:
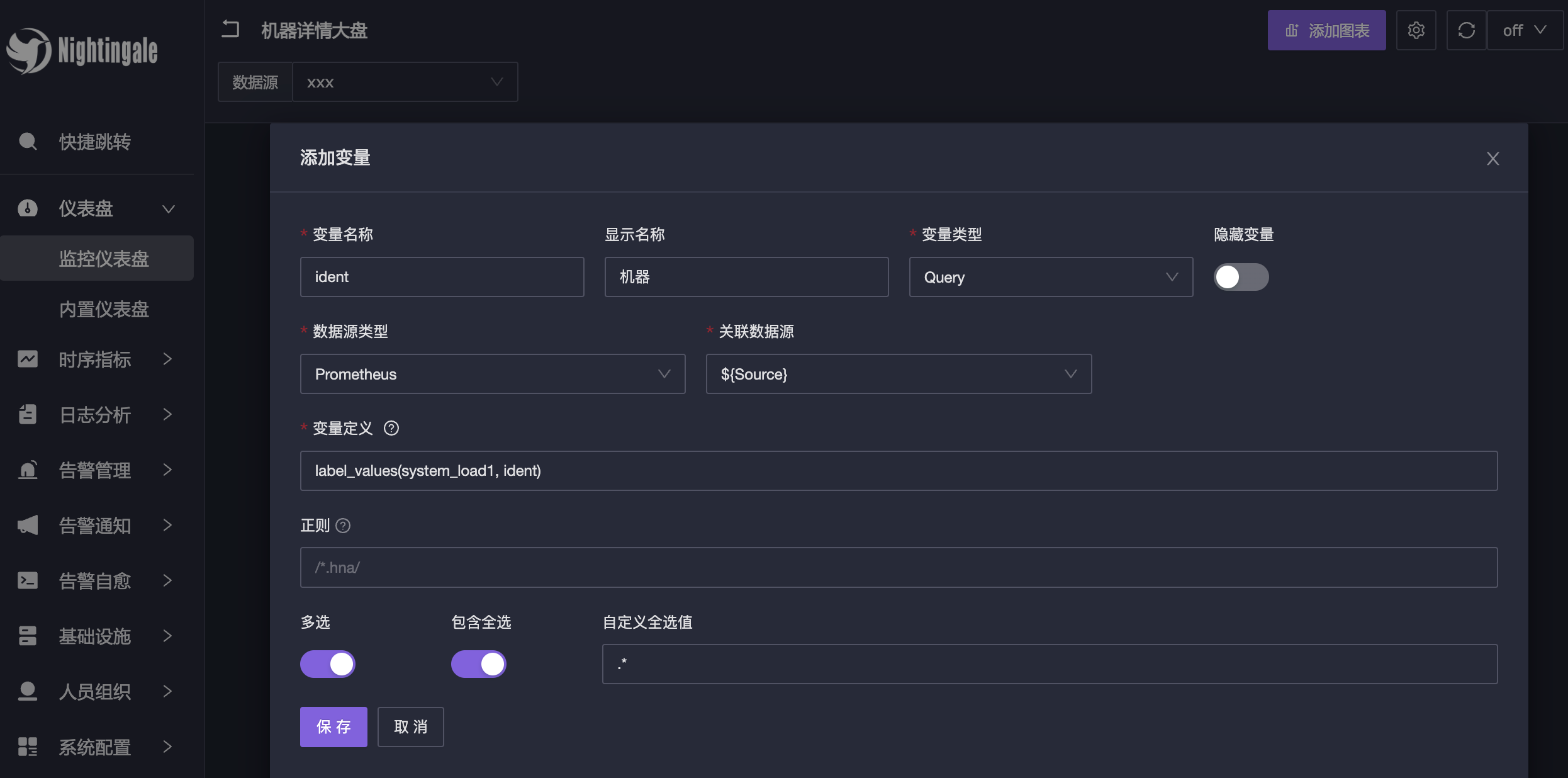
上图中几个关键选项的解释:
- 变量名称:使用英文,后面会在 promql 中引用
- 显示名称:无所谓中英文,会显示在大盘变量前面
- 变量类型:和 Grafana 类似,我这里选择 Query,可以根据 promql 查询出来的结果集来做变量
- 数据源类型:这里选择 Prometheus,因为要查询的机器列表是从 Prometheus 数据源里查询出来的
- 关联数据源:选择
${Source},引用我创建的第一个变量,数据源那个变量的值 - 变量定义:这里填写 promql,查询出机器列表,我这里是
label_values(system_load1, ident),即查询出 system_load1 这个指标的 ident 标签的值,即机器列表 - 正则:如果查询出来的机器列表太多,可以用正则来过滤,比如我这里只想看以
ulric开头的机器,就可以填^ulric.*,即正则表达式,我这里不做过滤所以为空 - 多选:如果想同时查看多个机器的数据,就勾选,后面的 promql 中引用这个变量的时候,会用
=~来引用,即正则匹配 - 包含全选:如果勾选,会在变量前面多一个
all选项,即全选所有机器
有人会问:我在某个业务组下创建了一个大盘,或导入了内置大盘,机器列表这里,为何展示的是所有机器,而不是我这个业务组下的机器?
这是因为 label_values(system_load1, ident) 是查询的时序库,查询的时序库中的 system_load1 指标,而业务组和机器的关联关系是存在数据库中的,label_values(system_load1, ident) 和数据库并没有联动。可以想办法给这个业务组下的机器打上特定的标签,然后查询的时候就可以根据这个标签来查询了。
打标签有两个方式,一个是在机器列表页面,选中一批机器,右上角有个批量操作,可以给机器批量打标签,比如批量打上 service=x 这个标签,那就可以在 promql 里查询的时候,加上 service=x 这个条件,即可根据这个标签过滤机器。写法如下:
label_values(system_load1{service="x"}, ident)
新版本的仪表盘可以直接和业务组联动,获取所属业务组下面的机器,具体如何配置,录制了一个详细视频讲解:
导入仪表盘
其实,机器详细信息的仪表盘,已经内置了,你可以导入直接使用,在仪表盘列表页面,点击右上角【更多操作】-【导入仪表盘】,如图所示:
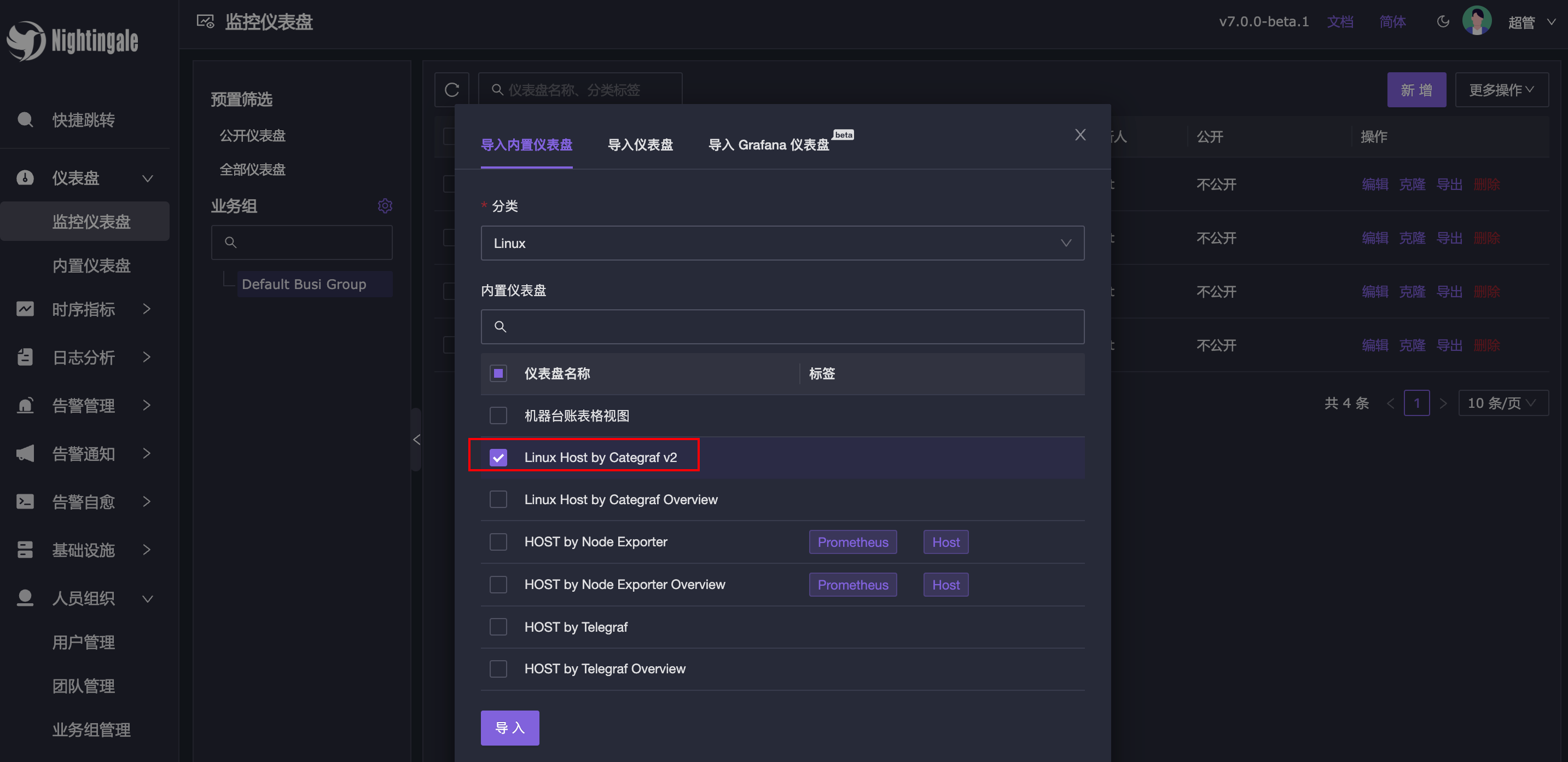
内置仪表盘的效果如下:
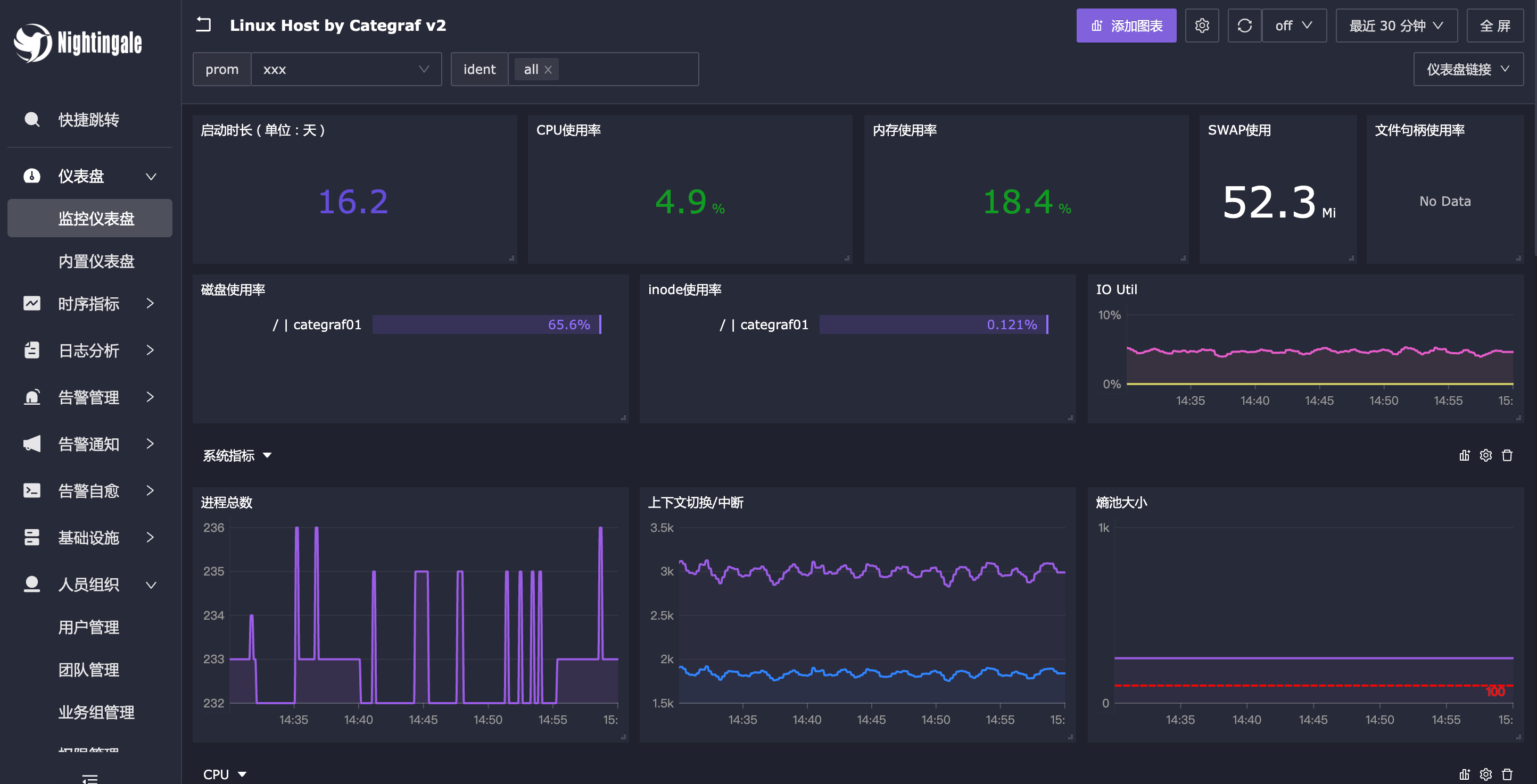
仪表盘之间串联
需求:首先弄一个全局的仪表盘,放一些 TopN 的图表,放一些全局汇总表格,这些图表里每一个元素代表一台机器,点击机器可以跳转到机器详情大盘,做到大盘之间的串联,整体是一个总分结构。
这个需求就比较高级了,而且极为有用,真正专业的监控玩家,一定会有这个诉求。下面我们就来实现这个需求。
1.导入内置的机器台账仪表盘
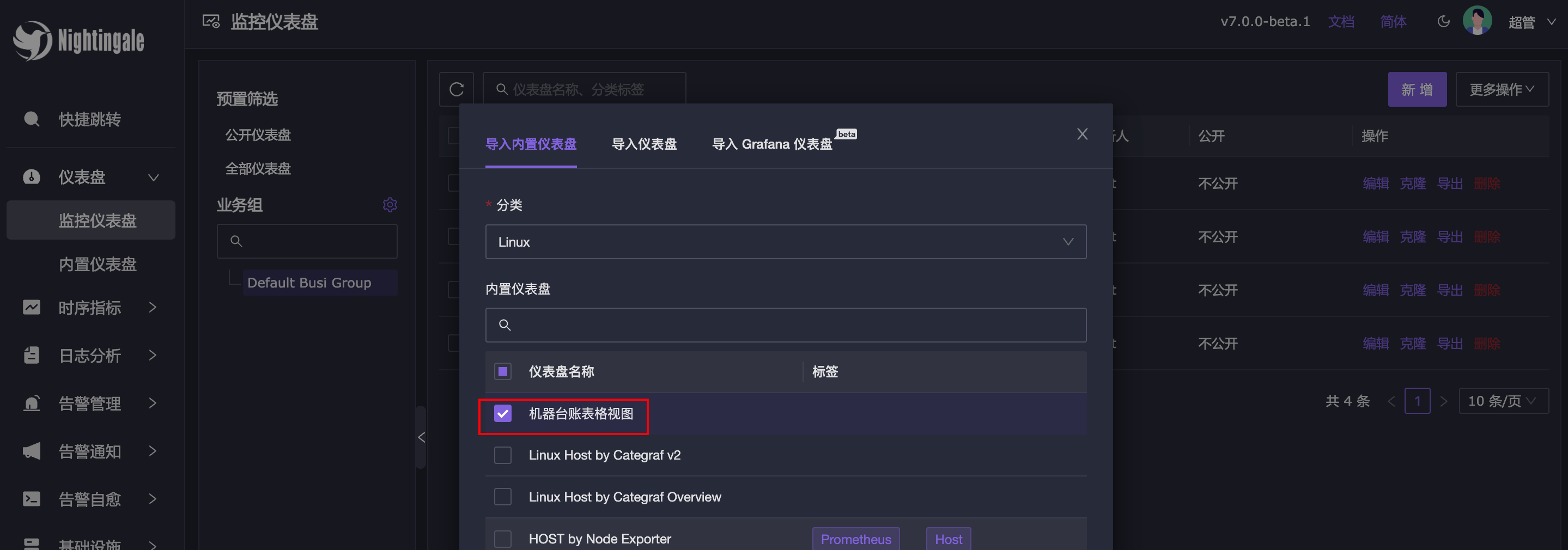
2.修改之前导入的 Linux Host by Categraf v2 仪表盘,设置其英文标识为 h
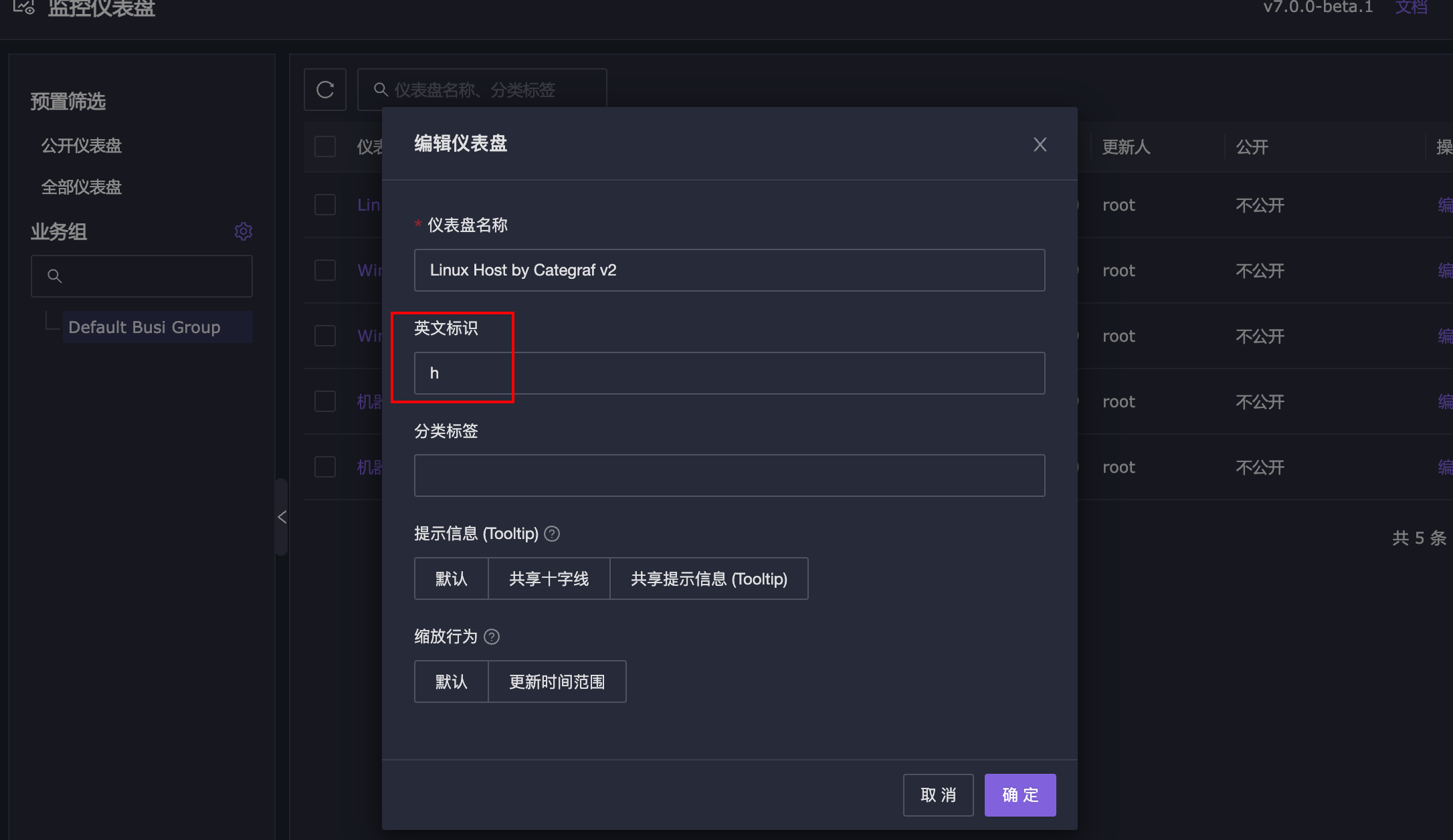
当然,你可以设置为其他的标识,不过不能跟其他的仪表盘重复,h 是 host 的第一个字符,比较短,我就用 h 了。然后打开 Linux Host by Categraf v2 这个仪表盘的详情页面,url 里类似这样:
http://10.211.55.3:17000/dashboards/h?ident=all&prom=1
注意 urlpath 和 querystring 部分,后面其他大盘要跳转过来就需要自动填充上 ident、prom 这俩参数。
3.修改机器台账表格视图这个仪表盘
这个仪表盘有三个图标,上面两个是 CPU 利用率和内存利用率,都是蜂窝图,下面一个表格。首先修改 CPU 利用率的蜂窝图:
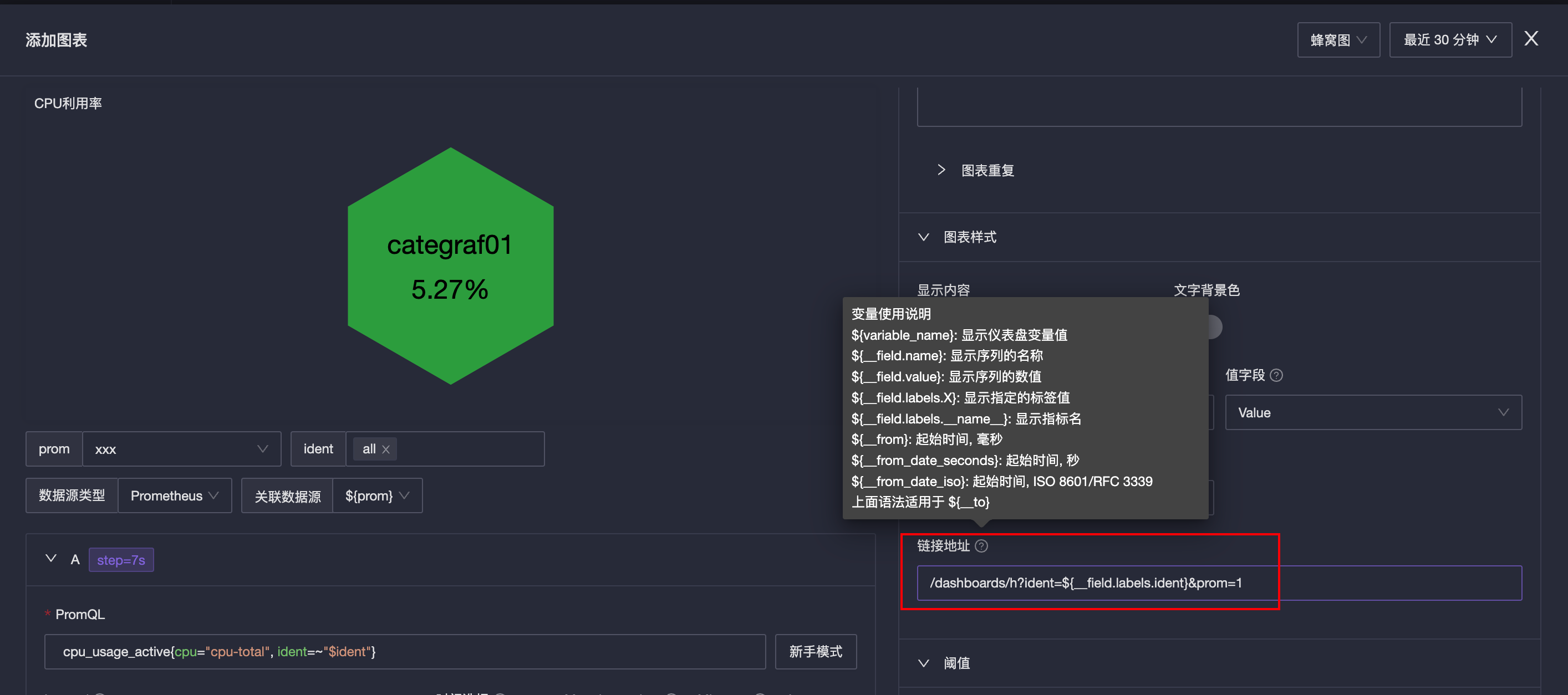
链接地址修改为:/dashboards/h?ident=${__field.labels.ident}&prom=1,这里 ident 变量是引用的 ident 标签的值,有哪些可用的变量写法,在问号那个 icon 的 tooltip 中有提示。
完事之后,点击蜂窝图中的某个机器,就能跳转到机器详情大盘了。内存利用率也是同样的配置方式。表格视图,最后面有个详情链接,编辑表格,配置一下这个详情链接的跳转方式:
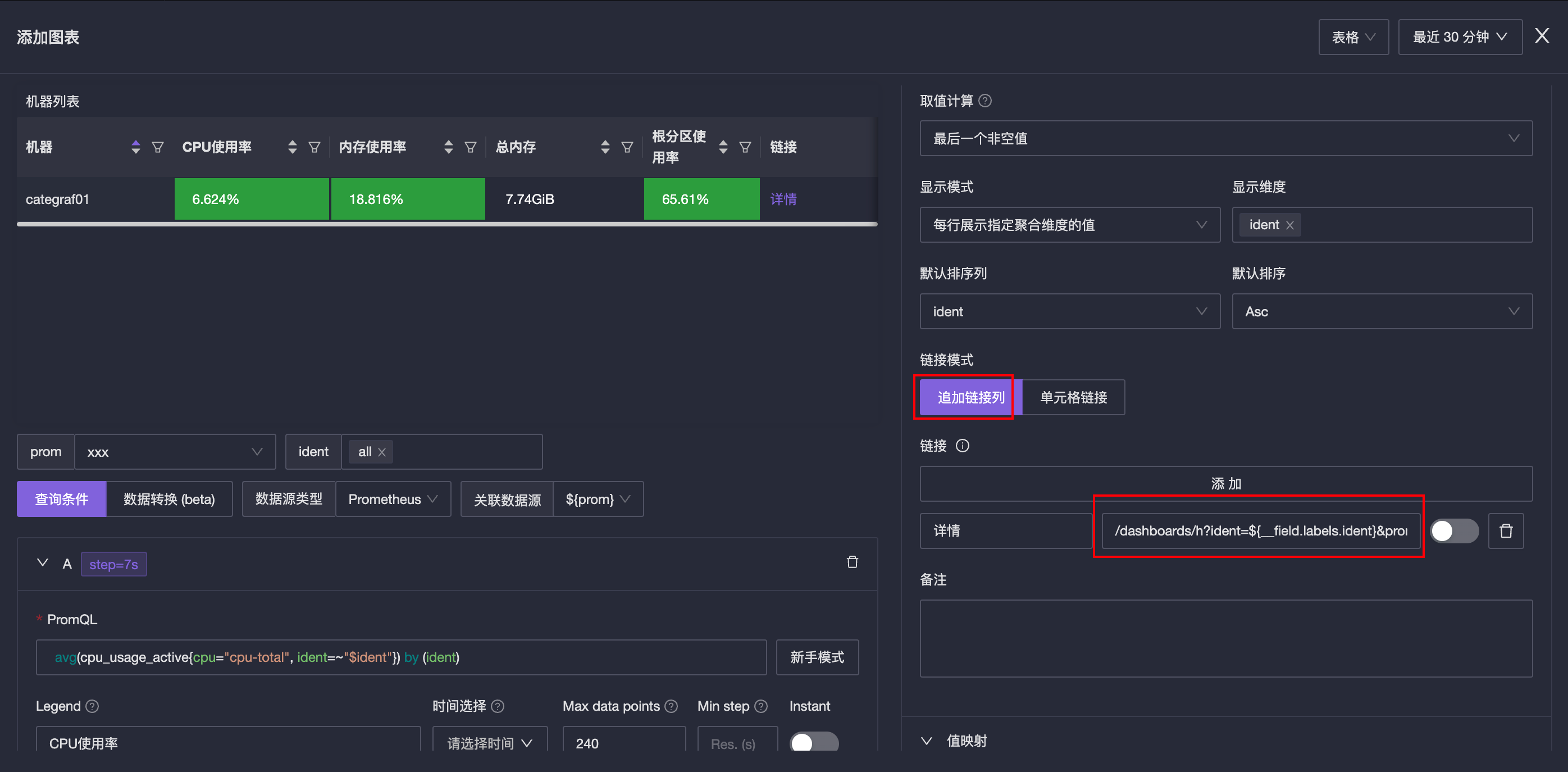
链接地址修改为:/dashboards/h?ident=${__field.labels.ident}&prom=1。
如上,是利用两个内置仪表盘演示了如何做数据串联,本质上,就是把一个仪表盘中的值作为另一个仪表盘 url 中的变量传过去。
仪表盘串联功能,请升级至:v7.0.0-beta.2 及以上版本。


